LLM Survey
1.0.0
O grande repositório de pesquisas de modelos de idiomas é um compêndio abrangente dedicado à exploração e compreensão de grandes modelos de idiomas (LLMS). Ele abriga uma variedade de recursos, incluindo trabalhos de pesquisa, postagens de blog, tutoriais, exemplos de código e muito mais para fornecer uma análise aprofundada da progressão, metodologias e aplicações do LLMS. Este repositório é um recurso inestimável para pesquisadores de IA, cientistas de dados ou entusiastas interessados nos avanços e no trabalho interno do LLMS. Incentivamos as contribuições da comunidade em geral a promover o aprendizado colaborativo e continuar ultrapassando os limites da pesquisa da LLM.
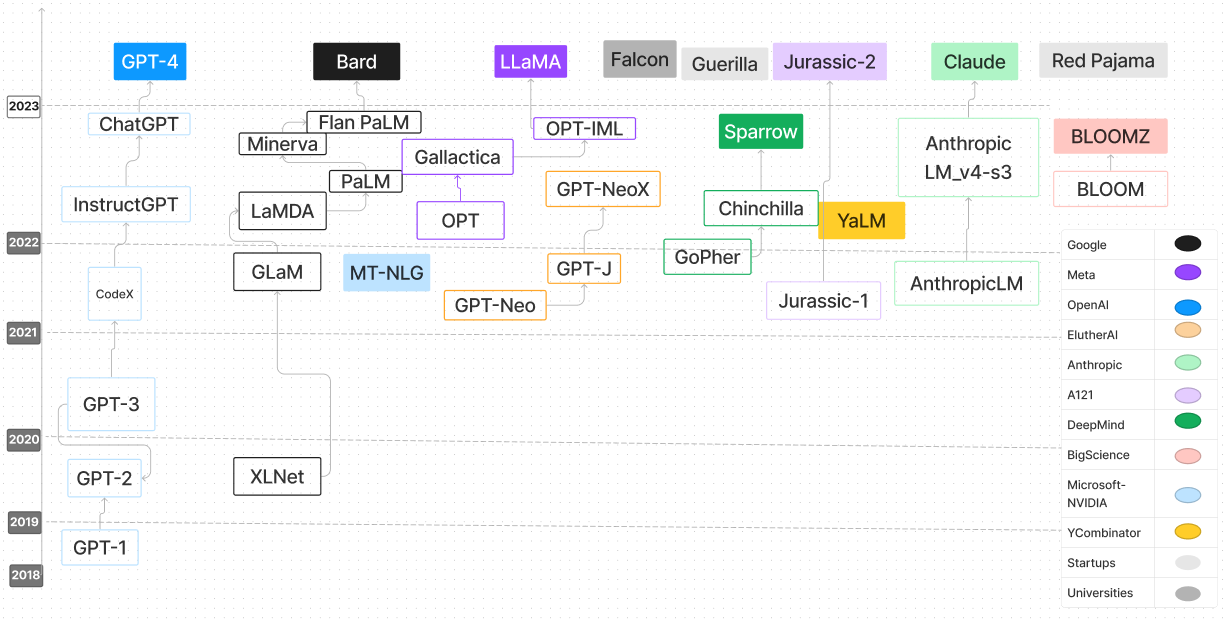
| Modelo de idioma | Data de lançamento | Pontos de verificação | Papel/blog | Params (b) | Comprimento do contexto | Licença | Experimente |
|---|---|---|---|---|---|---|---|
| T5 | 2019/10 | T5 e FLAN-T5, FLAN-T5-XXL (HF) | Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado | 0,06 - 11 | 512 | Apache 2.0 | T5-grande |
| Ul2 | 2022/10 | Ul2 e flan-ul2, flan-ul2 (HF) | Ul2 20b: um aluno de idioma unificado de código aberto | 20 | 512, 2048 | Apache 2.0 | |
| Coere | 2022/06 | Ponto de verificação | Código | 54 | 4096 | Modelo | Site |
| Cerebras-Gpt | 2023/03 | Cerebras-Gpt | Cerebras-GPT: uma família de modelos de idiomas abertos e com eficiência de computação (papel) | 0,111 - 13 | 2048 | Apache 2.0 | Cerebras-GPT-1.3b |
| Assistente aberto (família Pythia) | 2023/03 | OA-Pythia-12b-SFT-8, OA-Pythia-12b-SFT-4, OA-Pythia-12b-SFT-1 | Democratizando o grande alinhamento do modelo de linguagem | 12 | 2048 | Apache 2.0 | Pythia-2.8b |
| Pythia | 2023/04 | Pythia 70m - 12b | Pythia: uma suíte para analisar grandes modelos de idiomas em treinamento e escala | 0,07 - 12 | 2048 | Apache 2.0 | |
| Dolly | 2023/04 | Dolly-V2-12b | Dolly livre: Apresentando o primeiro LLM de instrução verdadeiramente aberto do mundo | 3, 7, 12 | 2048 | Mit | |
| Dlite | 2023/05 | dlite-v2-1_5b | Anunciando DLITE V2: LLMS LIGHTWELE | 0,124 - 1,5 | 1024 | Apache 2.0 | Dlite-v2-1.5b |
| Rwkv | 2021/08 | Rwkv, chatrwkv | O modelo de linguagem RWKV (e meus truques de LM) | 0,1 - 14 | Infinito (RNN) | Apache 2.0 | |
| GPT-J-6B | 2023/06 | GPT-J-6B, Gpt4all-J | GPT-J-6B: Transformador baseado em Jax 6B | 6 | 2048 | Apache 2.0 | |
| GPT-Neox-20b | 2022/04 | GPT-Neox-20b | GPT-Neox-20B: um modelo de linguagem autoregressiva de código aberto | 20 | 2048 | Apache 2.0 | |
| Florescer | 2022/11 | Florescer | Bloom: um modelo de linguagem multilíngue de acesso aberto de 176b-parâmetros | 176 | 2048 | OpenRail-M v1 | |
