PConv Keras
1.0.0
KERAS實施“使用部分卷積的不規則孔的圖像介入”,https://arxiv.org/abs/1804.07723。作者Guilin Liu,Fitsum A. Reda,Kevin J. Shih,Ting-Chun Wang,Andrew Tao和Nvidia Corporation的Bryan Catanzaro巨大的喊叫聲,這對我來說是一次很棒的學習經歷,這對我來說是一次很棒的學習經歷部分卷積層和損失功能。

嘗試使用此算法進行一些預測的最簡單方法是訪問www.fixmyphoto.ai,在那裡我將其部署在帶有AWS Lambda功能處理推理的無服務器React應用程序上。
如果要研究代碼,則可以在libs/pconv_layer.py和libs/pconv_model.py中找到新的PConv2D KERAS層的主要實現以及使用這些部分卷積層的UNet型體系結構的主要實現。是可以找到大部分實施的地方。除此之外,我已經設置了四個Jupyter筆記本電腦,其中詳細介紹了我在實施網絡時通過的幾個步驟:
步驟1:創建隨機不規則面具
步驟2:實施和測試PConv2D層的實現
步驟3:使用PConv2D層實現和測試UNET體系結構
步驟4:培訓和測試Imagenet的最終架構
步驟5:通過圖像塊預測任意圖像大小的簡單嘗試
我已經將VGG16重量從Pytorch到Keras移植;這意味著1/255.與Pytorch類似,可以將Pixel縮放用於VGG16網絡。
您可以直接轉到步驟4筆記本電腦,也可以使用CLI(請確保下載轉換後的VGG16權重):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
該實施的詳細信息在本文本身中,但是我將嘗試在此處匯總一些詳細信息。
在論文中,他們使用了一種基於視頻中兩個連續幀之間的遮擋/分離來創建隨機不規則掩模的技術 - 相反,我選擇了簡單地創建一個簡單的掩碼生成函數然後,我用於面具。但是,以後插入新的蒙版生成技術不應該是一個問題,我認為使用此方法的最終結果也很不錯。
該實現的關鍵要素是部分卷積層。基本上,鑑於卷積過濾W和相應的偏置B ,應用以下部分卷積而不是正常卷積:
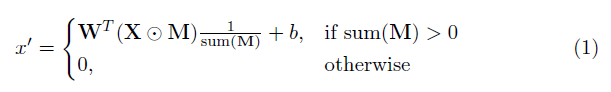
其中⊙是元素的乘法, m是0s和1s的二進制掩碼。重要的是,在每個部分卷積之後,也更新了掩碼,因此,如果卷積能夠在至少一個有效輸入上調節其輸出,則在該位置刪除掩碼,即
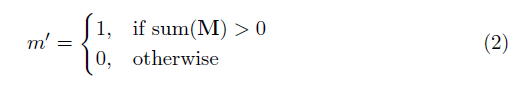
結果是,有了足夠深的網絡,掩模最終將是所有的(即消失)
該體系結構的具體細節可以在論文中找到,但本質上是基於類似於UNET的結構,在該結構中,所有正常的捲積層都被部分卷積層取代,因此在所有情況下,圖像都通過網絡與掩模一起通過網絡。 。以下提供了體系結構的概述。 
本文中使用的損失函數有點強烈,可以在論文中進行審查。簡而言之包括:
所有這些損失條款的加權如下: 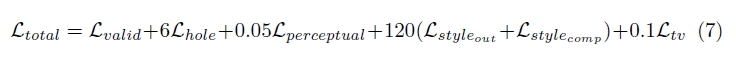
對網絡的批量大小為1,對網絡進行了培訓,並且每個時期都被指定為10,000批次。此外,訓練是在兩個階段使用ADAM優化器進行的,因為批次歸一化提出了掩蓋卷積的問題(因為計算了孔像素的平均值和方差)。
第1階段的學習率為0.0001,對於50個時期
第2階段的學習率為50個時期的0.00005,其中禁用了所有編碼層中的批量歸一化。
訓練圖像絕對瘋狂,但這可能是因為我的個人設置不佳。我在1080TI上嘗試的少數測試(批次大小為4)表明,訓練時間可能約為10天,如論文所示。


