ai_trailer
1.0.0
แนวคิดของพื้นที่เก็บข้อมูลนี้คือการสร้างตัวเลือกรถพ่วงสำหรับวิดีโอที่กำหนดโดยอัตโนมัติผู้ใช้จะต้องจัดเตรียมไฟล์วิดีโอและพารามิเตอร์ข้อความสองสามตัวและทุกอย่างได้รับการดูแล
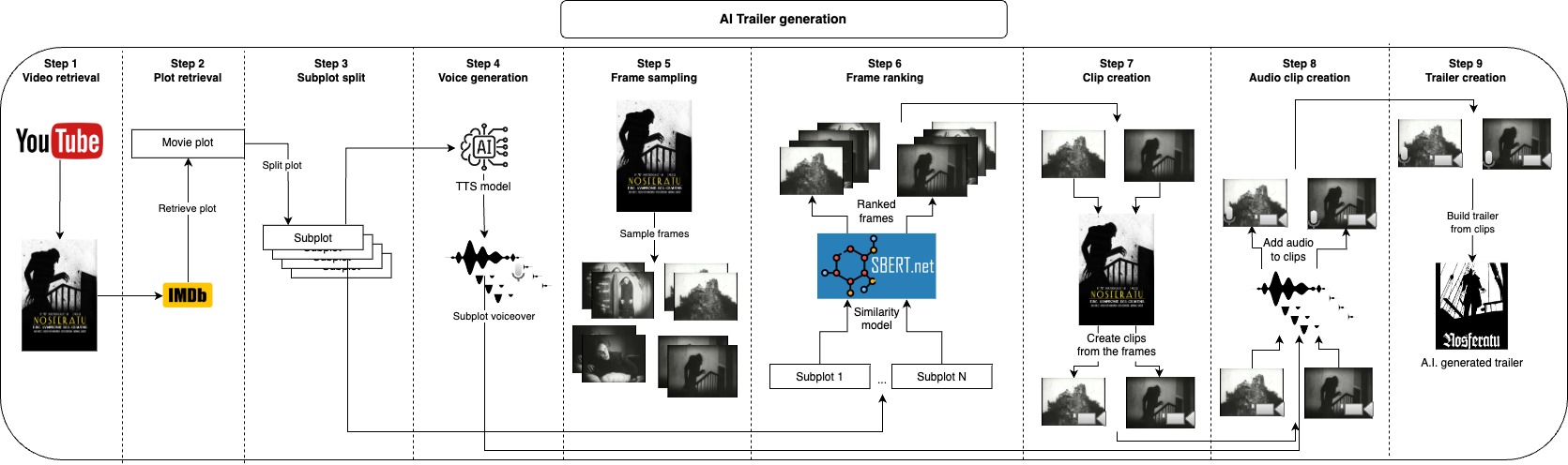
ก่อนอื่นเราเลือกใช้พล็อตของวิดีโอที่ IMDB และแยกออกเป็นแผนย่อยแทนที่จะใช้ที่จาก IMDB คุณสามารถให้พล็อตของคุณเองหรือปรับเปลี่ยนแผนการย่อยเหล่านั้นจะอธิบายส่วนหลักของวิดีโอและต่อไปเราสร้างเสียงสำหรับแต่ละแผนย่อย ตอนนี้เรามีส่วนที่พูดของรถพ่วงเราเพียงแค่ต้องใช้คลิปสั้น ๆ ที่สอดคล้องกับแต่ละแผนย่อยและใช้เสียงกับพวกเขาเราทำสิ่งนี้โดยการสุ่มตัวอย่างเฟรมจำนวนมากจากวิดีโอและใช้เฟรมที่คล้ายกันมากที่สุดในแต่ละแผนย่อย หลังจากสร้างส่วนเสียงและภาพของรถพ่วงเราเพียงแค่ต้องรวมเสียงแต่ละรายการเข้ากับคลิปที่สอดคล้องกันและในที่สุดก็เข้าร่วมคลิปทั้งหมดเข้าด้วยกันในรถพ่วงสุดท้าย
ขั้นตอนทั้งหมดเหล่านั้นจะสร้างไฟล์ระดับกลางที่คุณสามารถตรวจสอบและลบสิ่งที่คุณไม่ต้องการปรับปรุงผลลัพธ์ด้วยตนเอง
หมายเหตุ: ด้วยพารามิเตอร์เริ่มต้นสำหรับแต่ละแผนย่อยเพียงหนึ่งเสียงและคลิปหนึ่งคลิปจะถูกสร้างขึ้นดังนั้นการสร้างตัวเลือกรถพ่วงเพียงตัวเดียวเท่านั้น หากคุณต้องการสร้างผู้สมัครรถพ่วงเพิ่มเติมหรือมีตัวเลือกเพิ่มเติมเกี่ยวกับ
n_audios = 3และn_retrieved_images = 3ให้เลือกคุณสามารถเพิ่มn_audiosและn_retrieved_imagesเพียงจำไว้ว่าผู้สมัครรถพ่วงจะเพิ่มขึ้นเรขาคณิตด้วยสิ่งนี้
วิธีที่แนะนำในการใช้ที่เก็บนี้อยู่กับ Docker แต่คุณยังสามารถใช้ VENV ที่กำหนดเองได้เพียงตรวจสอบให้แน่ใจว่าได้ติดตั้งการอ้างอิงทั้งหมด
