ai_trailer
1.0.0
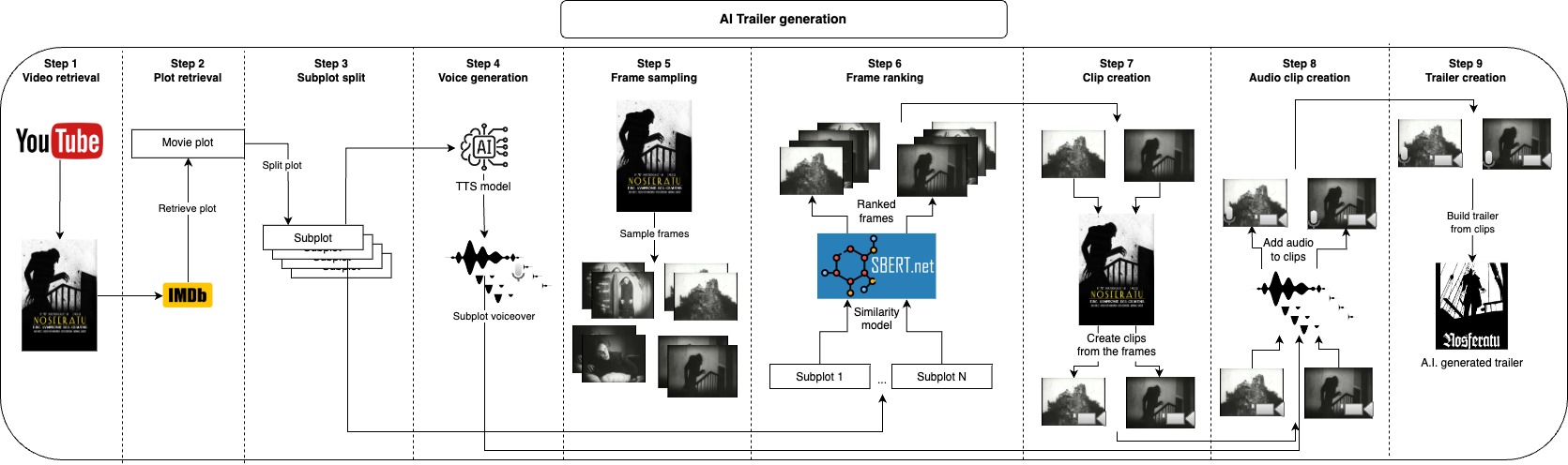
تتمثل فكرة هذا المستودع في إنشاء عدد من المرشحين لمقطع فيديو معين تلقائيًا ، ويحتاج المستخدم فقط إلى توفير ملف الفيديو واثنين من المعلمات النصية ، ويتم العناية بكل شيء آخر.
أولاً ، نأخذ مؤامرة الفيديو اختياريًا في IMDB ونقسمها إلى مخططات فرعية ، بدلاً من أخذها من IMDB ، يمكنك أيضًا تقديم مؤامرة خاصة بك أو تعديلها ، وسوف تصف تلك المخططات الفرعية الأجزاء الرئيسية تقريبًا من الفيديو ، وبعد ذلك ، ننشئ صوتًا لكل مخطط فرعي. الآن وبعد أن أصبح لدينا الجزء المنطوق من المقطورة ، نحتاج فقط إلى تناول مقاطع قصيرة تقابل كل مخطط فرعي وتطبيق الصوت عليها ، فإننا نفعل ذلك عن طريق أخذ عينات من العديد من الإطارات من الفيديو ونأخذ بعض الإطارات الأكثر تشابهًا إلى كل مخطط فرعي ، مع هذا ، لدينا الصور التي تمثل كل مخطط فرعي أفضل ، والخطوة التالية هي اتخاذ مقطع لبدء ثوانٍ تبدأ من كل إطار. بعد إنشاء الجزء الصوتي والبصري من المقطورة ، نحتاج فقط إلى الجمع بين كل صوت مع المقطع المقابل ونضم أخيرًا جميع المقاطع معًا في المقطورة النهائية.
