PConv Keras
1.0.0
การใช้งาน Keras ของ " Image Inpainting สำหรับหลุมที่ผิดปกติโดยใช้ convolutions บางส่วน ", https://arxiv.org/abs/1804.07723 เสียงตะโกนครั้งใหญ่ของผู้เขียน Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao และ Bryan Catanzaro จาก Nvidia Corporation เพื่อปล่อยกระดาษที่ยอดเยี่ยมนี้มันเป็นประสบการณ์การเรียนรู้ที่ยอดเยี่ยมสำหรับฉันที่จะนำสถาปัตยกรรมมาใช้ เลเยอร์ convolutional บางส่วนและฟังก์ชั่นการสูญเสีย

วิธีที่ง่ายที่สุดในการลองทำนายสองสามอย่างกับอัลกอริทึมนี้คือไปที่ www.fixmyphoto.ai ซึ่งฉันได้ปรับใช้กับแอปพลิเคชัน React ที่ไม่มีเซิร์ฟเวอร์ด้วย AWS Lambda ฟังก์ชั่นการจัดการการอนุมาน
หากคุณต้องการขุดลงในรหัสการใช้งานหลักของเลเยอร์ PConv2D KERAS ใหม่รวมถึงสถาปัตยกรรมที่มีลักษณะเหมือน UNet โดยใช้เลเยอร์ convolutional บางส่วนเหล่านี้สามารถพบได้ใน libs/pconv_layer.py และ libs/pconv_model.py ตามลำดับ เป็นที่ที่พบการใช้งานจำนวนมาก นอกเหนือจากนี้ฉันได้ตั้งค่าสมุดบันทึก Jupyter สี่รายการซึ่งมีรายละเอียดหลายขั้นตอนที่ฉันทำในขณะที่ใช้เครือข่ายคือ:
ขั้นตอนที่ 1: การสร้างหน้ากากที่ผิดปกติแบบสุ่ม
ขั้นตอนที่ 2: การใช้งานและทดสอบการใช้งานของเลเยอร์ PConv2D
ขั้นตอนที่ 3: การใช้และทดสอบสถาปัตยกรรม UNET ด้วยเลเยอร์ PConv2D
ขั้นตอนที่ 4: การฝึกอบรมและทดสอบสถาปัตยกรรมขั้นสุดท้ายบน ImageNet
ขั้นตอนที่ 5: ความพยายามแบบง่าย ๆ ในการทำนายขนาดภาพโดยพลการผ่านการถ่ายภาพ
ฉันได้รับน้ำหนัก VGG16 จาก Pytorch ไปยัง Keras; ซึ่งหมายความว่า 1/255. การปรับขนาดพิกเซลสามารถใช้สำหรับเครือข่าย VGG16 เช่นเดียวกับ Pytorch
คุณสามารถไปที่โน้ตบุ๊กขั้นตอนที่ 4 หรือใช้ CLI โดยตรง (ตรวจสอบให้แน่ใจว่าได้ดาวน์โหลดน้ำหนัก VGG16 ที่แปลงแล้ว):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
รายละเอียดของการใช้งานอยู่ในกระดาษเอง แต่ฉันจะพยายามสรุปรายละเอียดบางอย่างที่นี่
ในกระดาษพวกเขาใช้เทคนิคโดยใช้การบดเคี้ยว/การออกจากกันระหว่างสองเฟรมติดต่อกันในวิดีโอสำหรับการสร้างมาสก์ที่ผิดปกติแบบสุ่ม-แทนฉันเลือกที่จะสร้างฟังก์ชัน Generator หน้ากากอย่างง่ายซึ่งใช้ OpenCV เพื่อวาดรูปร่างที่ผิดปกติแบบสุ่ม จากนั้นฉันใช้สำหรับหน้ากาก การเสียบเทคนิคการสร้างหน้ากากใหม่ในภายหลังไม่ควรเป็นปัญหาและฉันคิดว่าผลลัพธ์สุดท้ายค่อนข้างดีในการใช้วิธีนี้เช่นกัน
