LLM Survey
1.0.0
大規模な言語モデル調査リポジトリは、大規模な言語モデル(LLM)の探求と理解に特化した包括的な大要です。 LLMSの進行、方法論、およびアプリケーションを詳細に調べるために、研究論文、ブログ投稿、チュートリアル、コードの例などを含むさまざまなリソースがあります。このレポは、LLMの進歩と内部の仕組みに関心のあるAI研究者、データサイエンティスト、または愛好家にとって非常に貴重なリソースです。より広いコミュニティからの貢献を奨励し、共同学習を促進し、LLM研究の境界を押し続けます。
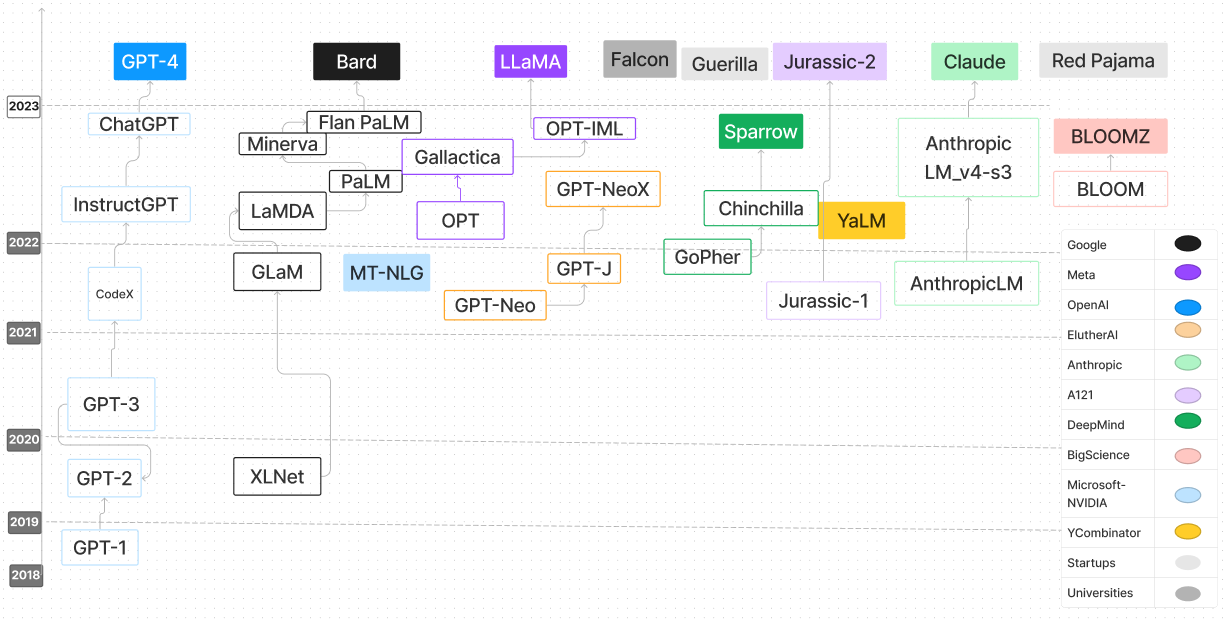
| 言語モデル | 発売日 | チェックポイント | 紙/ブログ | パラメーション(b) | コンテキストの長さ | ライセンス | 試してみてください |
|---|---|---|---|---|---|---|---|
| T5 | 2019/10 | T5&Flan-T5、Flan-T5-XXL(HF) | 統一されたテキストツーテキスト変圧器で転送学習の限界を探る | 0.06-11 | 512 | Apache 2.0 | T5-Large |
| UL2 | 2022/10 | ul2&flan-ul2、flan-ul2(hf) | UL2 20B:オープンソース統一言語学習者 | 20 | 512、2048 | Apache 2.0 | |
| 協力します | 2022/06 | チェックポイント | コード | 54 | 4096 | モデル | Webサイト |
| セレブラス-gpt | 2023/03 | セレブラス-gpt | Cerebras-Gpt:オープンで計算効率の良い、大規模な言語モデル(紙)の家族 | 0.111-13 | 2048 | Apache 2.0 | セレブラス-GPT-1.3B |
| オープンアシスタント(ピティアファミリー) | 2023/03 | OA-PTHIA-12B-SFT-8、OA-PTHIA-12B-SFT-4、OA-PTHIA-12B-SFT-1 | 大規模な言語モデルのアライメントを民主化する | 12 | 2048 | Apache 2.0 | Pythia-2.8b |
| ピティア | 2023/04 | Pythia 70m -12b | Pythia:トレーニングとスケーリング全体で大規模な言語モデルを分析するためのスイート | 0.07-12 | 2048 | Apache 2.0 | |
| ドリー | 2023/04 | Dolly-V2-12B | 無料のドリー:世界初の真に開かれた命令チューニングLLMを紹介する | 3、7、12 | 2048 | mit | |
| dlite | 2023/05 | dlite-v2-1_5b | Dlite V2の発表:どこでも実行できる軽量でオープンLLMS | 0.124-1.5 | 1024 | Apache 2.0 | dlite-v2-1.5b |
| RWKV | 2021/08 | rwkv、chatrwkv | RWKV言語モデル(および私のLMトリック) | 0.1-14 | Infinity(RNN) | Apache 2.0 | |
| GPT-J-6B | 2023/06 | gpt-j-6b、gpt4all-j | GPT-J-6B:6B JAXベースのトランス | 6 | 2048 | Apache 2.0 | |
| GPT-NEOX-20B | 2022/04 | GPT-NEOX-20B | GPT-Neox-20B:オープンソースの自己回帰言語モデル | 20 | 2048 | Apache 2.0 | |
| 咲く | 2022/11 | 咲く | Bloom:176B-Parameterオープンアクセス多言語言語モデル | 176 | 2048 | OpenRail-M V1 | |
| Stablelm-Alpha | 2023/04 | Stablelm-Alpha | StabilityAIは、言語モデルのStablelmスイートの最初のものを起動します | 3-65 | 4096 | CC by-sa-4.0 | |
| FastChat-T5 | 2023/04 | FastChat-T5-3B-V1.0 | FastChat-T5:コンパクトで商業に優しいチャットボットをリリースできることを楽しみにしています! | 3 | 512 | Apache 2.0 | |
