LLM Survey
1.0.0
Repositori survei model bahasa besar adalah ringkasan komprehensif yang didedikasikan untuk eksplorasi dan pemahaman model bahasa besar (LLM). Ini menampung berbagai macam sumber daya termasuk makalah penelitian, posting blog, tutorial, contoh kode, dan banyak lagi untuk memberikan pandangan mendalam pada perkembangan, metodologi, dan aplikasi LLM. Repo ini adalah sumber daya yang sangat berharga bagi para peneliti AI, ilmuwan data, atau penggemar yang tertarik pada kemajuan dan cara kerja batin LLMS. Kami mendorong kontribusi dari komunitas yang lebih luas untuk mempromosikan pembelajaran kolaboratif dan terus mendorong batas -batas penelitian LLM.
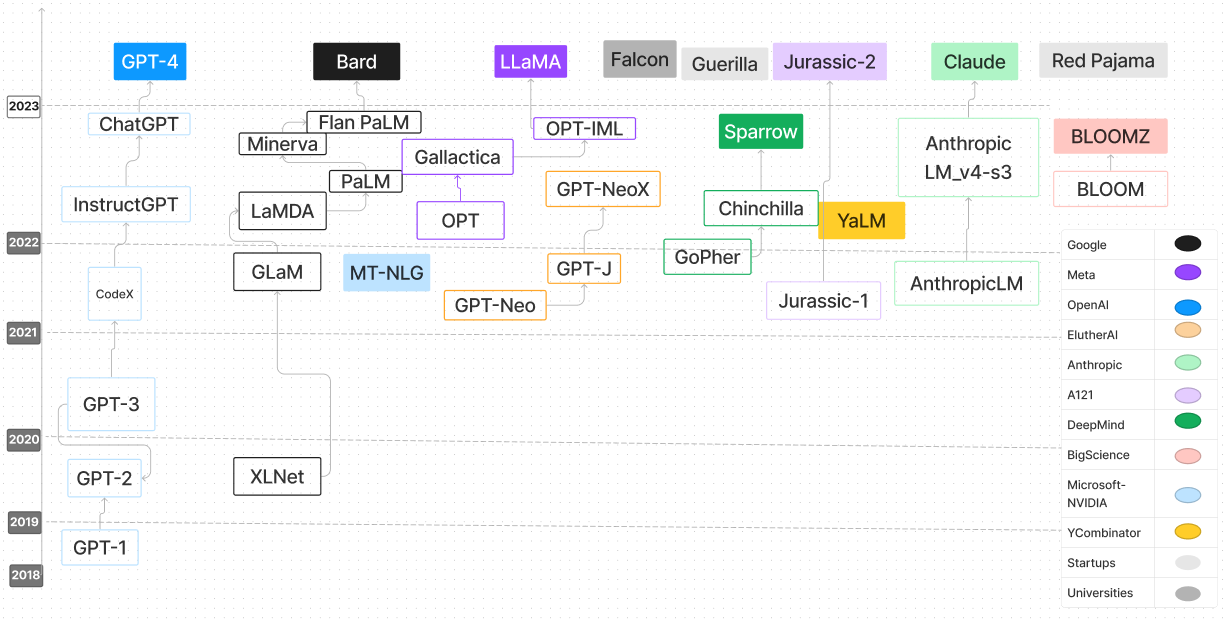
| Model Bahasa | Tanggal rilis | Pos pemeriksaan | Kertas/blog | Params (b) | Panjang konteks | Lisensi | Cobalah |
|---|---|---|---|---|---|---|---|
| T5 | 2019/10 | T5 & Flan-T5, Flan-T5-XXL (HF) | Menjelajahi Batas Pembelajaran Transfer dengan Transformator Teks ke Teks Terpadu | 0,06 - 11 | 512 | Apache 2.0 | T5-Large |
| UL2 | 2022/10 | UL2 & Flan-Ul2, Flan-Ul2 (HF) | UL2 20B: Pembelajar Bahasa Terpadu Sumber Terbuka | 20 | 512, 2048 | Apache 2.0 | |
| Berpadu | 2022/06 | Pos pemeriksaan | Kode | 54 | 4096 | Model | Situs web |
| Cerebras-gpt | 2023/03 | Cerebras-gpt | Cerebras-GPT: Keluarga model bahasa yang terbuka, efisien, dan besar (kertas) | 0.111 - 13 | 2048 | Apache 2.0 | Cerebras-gpt-1.3b |
| Asisten Terbuka (Keluarga Pythia) | 2023/03 | OA-Pythia-12b-SFT-8, OA-Pythia-12b-SFT-4, OA-Pythia-12b-Sft-1 | Mendemokratisasi penyelarasan model bahasa besar | 12 | 2048 | Apache 2.0 | Pythia-2.8b |
| Pythia | 2023/04 | Pythia 70m - 12b | Pythia: Suite untuk menganalisis model bahasa besar di seluruh pelatihan dan penskalaan | 0,07 - 12 | 2048 | Apache 2.0 | |
| Boneka | 2023/04 | Dolly-V2-12B | Gratis Dolly: Memperkenalkan LLM yang benar-benar terbuka di dunia yang benar-benar terbuka | 3, 7, 12 | 2048 | Mit | |
| Dlite | 2023/05 | Dlite-V2-1_5B | Mengumumkan Dlite V2: Ringan, terbuka LLMS yang dapat berjalan di mana saja | 0.124 - 1.5 | 1024 | Apache 2.0 | Dlite-V2-1.5B |
| Rwkv | 2021/08 | Rwkv, chatrwkv | Model Bahasa RWKV (dan trik LM saya) | 0,1 - 14 | Infinity (RNN) | Apache 2.0 | |
| GPT-J-6B | 2023/06 | GPT-J-6B, GPT4ALL-J | GPT-J-6B: Transformator berbasis 6B JAX | 6 | 2048 | Apache 2.0 | |
| GPT-NEOX-20B | 2022/04 | GPT-NEOX-20B | GPT-NEOX-20B: Model Bahasa Autoregresif Sumber Terbuka | 20 | 2048 | Apache 2.0 | |
| Bunga | 2022/11 | Bunga | BLOOM: Model bahasa multibahasa akses-parameter 176b-parameter | 176 | 2048 | OpenRail-M V1 | |
