ai_trailer
1.0.0
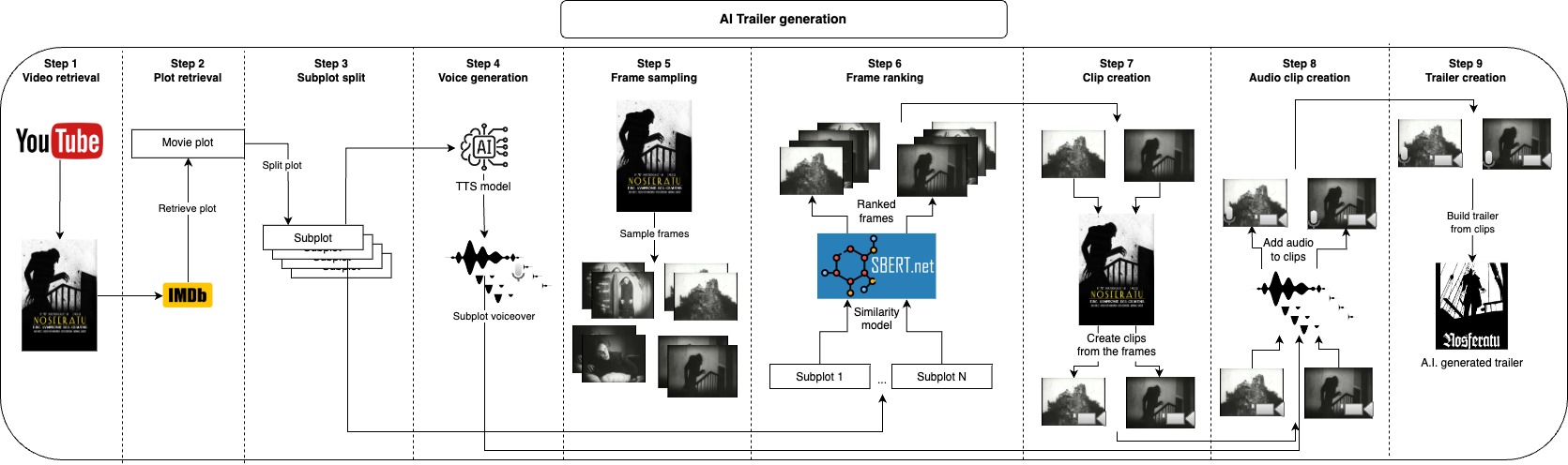
La idea de este repositorio es generar automáticamente una serie de candidatos para un video determinado, el usuario solo necesita proporcionar el archivo de video y un par de parámetros de texto, y todo lo demás se cuida.
Primero, opcionalmente tomamos la trama del video en IMDB y la dividimos en subtramas, en lugar de tomar desde IMDB, también podría proporcionar su propia trama o modificarla, esas subtramas describirán aproximadamente las partes principales del video, y luego generamos una voz para cada subtrama. Ahora que tenemos la parte hablada del trailer, solo necesitamos tomar clips cortos correspondientes a cada trama secundario y aplicar la voz sobre ellos, lo hacemos muestreando muchos cuadros del video y tomando algunos de los marcos más similares a cada subtrama, con esto tenemos las imágenes que mejor representan cada subplotación, el siguiente paso sería tomar un clip de unos pocos segundos que comienzan de cada marco. Después de generar la parte de audio y visual del trailer, solo necesitamos combinar cada audio con el clip correspondiente y finalmente unir todos los clips juntos en el avance final.
Todos esos pasos generarán archivos intermedios que puede inspeccionar y eliminar manualmente lo que no le gusta para mejorar los resultados.
Nota: Con los parámetros predeterminados, para cada trama subplotta, solo se generará un audio y un clip, creando así solo un candidato de remolque. Si desea crear más candidatos para remolques o tiene más opciones de audios y clips para elegir, puede aumentar
n_audiosyn_retrieved_images, solo tenga en cuenta que los candidatos del remolque aumentan geométricamente con esto, paran_audios = 3yn_retrieved_images = 3tendrá 9 (3 ** 3) candidatos en el avance al final.
El enfoque recomendado para usar este repositorio es con Docker, pero también puede usar un VenV personalizado, solo asegúrese de instalar todas las dependencias.
El usuario solo necesita proporcionar dos entradas , el archivo de video y la ID IMDB de ese video. Después de eso, puede ir al archivo configs.yaml y ajustar los valores en consecuencia, video_id será la ID IMDB, y video_path debe apuntar al archivo del video, también puede actualizar project_name al nombre de su video y proporcionar una voz de referencia con reference_voice_path .
La URL de cualquier película en IMDB se verá así "https://www.imdb.com/title/tt0063350", la identificación será la parte entera después title/ , en este caso para "Night of the Living Dead" serían 0063350 , IMDB principalmente tiene la información de películas, pero también puede encontrar episodios de la serie y otros videos.
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
Construye la imagen Docker
make buildEjecute toda la tubería para crear el trailer a partir de un video y una trama
make trailerEjecute toda la tubería para crear el trailer a partir de un video y recuperar la trama de IMDB
make trailer_imdbEjecute toda la tubería para crear el trailer a partir de una trama y descargar el video de YouTube
make trailer_youtubeEjecute toda la tubería para crear el trailer descargando el video de YouTube y recuperando la trama de IMDB
make trailer_imdb_youtubeEjecute el paso de recuperación de video
make video_retrievalEjecute el paso de recuperación de la trama
make plot_retrievalEjecute el paso de la subplot
make subplotEjecutar el paso de voz
make voiceEjecute el paso de cuadro (muestreo de marco)
make frameEjecute el paso de imagen_retrieval (clasificación de cuadros)
make image_retrievalEjecute el paso de clip
make clipEjecute el paso audio_clip
make audio_clipEjecute el paso Join_clip
make join_clipAplicar la pelusa y el formato al código (solo necesario para el desarrollo)
make lint Para el desarrollo, asegúrese de instalar requirements-dev.txt y ejecute make lint para mantener el estilo de codificación.
De manera predeterminada, estoy usando XTTS de Coqui AI, el modelo está bajo la licencia del modelo público de Coqui, asegúrese de echar un vistazo allí si planea usar las salidas aquí.


