LLM Survey
1.0.0
大型语言模型调查存储库是一项全面的汇编,该汇编专门用于探索和理解大语言模型(LLMS)。它包含各种资源,包括研究论文,博客文章,教程,代码示例等,以深入了解LLMS的进步,方法和应用。对于AI研究人员,数据科学家或对LLMS的进步和内部运作感兴趣的AI研究人员,数据科学家或爱好者来说,此存储库是宝贵的资源。我们鼓励更广泛的社区的贡献促进协作学习,并继续推动LLM研究的界限。
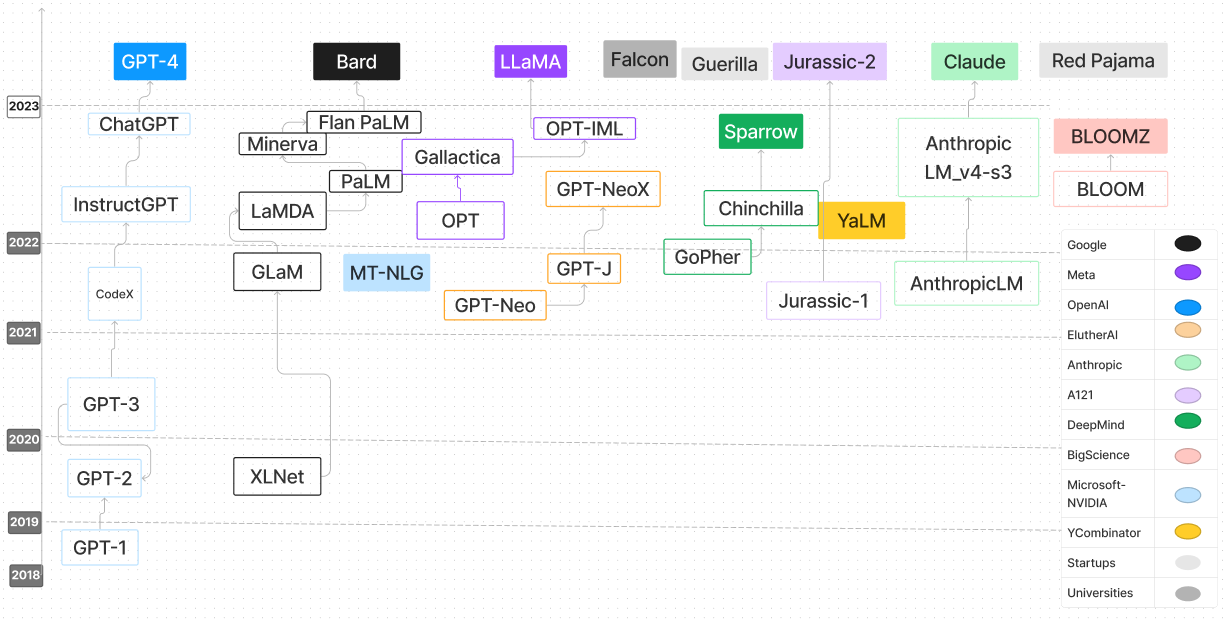
| 语言模型 | 发布日期 | 检查点 | 纸/博客 | 参数(b) | 上下文长度 | 执照 | 尝试一下 |
|---|---|---|---|---|---|---|---|
| T5 | 2019/10 | T5&Flan-T5,Flan-T5-XXL(HF) | 使用统一的文本到文本变压器探索转移学习的限制 | 0.06-11 | 512 | Apache 2.0 | t5大 |
| UL2 | 2022/10 | UL2和Flan-UL2,Flan-UL2(HF) | UL2 20B:开源统一语言学习者 | 20 | 512,2048 | Apache 2.0 | |
| 共同 | 2022/06 | 检查点 | 代码 | 54 | 4096 | 模型 | 网站 |
| 小脑-GPT | 2023/03 | 小脑-GPT | 小脑-GPT:一个开放,计算效率,大语言模型(纸)的家族 | 0.111-13 | 2048 | Apache 2.0 | 小脑-GPT-1.3B |
| 开放助理(腓出家族) | 2023/03 | OA-PYTHIA-12B-SFT-8,OA-PYTHIA-12B-SFT-4,OA-PYTHIA-12B-SFT-1 | 使大语模型的民主化 | 12 | 2048 | Apache 2.0 | 毕田2.8B |
| 毕田 | 2023/04 | 腓出70m -12b | 腓热:一套用于分析跨培训和扩展的大型语言模型的套件 | 0.07-12 | 2048 | Apache 2.0 | |
| 多莉 | 2023/04 | Dolly-V2-12b | 免费Dolly:介绍世界上第一个真正的开放指导调整的LLM | 3、7、12 | 2048 | 麻省理工学院 | |
| dlite | 2023/05 | dlite-v2-1_5b | 宣布dlite v2:轻巧,可以在任何地方运行的LLM | 0.124-1.5 | 1024 | Apache 2.0 | dlite-v2-1.5b |
| RWKV | 2021/08 | rwkv,chatrwkv | RWKV语言模型(和我的LM技巧) | 0.1-14 | 无穷大(RNN) | Apache 2.0 | |
| GPT-J-6B | 2023/06 | GPT-J-6B,GPT4All-J | GPT-J-6B:基于JAX的6B变压器 | 6 | 2048 | Apache 2.0 | |
| GPT-Neox-20b | 2022/04 | GPT-Neox-20b | GPT-NEOX-20B:开源自回归语言模型 | 20 | 2048 | Apache 2.0 | |
| 盛开 | 2022/11 | 盛开 | Bloom:176B参数开放式多语言模型 | 176 | 2048 | OpenRail-M V1 | |
| Stablelm-Alpha | 2023/04 | Stablelm-Alpha | 稳定性AI启动了其第一个语言模型的Stablelm套件 | 3-65 | 4096 | CC BY-SA-4.0 | |
| FastChat-T5 | 2023/04 | fastchat-t5-3b-v1.0 | 我们很高兴发布FastChat-T5:我们的紧凑型友好型聊天机器人! | 3 | 512 | Apache 2.0 | |
| H2ogpt | 2023/05 | H2ogpt | 建立世界上最好的开源大语言模型:H2O.AI的旅程 | 12-20 | 256-2048 | Apache 2.0 | |