| Stablelm-Alpha | 2023/04 | Stablelm-Alpha | Stabilitas AI meluncurkan rangkaian model bahasa yang pertama | 3 - 65 | 4096 | CC BY-SA-4.0 | |
| Fastchat-t5 | 2023/04 | Fastchat-T5-3B-V1.0 | Kami sangat senang merilis Fastchat-T5: Chatbot yang kompak dan ramah komersial! | 3 | 512 | Apache 2.0 | |
| h2ogpt | 2023/05 | h2ogpt | Membangun Model Bahasa Terbaik Sumber Terbaik Dunia: Perjalanan H2O.AI | 12 - 20 | 256 - 2048 | Apache 2.0 | |
| MPT-7B | 2023/05 | MPT-7B, MPT-7B-Instruksi | Memperkenalkan MPT-7B: Standar baru untuk LLMS open-source, yang dapat digunakan secara komersial | 7 | 84k (alibi) | Apache 2.0, CC BY-SA-3.0 | |
| Pangu-σ | 2023/3 | Pangu | Model | 1085 | - | Model | Halaman |
| Redpajama-incite | 2023/05 | Redpajama-incite | Melepaskan 3B dan 7B Redpajama-Incite Family of Models termasuk Model Pangkalan, Instruksi-Tuned & Obrolan | 3 - 7 | 2048 | Apache 2.0 | Redpajama-incite-instruct-3b-v1 |
| Openllama | 2023/05 | open_llama_3b, open_llama_7b, open_llama_13b | Openllama: Reproduksi Terbuka Llama | 3, 7 | 2048 | Apache 2.0 | OpenLlama-7B-Preview_200bt |
| Elang | 2023/05 | Falcon-180b, Falcon-40b, Falcon-7b | Dataset RefinedWeb untuk Falcon LLM: Mengungguli Korpor Kurator dengan Data Web, dan Data Web saja | 180, 40, 7 | 2048 | Apache 2.0 | |
| MPT-30B | 2023/06 | MPT-30B, MPT-30B-Instruksi | MPT-30B: Meningkatkan Bar untuk Model Yayasan Sumber Terbuka | 30 | 8192 | Apache 2.0, CC BY-SA-3.0 | Kode inferensi MPT 30B menggunakan CPU |
| Llama 2 | 2023/06 | Llama 2 bobot | Llama 2: Open Foundation and Fine-Tuned Chat Model | 7 - 70 | 4096 | Gratis Kustom Jika Anda memiliki di bawah 700m pengguna dan Anda tidak dapat menggunakan output LLAMA untuk melatih LLM lain selain LLAMA dan turunannya | Huggingchat |
| Openlm | 2023/09 | OpenLM 1B, OpenLM 7B | Buka LM: Repositori Pemodelan Bahasa Minimal tetapi Performatif (LM) | 1, 7 | 2048 | Mit | |
| Mistral 7B | 2023/09 | MISTRAL-7B-V0.1, MISTRAL-7B-INSTRUCT-V0.1 | Mistral 7B | 7 | 4096-16K dengan jendela geser | Apache 2.0 | Transformator Mistral |
| OpenHermes | 2023/09 | OpenHermes-7B, OpenHermes-13b | Penelitian nous | 7, 13 | 4096 | Mit | OpenHermes-V2 Finetuned di Mistral 7B |
| TENAGA SURYA | 2023/12 | Solar-10.7b | Memperlakukan dgn kasar | 10.7 | 4096 | Apache-2.0 | |
| Phi-2 | 2023/12 | Phi-2 2.7b | Microsoft | 2.7 | 2048 | Mit | |
| Santacoder | 2023/01 | Santacoder | Santacoder: Jangan meraih bintang -bintang! | 1.1 | 2048 | OpenRail-M V1 | Santacoder |
| Starcoder | 2023/05 | Starcoder | Starcoder: LLM canggih untuk kode, Starcoder: Semoga sumbernya bersama Anda! | 1.1-15 | 8192 | OpenRail-M V1 | |
