ai_trailer
1.0.0
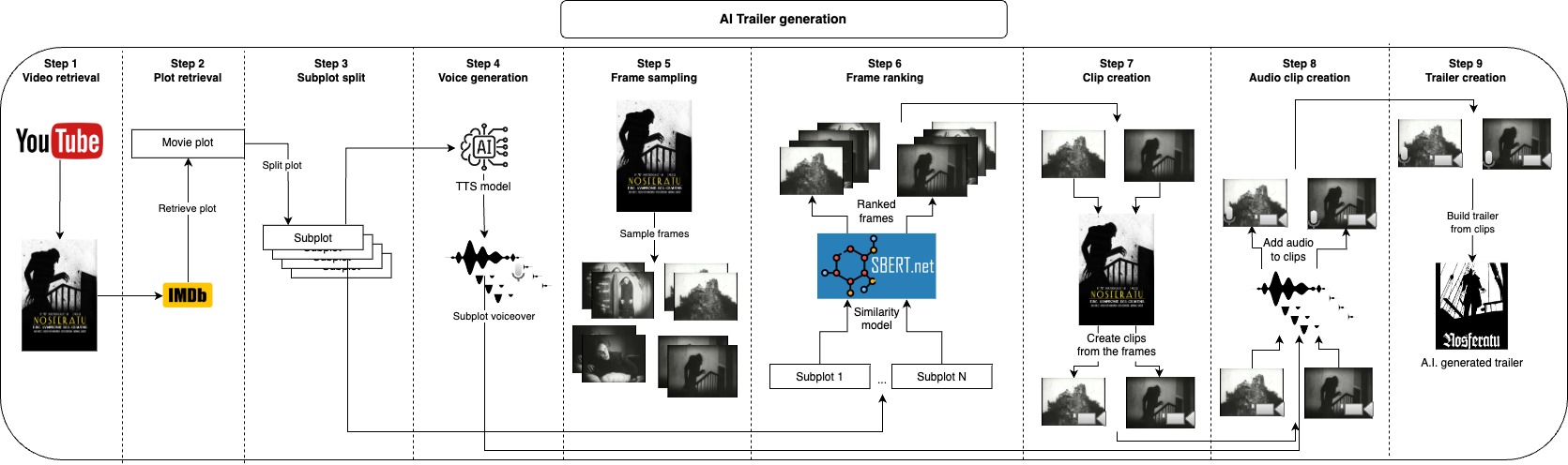
該存儲庫的想法是自動為給定視頻生成許多預告片候選,用戶只需要提供視頻文件和幾個文本參數,並且所有其他內容都受到關注。
首先,我們可以選擇將視頻的圖在IMDB中分為子圖,而不是從IMDB中取出,您還可以提供自己的繪圖或修改它,而是這些子圖將大致描述視頻的主要部分,接下來,我們為每個子圖生成語音。現在,我們只需要使用與每個子圖相對應的簡短剪輯並將聲音應用在它們上,我們可以通過對視頻中的許多幀進行採樣,並將一些最相似的框架與每個子圖一起使用,我們擁有最能代表每個子圖的圖像是,下一步將是從每個框架開始的幾秒鐘,我們的圖像是最好的。在產生了預告片的音頻和視覺部分之後,我們只需要將每個音頻與相應的剪輯結合在一起,最後將所有夾子一起連接到最終的預告片中。
所有這些步驟都將生成中間文件,您可以檢查並手動刪除您不喜歡改善結果的內容。
注意:對於默認參數,對於每個子圖,將僅生成一個音頻和一個剪輯,從而僅創建一個預告片候選者。如果您希望創建更多的預告片候選者或有更多的音頻和剪輯可供選擇,則可以增加
n_audios和n_retrieved_images,只需記住,預告片候選人隨著幾何而隨著n_audios = 3和n_retrieved_images = 3您將擁有9(3 ** 3 ** 3)Trailer Candidates。
使用此存儲庫的建議方法是與Docker一起使用,但是您也可以使用自定義VENV,只需確保安裝所有依賴項即可。
用戶只需要提供兩個輸入,即視頻文件和IMDB ID。之後,您可以轉到configs.yaml文件並相應地調整值, video_id將是IMDB ID, video_path應該指向視頻文件,您可能還需要將project_name更新為視頻名稱,並使用reference_voice_path提供參考語音。
IMDB上任何電影的URL看起來都將看起來像“ https://www.imdb.com/title/tt0063350”,ID將是title/之後的整數部分,在這種情況下,“活死之夜”的情況下,它將是0063350 ,IMDB主要可以找到電影的信息,但您還可以找到系列錄製的情節和其他錄像帶。
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
構建Docker圖像
make build運行整個管道以從視頻和情節開始創建預告片
make trailer運行整個管道以從視頻開始創建預告片,然後從IMDB檢索該圖
make trailer_imdb運行整個管道以從情節開始創建預告片,然後從YouTube下載視頻
make trailer_youtube運行整個管道以創建預告片,從YouTube下載視頻並從IMDB檢索劇情
make trailer_imdb_youtube運行視頻檢索步驟
make video_retrieval運行情節檢索步驟
make plot_retrieval運行子圖步驟
make subplot運行語音步驟
make voice運行框架步驟(幀採樣)
make frame運行image_retrieval步驟(幀排名)
make image_retrieval運行剪輯步驟
make clip運行AUDIO_CLIP步驟
make audio_clip運行join_clip步驟
make join_clip將絨毛和格式應用於代碼(僅需要開發)
make lint為了開發,請確保安裝requirements-dev.txt並運行make lint以維護編碼樣式。
默認情況下,我使用的是Coqui AI的XTT,如果您打算在此處使用輸出,則在Coqui公共模型許可下使用XTT。


