ai_trailer
1.0.0
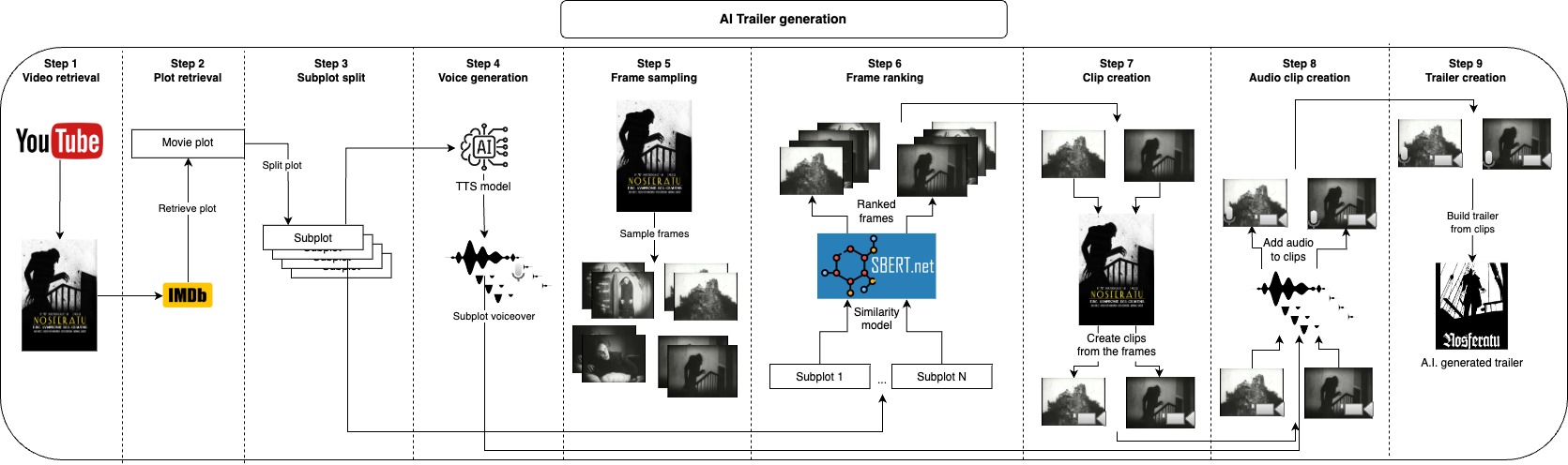
Идея этого репозитория состоит в том, чтобы автоматически генерировать ряд кандидатов в трейлер для данного видео, пользователю необходимо только предоставить видеофайл и пару параметров текста, и все остальное позаботится.
Во -первых, мы при желании принимаем сюжет видео в IMDB и разделяем его на сюжеты, вместо того, чтобы брать из IMDB, вы также можете предоставить свой собственный сюжет или изменить его, эти сюжеты примерно опишут основные части видео, а затем мы генерируем голос для каждого сюжета. Теперь, когда у нас есть разговорная часть трейлера, нам просто нужно взять короткие клипы, соответствующие каждому сюжету, и применить голос над ними, мы делаем это, отбирая множество кадров из видео и взяв некоторые из наиболее похожих кадров на каждый сюжет, причем это у нас есть изображения, которые наилучшим образом представляют каждый сюжет, следующим шагом будет принять клип из нескольких секунд, начинающийся с каждого кадра. После создания аудио и визуальной части трейлера, нам просто нужно объединить каждый звук с соответствующим клипом и, наконец, соединить все клипы вместе с финальным трейлером.
Все эти шаги будут генерировать промежуточные файлы, которые вы можете проверить, и вручную удалить то, что вам не нравится, чтобы улучшить результаты.
ПРИМЕЧАНИЕ. С параметрами по умолчанию для каждого сюжета только один аудио и один клип будет создан таким образом, создавая только один кандидат в трейлер. Если вы хотите создать больше кандидатов в трейлер или у вас есть больше вариантов аудио и клипов, которые вы можете увеличить, вы можете увеличить
n_audiosиn_retrieved_images, просто имейте в виду, что кандидаты в трейлер геометрично увеличивают это, дляn_audios = 3иn_retrieved_images = 3у вас будет 9 (3 ** 3).
Рекомендуемый подход для использования этого репозитория с Docker, но вы также можете использовать пользовательский Venv, просто убедитесь, что установите все зависимости.
Пользователю необходимо предоставить только два входа : видеофайл и IMDB идентификатор из этого видео. После этого вы можете перейти в файл configs.yaml и соответствующим образом настроить значения, video_id будет идентификатором IMDB, а video_path должен указывать на файл видео, вы также можете обновить project_name на имя вашего видео и предоставить ссылочный голос с помощью reference_voice_path .
URL -адрес любого фильма в IMDB будет выглядеть как этот «https://www.imdb.com/title/tt0063350», идентификатор станет целым числом за title/ , в данном случае для «Ночи живых мертвецов», это будет 0063350 , IMDB, главным образом, имеет информацию о фильме, но вы также можете найти серии и другие видео.
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
Создайте изображение Docker
make buildЗапустите весь трубопровод, чтобы создать трейлер, начиная с видео и сюжета
make trailerЗапустите весь трубопровод, чтобы создать трейлер, начиная с видео и извлечь сюжет из IMDB
make trailer_imdbЗапустите весь конвейер, чтобы создать трейлер, начиная с сюжета и загрузить видео с YouTube
make trailer_youtubeЗапустите весь конвейер, чтобы создать трейлер, загружающий видео с YouTube и получение сюжета из IMDB
make trailer_imdb_youtubeЗапустите шаг поиска видео
make video_retrievalЗапустить шаг поиска сюжета
make plot_retrievalЗапустить шаг подзасконского участка
make subplotЗапустить шаг голоса
make voiceЗапустите шаг кадра (выборка кадра)
make frameЗапустите шаг Image_retrieval (рейтинг кадров)
make image_retrievalЗапустите шаг клипа
make clipЗапустите шаг audio_clip
make audio_clipЗапустите шаг join_clip
make join_clipПрименить ворс и форматирование к коду (необходимо только для разработки)
make lint Для разработки обязательно установите requirements-dev.txt и запустить make lint для поддержания стиля кодирования.
По умолчанию я использую XTTS из Coqui AI, модель находится по лицензии Coqui Public Model, обязательно посмотрите, если вы планируете использовать выходы здесь.