| Starchat Alpha | 2023/05 | Starchat-Alpha | Membuat asisten pengkodean dengan starcoder | 16 | 8192 | OpenRail-M V1 | |
| Kode Replit | 2023/05 | Repit-Code-V1-3B | Melatih Sota Code LLM dalam 1 minggu dan mengukur getaran - dengan Reza Shabani dari Replit | 2.7 | ketakterbatasan? (Alibi) | CC BY-SA-4.0 | Repit-Code-V1-3B |
| Codegen2 | 2023/04 | codegen2 1b-16b | Codegen2: Pelajaran untuk Pelatihan LLMS tentang Pemrograman dan Bahasa Alami | 1 - 16 | 2048 | Apache 2.0 | |
| Codet5+ | 2023/05 | Codet5+ | CODET5+: Kode terbuka model bahasa besar untuk pemahaman dan pembuatan kode | 0.22 - 16 | 512 | BSD-3-Clause | Codet5+-6b |
| Xgen-7b | 2023/06 | XGEN-7B-8K-BASE | Pemodelan Urutan Panjang dengan XGEN: A 7B LLM Dilatih pada Panjang Urutan Input 8K | 7 | 8192 | Apache 2.0 | |
| Codegen2.5 | 2023/07 | Codegen2.5-7b-multi | Codegen2.5: kecil, tapi perkasa | 7 | 2048 | Apache 2.0 | |
| Decicoder-1b | 2023/08 | Decicoder-1b | Memperkenalkan Decicoder: Standar Emas Baru dalam Pembuatan Kode yang Efisien dan Akurat | 1.1 | 2048 | Apache 2.0 | Demo Decicoder |
| Kode llama | 2023 | Kode inferensi untuk model codellama | Kode Llama: Model Yayasan Terbuka untuk Kode | 7 - 34 | 4096 | Model | Huggingchat |
| Burung gereja | 2022/09 | Kode inferensi | Kode | 70 | 4096 | Model | Halaman web |
| Mistral | 2023/09 | Kode inferensi | Kode | 7 | 8000 | Model | Halaman web |
| Koala | 2023/04 | Kode inferensi | Kode | 13 | 4096 | Model | Halaman web |
| Palm 2 | 2024 | N/a | Google AI | 540 | N/a | N/a | N/a |
| Tongyi Qianwen | 2024 | N/a | ALIBABA Cloud | N/a | N/a | N/a | N/a |
| Perintah cohere | 2024 | N/a | Berpadu | 6 - 52 | N/a | N/a | N/a |
| Vicuna 33B | 2024 | N/a | Meta AI | 33 | N/a | N/a | N/a |
| Guanaco-65b | 2024 | N/a | Meta AI | 65 | N/a | N/a | N/a |
| Amazon q | 2024 | N/a | AWS | N/a | N/a | N/a | N/a |
| Falcon 180b | 2024 | Falcon-180b | Lembaga Inovasi Teknologi | 180 | N/a | Apache 2.0 | N/a |
| Yi 34b | 2024 | N/a | 01 ai | 34 | Hingga 32k | N/a | N/a |
| Mixtral 8x7b | 2023 | Mixtral 8x 7b | AI Mistral | 46.7 (12.9 per token) | N/a | Apache 2.0 | N/a |
Jika Anda menemukan survei kami berguna untuk penelitian Anda, silakan kutip makalah berikut:
@article{hadi2024large,
title={Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects},
author={Hadi, Muhammad Usman and Al Tashi, Qasem and Shah, Abbas and Qureshi, Rizwan and Muneer, Amgad and Irfan, Muhammad and Zafar, Anas and Shaikh, Muhammad Bilal and Akhtar, Naveed and Wu, Jia and others},
journal={Authorea Preprints},
year={2024},
publisher={Authorea}
}


