ai_trailer
1.0.0
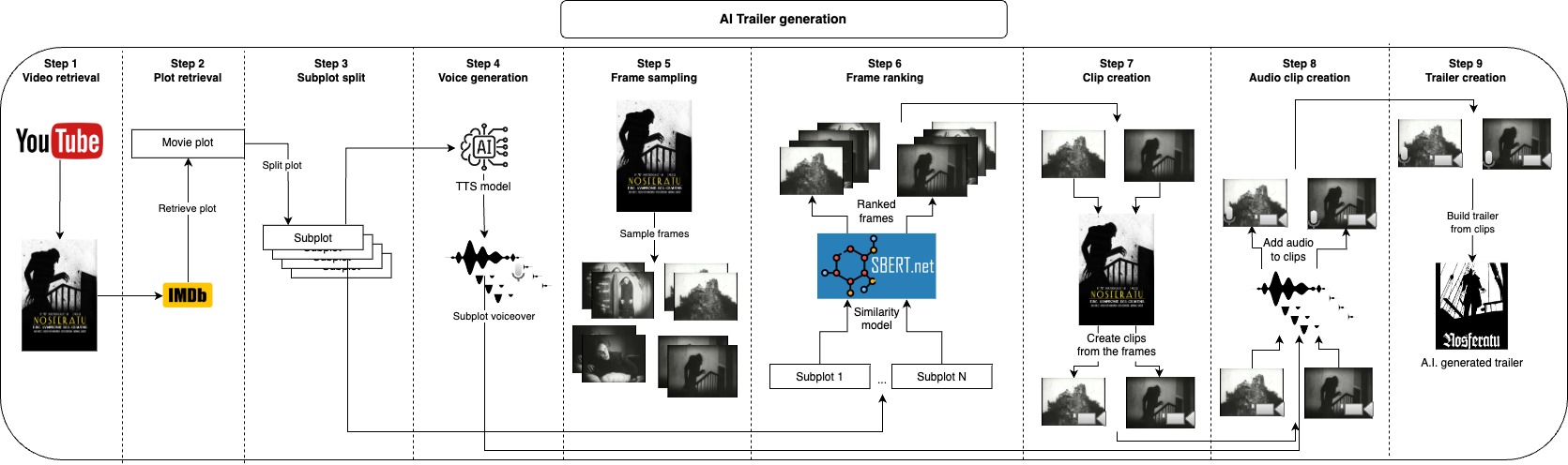
该存储库的想法是自动为给定视频生成许多预告片候选,用户只需要提供视频文件和几个文本参数,并且所有其他内容都受到关注。
首先,我们可以选择将视频的图在IMDB中分为子图,而不是从IMDB中取出,您还可以提供自己的绘图或修改它,而是这些子图将大致描述视频的主要部分,接下来,我们为每个子图生成语音。现在,我们只需要使用与每个子图相对应的简短剪辑并将声音应用在它们上,我们可以通过对视频中的许多帧进行采样,并将一些最相似的框架与每个子图一起使用,我们拥有最能代表每个子图的图像是,下一步将是从每个框架开始的几秒钟,我们的图像是最好的。在产生了预告片的音频和视觉部分之后,我们只需要将每个音频与相应的剪辑结合在一起,最后将所有夹子一起连接到最终的预告片中。
所有这些步骤都将生成中间文件,您可以检查并手动删除您不喜欢改善结果的内容。
注意:对于默认参数,对于每个子图,将仅生成一个音频和一个剪辑,从而仅创建一个预告片候选者。如果您希望创建更多的预告片候选者或有更多的音频和剪辑可供选择,则可以增加
n_audios和n_retrieved_images,只需记住,预告片候选人随着几何而随着n_audios = 3和n_retrieved_images = 3您将拥有9(3 ** 3 ** 3)Trailer Candidates。
使用此存储库的建议方法是与Docker一起使用,但是您也可以使用自定义VENV,只需确保安装所有依赖项即可。
用户只需要提供两个输入,即视频文件和IMDB ID。之后,您可以转到configs.yaml文件并相应地调整值, video_id将是IMDB ID, video_path应该指向视频文件,您可能还需要将project_name更新为视频名称,并使用reference_voice_path提供参考语音。
IMDB上任何电影的URL看起来都将看起来像“ https://www.imdb.com/title/tt0063350”,ID将是title/之后的整数部分,在这种情况下,“活死之夜”的情况下,它将是0063350 ,IMDB主要可以找到电影的信息,但您还可以找到系列录制的情节和其他录像带。
project_dir: 'projects'
project_name: Natural_History_Museum
video_path: 'movies/Natural_History_Museum.mp4'
plot_filename: 'plot.txt'
video_retrieval:
video_url: 'https://www.youtube.com/watch?v=fdcEKPS6tOQ'
plot_retrieval:
video_id:
subplot:
split_char:
voice:
model_id: 'tts_models/multilingual/multi-dataset/xtts_v2'
device: cpu
reference_voice_path: 'voices/sample_voice.wav'
tts_language: en
n_audios: 1
frame_sampling:
n_frames: 500
frame_ranking:
model_id: 'clip-ViT-B-32'
device: cpu
n_retrieved_images: 1
similarity_batch_size: 128
clip:
min_clip_len: 3
audio_clip:
clip_volume: 0.1
voice_volume: 1.0
构建Docker图像
make build运行整个管道以从视频和情节开始创建预告片
make trailer运行整个管道以从视频开始创建预告片,然后从IMDB检索该图
make trailer_imdb运行整个管道以从情节开始创建预告片,然后从YouTube下载视频
make trailer_youtube运行整个管道以创建预告片,从YouTube下载视频并从IMDB检索剧情
make trailer_imdb_youtube运行视频检索步骤
make video_retrieval运行情节检索步骤
make plot_retrieval运行子图步骤
make subplot运行语音步骤
make voice运行框架步骤(帧采样)
make frame运行image_retrieval步骤(帧排名)
make image_retrieval运行剪辑步骤
make clip运行AUDIO_CLIP步骤
make audio_clip运行join_clip步骤
make join_clip将绒毛和格式应用于代码(仅需要开发)
make lint为了开发,请确保安装requirements-dev.txt并运行make lint以维护编码样式。
默认情况下,我使用的是Coqui AI的XTT,如果您打算在此处使用输出,则在Coqui公共模型许可下使用XTT。