องค์ประกอบสำคัญในการใช้งานนี้คือเลเยอร์ convolutional บางส่วน โดยพื้นฐานแล้วเนื่องจากตัวกรอง convolutional W และอคติที่สอดคล้องกัน B การ convolution บางส่วนต่อไปนี้จะถูกนำไปใช้แทนการ convolution ปกติ:
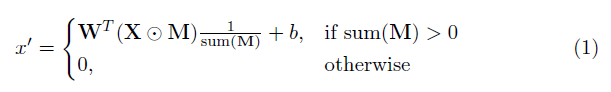
โดยที่⊙คือการคูณองค์ประกอบที่ชาญฉลาดและ m เป็นหน้ากากไบนารีของ 0s และ 1s ที่สำคัญหลังจากการประชุมบางส่วนบางส่วนหน้ากากจะได้รับการอัปเดตด้วยดังนั้นหากการแปลงสามารถปรับสภาพเอาต์พุตได้อย่างน้อยหนึ่งอินพุตที่ถูกต้องแล้วหน้ากากจะถูกลบออกในตำแหน่งนั้นเช่น
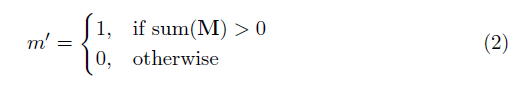
ผลที่ตามมาคือด้วยเครือข่ายที่ลึกพอสมควรหน้ากากจะเป็นคนทั้งหมด (เช่นหายไป)
รายละเอียดเฉพาะของสถาปัตยกรรมสามารถพบได้ในกระดาษ แต่โดยพื้นฐานแล้วมันขึ้นอยู่กับโครงสร้างที่คล้ายกับ UNET ซึ่งชั้น convolutional ปกติทั้งหมดจะถูกแทนที่ด้วยเลเยอร์ convolutional บางส่วนเช่นในทุกกรณีภาพจะถูกส่งผ่านเครือข่ายข้างหน้ากาก . ต่อไปนี้ให้ภาพรวมของสถาปัตยกรรม 
ฟังก์ชั่นการสูญเสียที่ใช้ในกระดาษนั้นค่อนข้างรุนแรงและสามารถตรวจสอบได้ในกระดาษ ในระยะสั้นรวมถึง:
การถ่วงน้ำหนักของเงื่อนไขการสูญเสียทั้งหมดเหล่านี้มีดังนี้: 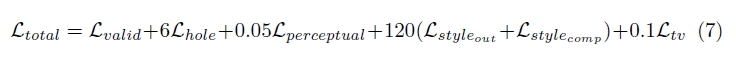
เครือข่ายได้รับการฝึกฝนเกี่ยวกับ Imagenet ที่มีขนาดแบทช์ 1 และแต่ละยุคถูกระบุว่ามีความยาว 10,000 แบตช์ การฝึกอบรมยังดำเนินการโดยใช้ Adam Optimizer ในสองขั้นตอนเนื่องจากการทำให้เป็นมาตรฐานแบบแบทช์แสดงปัญหาสำหรับการสวมหน้ากาก (เนื่องจากค่าเฉลี่ยและความแปรปรวนคำนวณสำหรับพิกเซลหลุม)
อัตราการเรียนรู้ ขั้นตอนที่ 1 ของ 0.0001 สำหรับ 50 Epochs ที่เปิดใช้งานแบทช์ปกติในทุกเลเยอร์
อัตราการเรียนรู้ ขั้นตอนที่ 2 ของ 0.00005 สำหรับ 50 Epochs ที่การทำให้เป็นมาตรฐานเป็นชุดในเลเยอร์การเข้ารหัสทั้งหมดถูกปิดใช้งาน
เวลาการฝึกซ้อมสำหรับภาพที่แสดงนั้นบ้าไปนานอย่างแน่นอน แต่นั่นอาจเป็นเพราะการตั้งค่าส่วนตัวที่ไม่ดีของฉัน การทดสอบไม่กี่ครั้งที่ฉันได้ลองใน 1080TI (ที่มีขนาดแบทช์ 4) บ่งชี้ว่าเวลาการฝึกอบรมอาจประมาณ 10 วันตามที่ระบุไว้ในกระดาษ


