ai_trailer
1.0.0
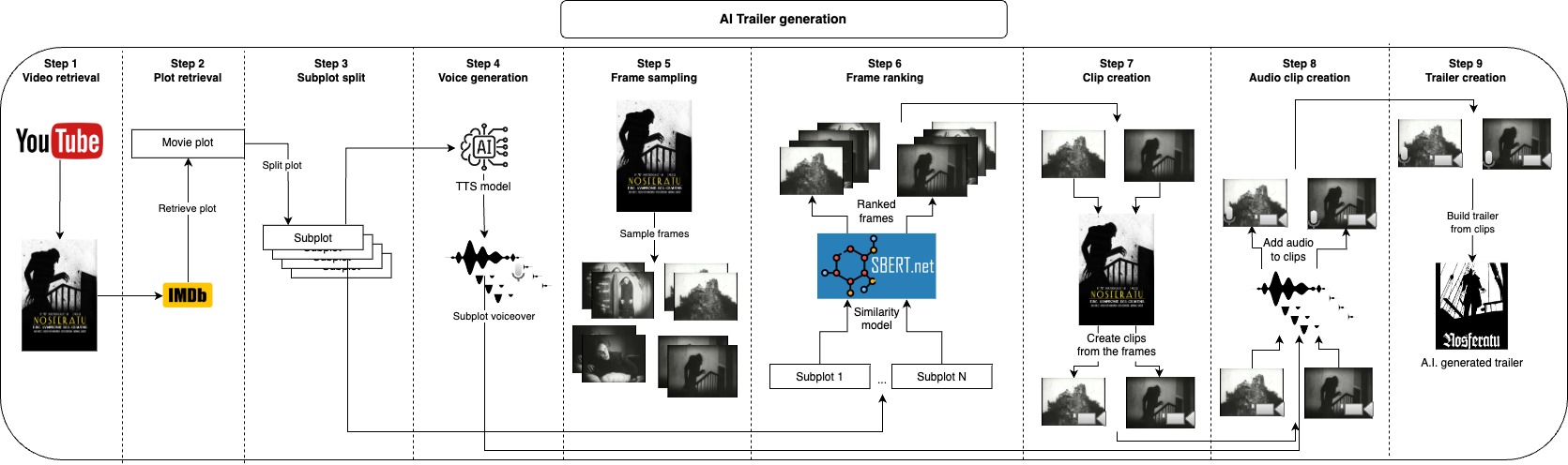
Gagasan repositori ini adalah untuk secara otomatis menghasilkan sejumlah kandidat trailer untuk video yang diberikan, pengguna hanya perlu menyediakan file video dan beberapa parameter teks, dan yang lainnya dirawat.
Pertama, kami secara opsional mengambil plot video di IMDB dan membaginya menjadi subplot, alih -alih mengambil dari IMDB, Anda juga dapat memberikan plot Anda sendiri atau memodifikasinya, subplot tersebut akan secara kasar menggambarkan bagian -bagian utama dari video, dan selanjutnya, kami menghasilkan suara untuk setiap subplot. Sekarang kita memiliki bagian lisan dari trailer, kita hanya perlu mengambil klip pendek yang sesuai dengan setiap subplot dan menerapkan suara di atasnya, kita melakukan ini dengan mencicipi banyak frame dari video dan mengambil beberapa bingkai yang paling mirip untuk setiap subplot, dengan ini kita memiliki gambar yang paling mewakili setiap subplot, langkah berikutnya adalah mengambil klip dari beberapa detik dari setiap bingkai. Setelah menghasilkan bagian audio dan visual dari trailer, kami hanya perlu menggabungkan setiap audio dengan klip yang sesuai dan akhirnya bergabung dengan semua klip bersama ke trailer akhir.
Semua langkah itu akan menghasilkan file menengah yang dapat Anda periksa dan secara manual menghapus apa yang tidak Anda sukai untuk meningkatkan hasilnya.
Catatan: Dengan parameter default, untuk setiap subplot hanya satu audio dan satu klip yang akan dihasilkan sehingga hanya membuat satu kandidat trailer. Jika Anda ingin membuat lebih banyak kandidat trailer atau memiliki lebih banyak opsi audio dan klip untuk dipilih, Anda dapat meningkatkan
n_audiosdann_retrieved_images, perlu diingat bahwa kandidat trailer meningkatkan secara geometri dengan ini, untukn_audios = 3dann_retrieved_images = 3Anda akan memiliki 9 (3 ** 3) TRAILOT.
Pendekatan yang disarankan untuk menggunakan repositori ini adalah dengan Docker, tetapi Anda juga dapat menggunakan VENV khusus, pastikan untuk menginstal semua dependensi.
Pengguna hanya perlu memberikan dua input , file video dan ID IMDB dari video itu. Setelah itu Anda dapat pergi ke file configs.yaml dan menyesuaikan nilainya sesuai, video_id akan menjadi ID IMDB, dan video_path harus menunjuk ke file video, Anda mungkin juga ingin memperbarui project_name ke nama video Anda dan memberikan suara referensi dengan reference_voice_path .
URL film mana pun di IMDB akan terlihat seperti ini "https://www.imdb.com/title/tt0063350", ID akan menjadi bagian integer setelah title/ , dalam hal ini untuk "Night of the Living Dead" akan menjadi 0063350 , IMDB terutama memiliki informasi film tetapi Anda juga dapat menemukan seri 0063350.
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
Bangun gambar Docker
make buildJalankan seluruh pipa untuk membuat trailer mulai dari video dan plot
make trailerJalankan seluruh pipa untuk membuat trailer mulai dari video dan mengambil plot dari IMDB
make trailer_imdbJalankan seluruh pipa untuk membuat trailer mulai dari plot dan mengunduh video dari YouTube
make trailer_youtubeJalankan seluruh pipa untuk membuat trailer yang mengunduh video dari YouTube dan mengambil plot dari IMDB
make trailer_imdb_youtubeJalankan langkah pengambilan video
make video_retrievalJalankan langkah pengambilan plot
make plot_retrievalJalankan langkah subplot
make subplotJalankan Langkah Suara
make voiceJalankan langkah bingkai (bingkai pengambilan sampel)
make frameJalankan Langkah Image_Retrieval (peringkat bingkai)
make image_retrievalJalankan langkah klip
make clipJalankan langkah audio_clip
make audio_clipJalankan langkah join_clip
make join_clipTerapkan serat dan pemformatan ke kode (hanya diperlukan untuk pengembangan)
make lint Untuk pengembangan, pastikan untuk menginstal requirements-dev.txt dan jalankan, make lint untuk mempertahankan gaya pengkodean.
Secara default saya menggunakan xtts dari coqui ai model ini di bawah lisensi model publik coqui pastikan untuk melihat di sana jika Anda berencana untuk menggunakan output di sini.