ستقوم كل هذه الخطوات بإنشاء ملفات وسيطة يمكنك فحصها وإزالة ما لا تحب تحسين النتائج يدويًا.
ملاحظة: مع المعلمات الافتراضية ، لكل حبكة فرعية فقط سيتم إنشاء مقطع واحد وبالتالي إنشاء مرشح واحد فقط. إذا كنت ترغب في إنشاء المزيد من المرشحين للمقطورة أو لديك المزيد من الخيارات من Audios والمقاطع للاختيار من بينها ، فيمكنك زيادة
n_audiosوn_retrieved_images، فقط ضع في اعتبارك أن مرشحين المقطورة يزدادون هندسيًا مع هذا ، من أجل المقطورةn_audios = 3وn_retrieved_images = 3ستحصل على 9 (3 **).
النهج الموصى به لاستخدام هذا المستودع هو مع Docker ، ولكن يمكنك أيضًا استخدام VenV مخصص ، فقط تأكد من تثبيت جميع التبعيات.
يحتاج المستخدم فقط إلى توفير مدخلتين ، ملف الفيديو ومعرف IMDB من هذا الفيديو. بعد ذلك ، يمكنك الانتقال إلى ملف configs.yaml وضبط القيم وفقًا لذلك ، سيكون video_id معرف IMDB ، ويجب أن يشير video_path إلى ملف الفيديو ، وقد ترغب أيضًا في تحديث project_name إلى اسم الفيديو الخاص بك وتقديم صوت مرجعي مع reference_voice_path .
سيبدو عنوان URL الخاص بأي فيلم في IMDB مثل "https://www.imdb.com/title/tt0063350" ، وسيكون المعرف هو الجزء الصحيح بعد title/ ، في هذه الحالة من أجل "Night of the Living Dead" ، سيكون 0063350 ، IMDB يحتوي بشكل رئيسي على إعلانات الفيلم ولكن يمكنك أيضًا العثور على سلسلة من الحلقات وغيرها.
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
بناء صورة Docker
make buildقم بتشغيل خط الأنابيب بأكمله لإنشاء مقطورة تبدأ من مقطع فيديو ومؤامرة
make trailerقم بتشغيل خط الأنابيب بأكمله لإنشاء المقطورة التي تبدأ من مقطع فيديو واسترداد المؤامرة من IMDB
make trailer_imdbقم بتشغيل خط الأنابيب بأكمله لإنشاء المقطورة التي تبدأ من مؤامرة وتنزيل الفيديو من YouTube
make trailer_youtubeقم بتشغيل خط الأنابيب بأكمله لإنشاء مقطورة تنزيل الفيديو من YouTube واسترداد المؤامرة من IMDB
make trailer_imdb_youtubeقم بتشغيل خطوة استرجاع الفيديو
make video_retrievalقم بتشغيل خطوة استرجاع المؤامرة
make plot_retrievalقم بتشغيل الخطوة الفرعية
make subplotقم بتشغيل الخطوة الصوتية
make voiceقم بتشغيل خطوة الإطار (أخذ عينات الإطار)
make frameقم بتشغيل خطوة Image_retrival (تصنيف الإطار)
make image_retrievalقم بتشغيل خطوة المقطع
make clipقم بتشغيل خطوة Audio_clip
make audio_clipقم بتشغيل خطوة join_clip
make join_clipتطبيق الوبر والتنسيق على الرمز (اللازم فقط للتنمية)
make lint للتطور ، تأكد من تثبيت requirements-dev.txt وتشغيل make lint للحفاظ على نمط الترميز.
بشكل افتراضي ، أستخدم XTTS من Coqui AI ، النموذج تحت رخصة طراز Coqui العامة ، تأكد من إلقاء نظرة هناك إذا كنت تخطط لاستخدام المخرجات هنا.