| Stablelm-alfa | 2023/04 | Stablelm-alfa | A IA de estabilidade lança o primeiro de seu conjunto Stablelm de modelos de linguagem | 3 - 65 | 4096 | CC BY-SA-4.0 | |
| FastChat-t5 | 2023/04 | FastChat-T5-3B-V1.0 | Estamos empolgados em lançar o fastchat-t5: nosso chatbot compacto e comercial! | 3 | 512 | Apache 2.0 | |
| H2OGPT | 2023/05 | H2OGPT | Construindo o melhor modelo de idioma de grande código aberto do mundo: jornada do H2O.Ai | 12 - 20 | 256 - 2048 | Apache 2.0 | |
| MPT-7B | 2023/05 | MPT-7B, MPT-7B-INSTRUCT | Apresentando MPT-7B: um novo padrão para LLMs de código aberto e utilizável comercialmente | 7 | 84k (álibi) | Apache 2.0, CC BY-SA-3.0 | |
| Pangu-σ | 2023/3 | Pangu | Modelo | 1085 | - | Modelo | Página |
| Redpajama-Incite | 2023/05 | Redpajama-Incite | Liberando a família de modelos 3B e 7B Redpajama-Incite | 3 - 7 | 2048 | Apache 2.0 | Redpajama-Incite-Instruct-3b-V1 |
| Openllama | 2023/05 | Open_llama_3b, open_llama_7b, open_llama_13b | Openllama: uma reprodução aberta de lhama | 3, 7 | 2048 | Apache 2.0 | Openllama-7b-preview_200bt |
| Falcão | 2023/05 | Falcon-180B, Falcon-40B, Falcon-7b | O conjunto de dados RefinedWeb para Falcon LLM: superando corpora com curadoria com dados da Web e apenas dados da Web | 180, 40, 7 | 2048 | Apache 2.0 | |
| MPT-30B | 2023/06 | MPT-30B, MPT-30B-INUTRUTA | MPT-30B: Aumentando o bar para modelos de fundação de código aberto | 30 | 8192 | Apache 2.0, CC BY-SA-3.0 | MPT 30B Código de inferência usando CPU |
| LLAMA 2 | 2023/06 | Lhama 2 pesos | LLAMA 2: Fundação aberta e modelos de bate-papo ajustados | 7 - 70 | 4096 | Custom Free se você tiver menos de 700 milhões de usuários e não pode usar saídas de llama para treinar outros LLMs além da llama e seus derivados | HuggingChat |
| Openlm | 2023/09 | Openlm 1b, Openlm 7b | LM aberto: um repositório mínimo, mas performativo de modelagem de idiomas (LM) | 1, 7 | 2048 | Mit | |
| Mistral 7b | 2023/09 | Mistral-7b-V0.1, Mistral-7B-Instruct-V0.1 | Mistral 7b | 7 | 4096-16k com janelas deslizantes | Apache 2.0 | Transformador Mistral |
| OpenHermes | 2023/09 | OpenHermes-7b, OpenHermes-13b | Nous Research | 7, 13 | 4096 | Mit | OpenHermes-V2 FinetUned no Mistral 7b |
| SOLAR | 2023/12 | Solar-10.7b | Upstage | 10.7 | 4096 | Apache-2.0 | |
| Phi-2 | 2023/12 | Phi-2 2,7b | Microsoft | 2.7 | 2048 | Mit | |
| Santacoder | 2023/01 | Santacoder | Santacoder: Não pegue as estrelas! | 1.1 | 2048 | OpenRail-M v1 | Santacoder |
| Starcoder | 2023/05 | Starcoder | Starcoder: Um LLM de última geração para código, Starcoder: Que a fonte esteja com você! | 1.1-15 | 8192 | OpenRail-M v1 | |