| h2ogpt | 2023/05 | h2ogpt | 世界最高のオープンソースの大きな言語モデルを構築する:H2O.AIの旅 | 12-20 | 256-2048 | Apache 2.0 | |
| MPT-7B | 2023/05 | MPT-7B、MPT-7B-Instruct | MPT-7Bの導入:オープンソースの新しい標準、商業的に使用可能なLLMS | 7 | 84k(alibi) | Apache 2.0、CC by-sa-3.0 | |
| パンσ | 2023/3 | パン | モデル | 1085 | - | モデル | ページ |
| redpajama-incite | 2023/05 | redpajama-incite | ベース、命令チューニング、チャットモデルを含むモデルの3Bおよび7Bのレッドパジャマがインクのあるモデルファミリをリリースする | 3-7 | 2048 | Apache 2.0 | redpajama-incite-instruct-3b-v1 |
| Openllama | 2023/05 | Open_llama_3b、open_llama_7b、open_llama_13b | Openllama:Llamaのオープンな複製 | 3、7 | 2048 | Apache 2.0 | Openllama-7b-preview_200bt |
| ファルコン | 2023/05 | FALCON-180B、FALCON-40B、FALCON-7B | Falcon LLMのRefinedWebデータセット:WebデータとWebデータのみを使用してキュレーションされたコーパスを上回る | 180、40、7 | 2048 | Apache 2.0 | |
| MPT-30B | 2023/06 | MPT-30B、MPT-30B-Instruct | MPT-30B:オープンソースファンデーションモデルのバーを上げる | 30 | 8192 | Apache 2.0、CC by-sa-3.0 | CPUを使用したMPT 30B推論コード |
| ラマ2 | 2023/06 | ラマ2ウェイト | Llama 2:オープンファンデーションと微調整されたチャットモデル | 7-70 | 4096 | 700m未満のユーザーがいて、llama出力を使用してラマとその導関数以外のLLMをトレーニングできない場合はカスタムフリー | Huggingchat |
| openlm | 2023/09 | openlm 1b、openlm 7b | Open LM:最小限であるがパフォーマンスのある言語モデリング(LM)リポジトリ | 1、7 | 2048 | mit | |
| ミストラル7b | 2023/09 | Mistral-7B-V0.1、Mistral-7B-Instruct-V0.1 | ミストラル7b | 7 | スライディングウィンドウを備えた4096-16K | Apache 2.0 | ミストラルトランス |
| OpenHermes | 2023/09 | OpenHermes-7B、OpenHermes-13B | Nous Research | 7、13 | 4096 | mit | Mistral 7bでFinetuned openhermes-v2 |
| 太陽 | 2023/12 | ソーラー10.7b | 舞台上 | 10.7 | 4096 | Apache-2.0 | |
| PHI-2 | 2023/12 | PHI-2 2.7b | マイクロソフト | 2.7 | 2048 | mit | |
| サンタコーダー | 2023/01 | サンタコーダー | サンタコーダー:星に手を伸ばさないでください! | 1.1 | 2048 | OpenRail-M V1 | サンタコーダー |
| スターコダー | 2023/05 | スターコダー | Starcoder:コード用の最先端のLLM、Starcoder:ソースがあなたと一緒にいることがあります! | 1.1-15 | 8192 | OpenRail-M V1 | |
| Starchat Alpha | 2023/05 | STARCHAT-ALPHA | StarCoderを使用してコーディングアシスタントを作成します | 16 | 8192 | OpenRail-M V1 | |
