PConv Keras
1.0.0
KERAS实施“使用部分卷积的不规则孔的图像介入”,https://arxiv.org/abs/1804.07723。作者Guilin Liu,Fitsum A. Reda,Kevin J. Shih,Ting-Chun Wang,Andrew Tao和Nvidia Corporation的Bryan Catanzaro巨大的喊叫声,这对我来说是一次很棒的学习经历,这对我来说是一次很棒的学习经历部分卷积层和损失功能。

尝试使用此算法进行一些预测的最简单方法是访问www.fixmyphoto.ai,在那里我将其部署在带有AWS Lambda功能处理推理的无服务器React应用程序上。
如果要研究代码,则可以在libs/pconv_layer.py和libs/pconv_model.py中找到新的PConv2D KERAS层的主要实现以及使用这些部分卷积层的UNet型体系结构的主要实现。是可以找到大部分实施的地方。除此之外,我已经设置了四个Jupyter笔记本电脑,其中详细介绍了我在实施网络时通过的几个步骤:
步骤1:创建随机不规则面具
步骤2:实施和测试PConv2D层的实现
步骤3:使用PConv2D层实现和测试UNET体系结构
步骤4:培训和测试Imagenet的最终架构
步骤5:通过图像块预测任意图像大小的简单尝试
我已经将VGG16重量从Pytorch到Keras移植;这意味着1/255.与Pytorch类似,可以将Pixel缩放用于VGG16网络。
您可以直接转到步骤4笔记本电脑,也可以使用CLI(请确保下载转换后的VGG16权重):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
该实施的详细信息在本文本身中,但是我将尝试在此处汇总一些详细信息。
在论文中,他们使用了一种基于视频中两个连续帧之间的遮挡/分离来创建随机不规则掩模的技术 - 相反,我选择了简单地创建一个简单的掩码生成函数然后,我用于面具。但是,以后插入新的蒙版生成技术不应该是一个问题,我认为使用此方法的最终结果也很不错。
该实现的关键要素是部分卷积层。基本上,鉴于卷积过滤W和相应的偏置B ,应用以下部分卷积而不是正常卷积:
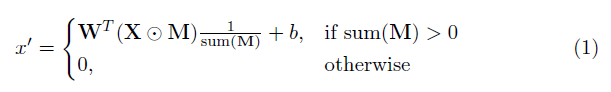
其中⊙是元素的乘法, m是0s和1s的二进制掩码。重要的是,在每个部分卷积之后,也更新了掩码,因此,如果卷积能够在至少一个有效输入上调节其输出,则在该位置删除掩码,即
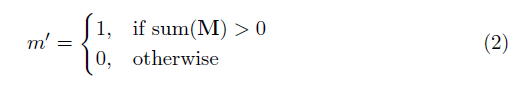
结果是,有了足够深的网络,掩模最终将是所有的(即消失)
该体系结构的具体细节可以在论文中找到,但本质上是基于类似于UNET的结构,在该结构中,所有正常的卷积层都被部分卷积层取代,因此在所有情况下,图像都通过网络与掩模一起通过网络。 。以下提供了体系结构的概述。 
本文中使用的损失函数有点强烈,可以在论文中进行审查。简而言之包括:
所有这些损失条款的加权如下: 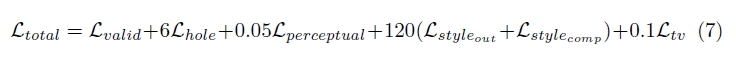
对网络的批量大小为1,对网络进行了培训,并且每个时期都被指定为10,000批次。此外,训练是在两个阶段使用ADAM优化器进行的,因为批次归一化提出了掩盖卷积的问题(因为计算了孔像素的平均值和方差)。
第1阶段的学习率为0.0001,对于50个时期
第2阶段的学习率为50个时期的0.00005,其中禁用了所有编码层中的批量归一化。
训练图像绝对疯狂,但这可能是因为我的个人设置不佳。我在1080TI上尝试的少数测试(批次大小为4)表明,训练时间可能约为10天,如论文所示。