| MPT-7B | 2023/05 | MPT-7B,MPT-7B教学 | 介绍MPT-7B:开源,商业可用LLM的新标准 | 7 | 84K(alibi) | Apache 2.0,CC BY-SA-3.0 | |
| pangu-σ | 2023/3 | pangu | 模型 | 1085 | - | 模型 | 页 |
| redpajama-结构 | 2023/05 | redpajama-结构 | 释放3B和7B Redpajama-结构模型家族,包括基本,指导调整和聊天模型 | 3-7 | 2048 | Apache 2.0 | redpajama-Incite-Instruct-3b-v1 |
| Ottinllama | 2023/05 | open_llama_3b,open_llama_7b,open_llama_13b | Openllama:骆驼的开放繁殖 | 3,7 | 2048 | Apache 2.0 | optlllama-7b-preview_200bt |
| 鹘 | 2023/05 | Falcon-180B,Falcon-40B,Falcon-7b | Falcon LLM的精制网络数据集:仅具有Web数据的策划的Corpora和Web数据 | 180、40、7 | 2048 | Apache 2.0 | |
| MPT-30B | 2023/06 | MPT-30B,MPT-30B教学 | MPT-30B:提高开源基础模型的标准 | 30 | 8192 | Apache 2.0,CC BY-SA-3.0 | MPT 30B推理代码使用CPU |
| 美洲驼2 | 2023/06 | 骆驼2个权重 | 骆驼2:开放基础和微调聊天模型 | 7-70 | 4096 | 自定义免费,如果您的用户不到7亿用户,并且除了Llama及其衍生品外,也无法使用Llama输出来培训其他LLM | 拥抱 |
| OpenLM | 2023/09 | OpenLM 1B,OpenLM 7B | 开放LM:最少但表现性的语言建模(LM)存储库 | 1,7 | 2048 | 麻省理工学院 | |
| Mistral 7b | 2023/09 | MISTRAL-7B-V0.1,MISTRAL-7B-INSTRUCT-V0.1 | Mistral 7b | 7 | 4096-16k带滑动窗口 | Apache 2.0 | Mistral Transformer |
| OpenHermes | 2023/09 | OpenHermes-7b,OpenHermes-13b | 研究 | 7,13 | 4096 | 麻省理工学院 | 在Mistral 7b上进行的OpenHermes-V2固定 |
| 太阳的 | 2023/12 | Solar-10.7b | 上升 | 10.7 | 4096 | Apache-2.0 | |
| PHI-2 | 2023/12 | PHI-2 2.7b | 微软 | 2.7 | 2048 | 麻省理工学院 | |
| Santacoder | 2023/01 | Santacoder | Santacoder:不要伸手去拿星星! | 1.1 | 2048 | OpenRail-M V1 | Santacoder |
| Starcoder | 2023/05 | Starcoder | StarCoder:代码的最先进的LLM,StarCoder:愿来源与您同在! | 1.1-15 | 8192 | OpenRail-M V1 | |
| Starchat Alpha | 2023/05 | Starchat-Alpha | 用Starcoder创建编码助手 | 16 | 8192 | OpenRail-M V1 | |
| 补充代码 | 2023/05 | REPLIT-CODE-V1-3B | 在1周内培训SOTA Code LLM并量化氛围 | 2.7 | 无限? (alibi) | CC BY-SA-4.0 | REPLIT-CODE-V1-3B |
