ai_trailer
1.0.0
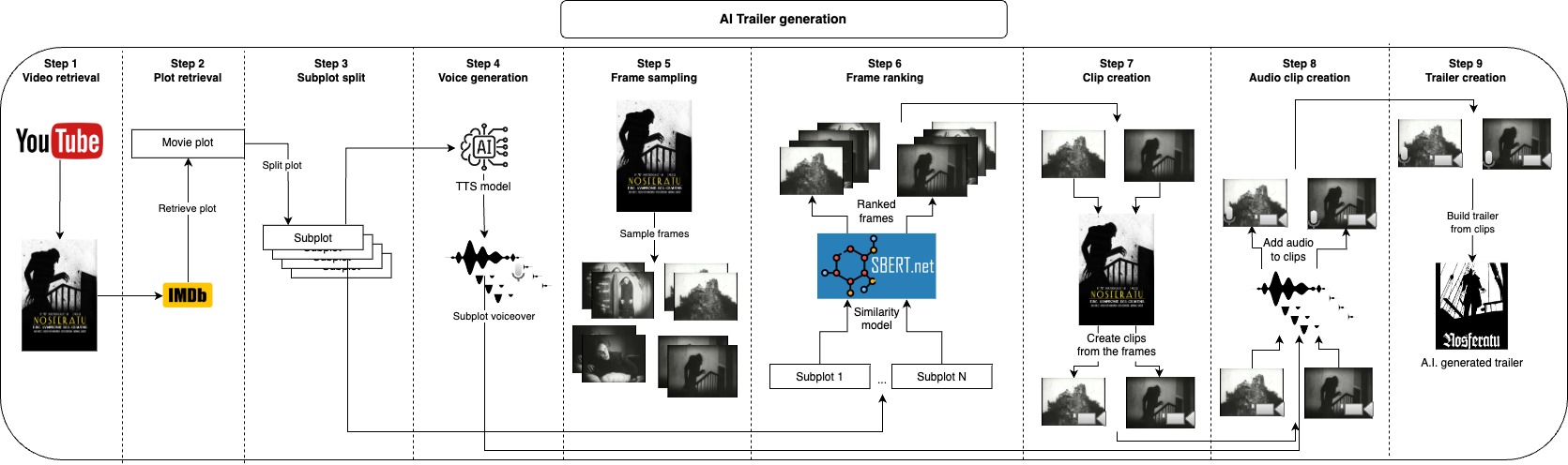
A idéia deste repositório é gerar automaticamente vários candidatos a reboques para um determinado vídeo, o usuário precisa fornecer apenas o arquivo de vídeo e alguns parâmetros de texto, e todo o resto é resolvido.
Primeiro, opcionalmente, pegamos o enredo do vídeo no IMDB e o dividimos em subparcelas, em vez de retirar do IMDB Você também pode fornecer seu próprio enredo ou modificá -lo, essas subparcelas descrevem aproximadamente as partes principais do vídeo e, em seguida, geimos uma voz para cada subparcela. Agora que temos a parte falada do trailer, só precisamos pegar clipes curtos correspondentes a cada subtrama e aplicar a voz sobre eles, fazemos isso amostrando muitos quadros do vídeo e pegando alguns dos quadros mais semelhantes a cada subparcela, com isso, temos as imagens que melhor representam cada sub -trama, a próxima etapa seria dar um pouco de alguns segundos a partir de cada um dos segundos. Depois de gerar a parte de áudio e visual do trailer, precisamos apenas combinar cada áudio com o clipe correspondente e finalmente juntar todos os clipes no trailer final.
Todas essas etapas geram arquivos intermediários que você pode inspecionar e remover manualmente o que não gosta de melhorar os resultados.
NOTA: Com os parâmetros padrão, para cada subparcela, apenas um áudio e um clipe serão gerados, criando apenas um candidato ao trailer. Se você deseja criar mais candidatos ao trailer ou ter mais opções de áudios e clipes para escolher, pode aumentar
n_audiosen_retrieved_images, lembre -se de que os candidatos ao trailer aumentam geometricamente com isso, paran_audios = 3en_retrieved_images = 3você terá 9 (3 ** 3)
A abordagem recomendada para usar este repositório é com o Docker, mas você também pode usar um VENV personalizado, apenas instale todas as dependências.
O usuário precisa fornecer apenas duas entradas , o arquivo de vídeo e o ID do IMDB desse vídeo. Depois disso, você pode acessar o arquivo configs.yaml e ajustar os valores de acordo, o video_id será o ID do IMDB e video_path deve apontar para o arquivo do vídeo, você também pode atualizar project_name para o nome do seu vídeo e fornecer uma voz de referência com reference_voice_path .
Qualquer URL de filme no IMDB se parecerá com este "https://www.imdb.com/title/tt0063350", o ID será a parte inteira após title/ , neste caso para "Night of the Living Dead", seria 0063350 , outras informações do filme.
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
Construa a imagem do Docker
make buildExecute todo o pipeline para criar o trailer a partir de um vídeo e um enredo
make trailerExecute todo o pipeline para criar o trailer a partir de um vídeo e recuperar o enredo do IMDB
make trailer_imdbExecute o pipeline inteiro para criar o trailer a partir de um enredo e baixando o vídeo do YouTube
make trailer_youtubeExecute o pipeline inteiro para criar o trailer baixando o vídeo do YouTube e recuperando o enredo do IMDB
make trailer_imdb_youtubeExecute a etapa de recuperação de vídeo
make video_retrievalExecute a etapa de recuperação da trama
make plot_retrievalExecute a etapa da subparcela
make subplotExecute a etapa de voz
make voiceExecute a etapa da estrutura (amostragem de quadros)
make frameExecute a etapa Image_retrieval (classificação de quadros)
make image_retrievalExecute a etapa do clipe
make clipExecute a etapa Audio_Clip
make audio_clipExecute a etapa JOUN_CLIP
make join_clipAplique fiapos e formatação ao código (necessário apenas para o desenvolvimento)
make lint Para o desenvolvimento, instale requirements-dev.txt e a execução make lint mantenham o estilo de codificação.
Por padrão, estou usando XTTS da Coqui ai, o modelo está sob a licença do Modelo Público Coqui, verifique se você planeja usar as saídas aqui.