| Alfa de Starchat | 2023/05 | Starchat-Alpha | Criando um assistente de codificação com o Starcoder | 16 | 8192 | OpenRail-M v1 | |
| Código de replicação | 2023/05 | Replit-Code-V1-3b | Treinando um SOTA Code LLM em 1 semana e quantificando as vibrações - com Reza Shabani, da Replit | 2.7 | infinidade? (Álibi) | CC BY-SA-4.0 | Replit-Code-V1-3b |
| CodeGen2 | 2023/04 | CodeGen2 1B-16B | CodeGen2: Lições para o treinamento LLMS sobre programação e idiomas naturais | 1 - 16 | 2048 | Apache 2.0 | |
| Codet5+ | 2023/05 | Codet5+ | Codet5+: Código aberto modelos de idiomas para compreensão e geração de código | 0,22 - 16 | 512 | BSD-3-cláusula | Codet5+-6b |
| XGEN-7B | 2023/06 | XGEN-7B-8K-BASE | Modelagem de sequência longa com xgen: um 7b LLM treinado em comprimento de sequência de entrada de 8k | 7 | 8192 | Apache 2.0 | |
| Codegen2.5 | 2023/07 | CodeGen2.5-7b-multi | Codegen2.5: pequeno, mas poderoso | 7 | 2048 | Apache 2.0 | |
| Decicoder-1b | 2023/08 | Decicoder-1b | Apresentando Decicoder: O novo padrão -ouro em geração de código eficiente e precisa | 1.1 | 2048 | Apache 2.0 | Demo Decicoder |
| Código Llama | 2023 | Código de inferência para modelos Codellama | Código LLAMA: Modelos de base aberta para código | 7 - 34 | 4096 | Modelo | HuggingChat |
| Pardal | 2022/09 | Código de inferência | Código | 70 | 4096 | Modelo | Página da Internet |
| Mistral | 2023/09 | Código de inferência | Código | 7 | 8000 | Modelo | Página da Internet |
| Koala | 2023/04 | Código de inferência | Código | 13 | 4096 | Modelo | Página da Internet |
| Palm 2 | 2024 | N / D | Google AI | 540 | N / D | N / D | N / D |
| Tongyi Qianwen | 2024 | N / D | Cloud Alibaba | N / D | N / D | N / D | N / D |
| Comando coere | 2024 | N / D | Coere | 6 - 52 | N / D | N / D | N / D |
| Vicuna 33b | 2024 | N / D | Meta ai | 33 | N / D | N / D | N / D |
| Guanaco-65b | 2024 | N / D | Meta ai | 65 | N / D | N / D | N / D |
| Amazon q | 2024 | N / D | AWS | N / D | N / D | N / D | N / D |
| Falcon 180b | 2024 | Falcon-180B | Instituto de Inovação em Tecnologia | 180 | N / D | Apache 2.0 | N / D |
| Yi 34b | 2024 | N / D | 01 AI | 34 | Até 32k | N / D | N / D |
| Mixtral 8x7b | 2023 | Mixtral 8x 7b | Ai Mistral | 46,7 (12,9 por token) | N / D | Apache 2.0 | N / D |
Se você achar nossa pesquisa útil para sua pesquisa, cite o seguinte artigo:
@article{hadi2024large,
title={Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects},
author={Hadi, Muhammad Usman and Al Tashi, Qasem and Shah, Abbas and Qureshi, Rizwan and Muneer, Amgad and Irfan, Muhammad and Zafar, Anas and Shaikh, Muhammad Bilal and Akhtar, Naveed and Wu, Jia and others},
journal={Authorea Preprints},
year={2024},
publisher={Authorea}
}