| CodeGen2 | 2023/04 | CodeGen2 1b-16b | CodeGen2:用于编程和自然语言的培训LLM的课程 | 1-16 | 2048 | Apache 2.0 | |
| codet5+ | 2023/05 | codet5+ | CODET5+:打开代码大型语言模型,用于代码理解和生成 | 0.22-16 | 512 | BSD-3-C-sause | codet5+-6b |
| XGEN-7B | 2023/06 | XGEN-7B-8K基础 | 使用XGEN的长序列建模:在8K输入序列长度上训练的7B LLM | 7 | 8192 | Apache 2.0 | |
| CodeGen2.5 | 2023/07 | CodeGen2.5-7B-Multi | Codegen2.5:小,但强大 | 7 | 2048 | Apache 2.0 | |
| DICODER-1B | 2023/08 | DICODER-1B | 介绍Decicoder:高效,准确代码生成的新黄金标准 | 1.1 | 2048 | Apache 2.0 | DECICODER演示 |
| 代码骆驼 | 2023 | Codellama模型的推理代码 | 代码骆驼:代码的开放基础模型 | 7-34 | 4096 | 模型 | 拥抱 |
| 麻雀 | 2022/09 | 推理代码 | 代码 | 70 | 4096 | 模型 | 网页 |
| Mistral | 2023/09 | 推理代码 | 代码 | 7 | 8000 | 模型 | 网页 |
| 考拉 | 2023/04 | 推理代码 | 代码 | 13 | 4096 | 模型 | 网页 |
| 棕榈2 | 2024 | N/A。 | Google AI | 540 | N/A。 | N/A。 | N/A。 |
| Tongyi Qianwen | 2024 | N/A。 | 阿里巴巴云 | N/A。 | N/A。 | N/A。 | N/A。 |
| cohere命令 | 2024 | N/A。 | 共同 | 6-52 | N/A。 | N/A。 | N/A。 |
| Vicuna 33b | 2024 | N/A。 | meta ai | 33 | N/A。 | N/A。 | N/A。 |
| 瓜纳科65B | 2024 | N/A。 | meta ai | 65 | N/A。 | N/A。 | N/A。 |
| 亚马逊Q | 2024 | N/A。 | AWS | N/A。 | N/A。 | N/A。 | N/A。 |
| 猎鹰180b | 2024 | Falcon-180b | 技术创新研究所 | 180 | N/A。 | Apache 2.0 | N/A。 |
| yi 34b | 2024 | N/A。 | 01 AI | 34 | 最多32K | N/A。 | N/A。 |
| 混合8x7b | 2023 | 混合8x 7b | Mistral AI | 46.7(每个令牌12.9) | N/A。 | Apache 2.0 | N/A。 |
如果您发现我们的调查对您的研究有用,请引用以下论文:
@article{hadi2024large,
title={Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects},
author={Hadi, Muhammad Usman and Al Tashi, Qasem and Shah, Abbas and Qureshi, Rizwan and Muneer, Amgad and Irfan, Muhammad and Zafar, Anas and Shaikh, Muhammad Bilal and Akhtar, Naveed and Wu, Jia and others},
journal={Authorea Preprints},
year={2024},
publisher={Authorea}
}