| コードを返信します | 2023/05 | REPLIT-CODE-V1-3B | SOTAコードLLMを1週間でトレーニングし、バイブの定量化 - Reza Shabaniのレプリットを使用して | 2.7 | 無限? (アリバイ) | CC by-sa-4.0 | REPLIT-CODE-V1-3B |
| codegen2 | 2023/04 | CodeGen2 1B-16B | CodeGen2:プログラミングと自然言語に関するLLMSをトレーニングするためのレッスン | 1-16 | 2048 | Apache 2.0 | |
| Codet5+ | 2023/05 | Codet5+ | Codet5+:コードの理解と生成のためのコード大規模言語モデルをオープン | 0.22-16 | 512 | BSD-3節 | Codet5+-6b |
| xgen-7b | 2023/06 | XGEN-7B-8Kベース | XGENを使用した長いシーケンスモデリング:8K入力シーケンス長でトレーニングされた7B LLM | 7 | 8192 | Apache 2.0 | |
| CodeGen2.5 | 2023/07 | CodeGen2.5-7B-Multi | CodeGen2.5:小さくても強力です | 7 | 2048 | Apache 2.0 | |
| デシコーダー-1B | 2023/08 | デシコーダー-1B | デシコーダーの紹介:効率的で正確なコード生成の新しいゴールドスタンダード | 1.1 | 2048 | Apache 2.0 | デシコーダーデモ |
| コードラマ | 2023 | Codellamaモデルの推論コード | コードラマ:コードのファンデーションモデルを開きます | 7-34 | 4096 | モデル | Huggingchat |
| スズメ | 2022/09 | 推論コード | コード | 70 | 4096 | モデル | ウェブページ |
| ミストラル | 2023/09 | 推論コード | コード | 7 | 8000 | モデル | ウェブページ |
| コアラ | 2023/04 | 推論コード | コード | 13 | 4096 | モデル | ウェブページ |
| 手のひら2 | 2024 | n/a | Google AI | 540 | n/a | n/a | n/a |
| Tongyi Qianwen | 2024 | n/a | アリババクラウド | n/a | n/a | n/a | n/a |
| Cohere Command | 2024 | n/a | 協力します | 6-52 | n/a | n/a | n/a |
| Vicuna 33b | 2024 | n/a | メタAI | 33 | n/a | n/a | n/a |
| グアナコ-65b | 2024 | n/a | メタAI | 65 | n/a | n/a | n/a |
| Amazon Q | 2024 | n/a | aws | n/a | n/a | n/a | n/a |
| ファルコン180b | 2024 | Falcon-180b | Technology Innovation Institute | 180 | n/a | Apache 2.0 | n/a |
| yi 34b | 2024 | n/a | 01 ai | 34 | 最大32k | n/a | n/a |
| Mixtral 8x7b | 2023 | Mixtral 8x 7b | ミストラルAI | 46.7(トークンあたり12.9) | n/a | Apache 2.0 | n/a |
調査に役立つ場合は、次の論文を引用してください。
@article{hadi2024large,
title={Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects},
author={Hadi, Muhammad Usman and Al Tashi, Qasem and Shah, Abbas and Qureshi, Rizwan and Muneer, Amgad and Irfan, Muhammad and Zafar, Anas and Shaikh, Muhammad Bilal and Akhtar, Naveed and Wu, Jia and others},
journal={Authorea Preprints},
year={2024},
publisher={Authorea}
}