ผู้ใช้ต้องการเพียงสองอินพุต ไฟล์วิดีโอและ IMDB ID จากวิดีโอนั้น หลังจากนั้นคุณสามารถไปที่ไฟล์ configs.yaml และปรับค่าตามนั้น video_id จะเป็น IMDB ID และ video_path ควรชี้ไปที่ไฟล์วิดีโอคุณอาจต้องการอัปเดต project_name ไปยังชื่อ reference_voice_path ของคุณ
URL ของภาพยนตร์ใด ๆ ที่ IMDB จะมีลักษณะเช่นนี้ "https://www.imdb.com/title/tt0063350" ID จะเป็น ส่วนจำนวนเต็ม หลังจาก title/ ในกรณีนี้สำหรับ "Night of the Living Dead" มันจะเป็น 0063350
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
สร้างภาพนักเทียบท่า
make buildเรียกใช้ไปป์ไลน์ทั้งหมดเพื่อสร้างตัวอย่างที่เริ่มต้นจากวิดีโอและพล็อต
make trailerเรียกใช้ไปป์ไลน์ทั้งหมดเพื่อสร้างตัวอย่างที่เริ่มต้นจากวิดีโอและดึงพล็อตจาก IMDB
make trailer_imdbเรียกใช้ไปป์ไลน์ทั้งหมดเพื่อสร้างตัวอย่างที่เริ่มต้นจากพล็อตและดาวน์โหลดวิดีโอจาก YouTube
make trailer_youtubeเรียกใช้ไปป์ไลน์ทั้งหมดเพื่อสร้างตัวอย่างการดาวน์โหลดวิดีโอจาก YouTube และดึงพล็อตจาก IMDB
make trailer_imdb_youtubeเรียกใช้ขั้นตอนการดึงวิดีโอ
make video_retrievalเรียกใช้ขั้นตอนการดึงพล็อต
make plot_retrievalเรียกใช้ขั้นตอนย่อย
make subplotเรียกใช้ขั้นตอนเสียง
make voiceเรียกใช้ขั้นตอนเฟรม (การสุ่มตัวอย่างเฟรม)
make frameเรียกใช้ขั้นตอน image_retrieval (การจัดอันดับเฟรม)
make image_retrievalเรียกใช้ขั้นตอนคลิป
make clipเรียกใช้ขั้นตอน Audio_clip
make audio_clipเรียกใช้ขั้นตอน join_clip
make join_clipใช้ผ้าสำลีและการจัดรูปแบบกับรหัส (จำเป็นสำหรับการพัฒนาเท่านั้น)
make lint เพื่อการพัฒนาตรวจสอบให้แน่ใจว่าได้ติดตั้ง requirements-dev.txt และเรียกใช้ make lint เพื่อรักษารูปแบบการเข้ารหัส
โดยค่าเริ่มต้นฉันใช้ XTTS จาก Coqui AI โมเดลอยู่ภายใต้ใบอนุญาตโมเดลสาธารณะของ Coqui ตรวจสอบให้แน่ใจว่าได้ดูที่นั่นหากคุณวางแผนที่จะใช้ผลลัพธ์ที่นี่


