PConv Keras
1.0.0
Implementasi Keras dari " Inpainting Image for tidak teratur menggunakan konvolusi parsial ", https://arxiv.org/abs/1804.07723. Teriakan besar penulis Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-chun Wang, Andrew Tao dan Bryan Catanzaro dari Nvidia Corporation untuk merilis makalah yang luar biasa ini, ini merupakan pengalaman belajar yang hebat bagi saya untuk menerapkan arsitektur, lapisan konvolusional parsial, dan fungsi kerugian.

Cara termudah untuk mencoba beberapa prediksi dengan algoritma ini adalah dengan pergi ke www.fixmyphoto.ai, di mana saya telah menggunakannya pada aplikasi reaksi tanpa server dengan fungsi AWS Lambda yang menangani inferensi.
Jika Anda ingin menggali ke dalam kode, implementasi utama dari lapisan keras PConv2D baru serta arsitektur seperti UNet menggunakan lapisan konvolusional parsial ini dapat ditemukan di libs/pconv_layer.py dan libs/pconv_model.py di situlah sebagian besar implementasi dapat ditemukan. Di luar ini saya telah mengatur empat buku catatan Jupyter, yang merinci beberapa langkah yang saya lalui saat menerapkan jaringan, yaitu:
Langkah 1: Membuat topeng acak tidak beraturan
Langkah 2: Menerapkan dan Menguji Implementasi Lapisan PConv2D
Langkah 3: Menerapkan dan Menguji Arsitektur UNET dengan Lapisan PConv2D
Langkah 4: Pelatihan & Pengujian Arsitektur Akhir di Imagenet
Langkah 5: Upaya sederhana untuk memprediksi ukuran gambar yang sewenang -wenang melalui pemotongan gambar
Saya telah porting bobot VGG16 dari Pytorch ke Keras; Ini berarti 1/255. Penskalaan piksel dapat digunakan untuk jaringan VGG16 yang mirip dengan Pytorch.
Anda dapat langsung ke Notebook Langkah 4, atau sebagai alternatif menggunakan CLI (pastikan untuk mengunduh bobot VGG16 yang dikonversi):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
Rincian implementasi ada di koran itu sendiri, namun saya akan mencoba meringkas beberapa detail di sini.
Dalam makalah mereka menggunakan teknik berdasarkan oklusi/dis-oklusi antara dua frame berturut-turut dalam video untuk membuat topeng tidak beraturan acak-sebaliknya saya telah memilih untuk hanya membuat fungsi mask-generator sederhana yang menggunakan OpenCV untuk menggambar beberapa bentuk tidak teratur acak yang acak yang yang acaknya yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acak yang acaknya Saya kemudian menggunakan untuk topeng. Menegaskan teknik pembuatan mask baru nanti seharusnya tidak menjadi masalah, dan saya pikir hasil akhirnya cukup baik menggunakan metode ini juga.
Elemen kunci dalam implementasi ini adalah lapisan konvolusional parsial. Pada dasarnya, mengingat filter konvolusional W dan bias B yang sesuai, konvolusi parsial berikut diterapkan alih -alih konvolusi normal:
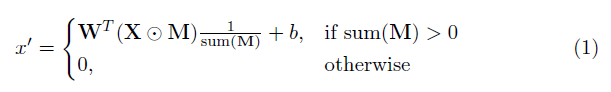
di mana ⊙ adalah penggandaan elemen-bijaksana dan m adalah topeng biner 0s dan 1s. Yang penting, setelah setiap konvolusi parsial, topeng juga diperbarui, sehingga jika konvolusi dapat mengkondisikan outputnya pada setidaknya satu input yang valid, maka topeng dihapus di lokasi itu, yaitu
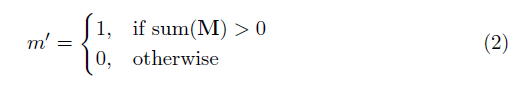
Hasilnya adalah bahwa dengan jaringan yang cukup dalam, topeng pada akhirnya akan menjadi semua (yaitu menghilang)
Rincian spesifik arsitektur dapat ditemukan di koran, tetapi pada dasarnya didasarkan pada struktur yang tidak seperti, di mana semua lapisan konvolusional normal diganti dengan lapisan konvolusional parsial, sehingga dalam semua kasus gambar dilewatkan melalui jaringan di samping topeng tersebut . Berikut ini memberikan gambaran tentang arsitektur. 
Fungsi kerugian yang digunakan dalam makalah ini agak intens, dan dapat ditinjau di koran. Singkatnya itu termasuk:
Bobot semua istilah kerugian ini adalah sebagai berikut: 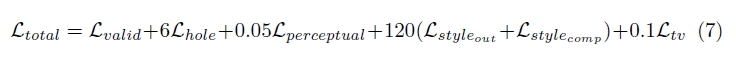
Jaringan dilatih di Imagenet dengan ukuran batch 1, dan setiap zaman ditentukan memiliki panjang 10.000 batch. Pelatihan selanjutnya dilakukan dengan menggunakan Adam Optimizer dalam dua tahap karena normalisasi batch menghadirkan masalah untuk konvolusi bertopeng (karena rata -rata dan varians dihitung untuk piksel lubang).
Tingkat Pembelajaran Tahap 1 0,0001 untuk 50 zaman dengan normalisasi batch diaktifkan di semua lapisan
Tingkat Pembelajaran Tahap 2 0,00005 untuk 50 zaman di mana normalisasi batch di semua lapisan pengkodean dinonaktifkan.
Waktu pelatihan untuk gambar yang ditampilkan benar -benar gila lama, tetapi itu kemungkinan karena pengaturan pribadi saya yang buruk. Beberapa tes yang saya coba pada 1080TI (dengan ukuran batch 4) menunjukkan bahwa waktu pelatihan bisa sekitar 10 hari, seperti yang ditentukan dalam makalah.


