PConv Keras
1.0.0
Implémentation de Keras de " Image Inspeinting pour des trous irréguliers à l'aide de convolutions partielles ", https://arxiv.org/abs/1804.07723. Un énorme cri des auteurs Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao et Bryan Catanzaro de Nvidia Corporation pour avoir publié ce journal génial, c'est une grande expérience d'apprentissage pour moi de mettre en œuvre l'architecture, la couche convolutionnelle partielle et les fonctions de perte.

La façon la plus simple d'essayer quelques prédictions avec cet algorithme est d'aller sur www.fixmyphoto.ai, où je l'ai déployé sur une application React sans serveur avec les fonctions AWS Lambda gantant l'inférence.
Si vous souhaitez creuser dans le code, les implémentations principales de la nouvelle couche PConv2D KERAS ainsi que l'architecture de type UNet à l'aide de ces calques convolutionnelles partielles peuvent être trouvées dans libs/pconv_layer.py et libs/pconv_model.py , respectivement - ce est l'endroit où la majeure partie de la mise en œuvre peut être trouvée. Au-delà de cela, j'ai mis en place quatre cahiers Jupyter, qui détaillent les plusieurs étapes que j'ai traversées lors de la mise en œuvre du réseau, à savoir:
Étape 1: Création de masques irréguliers aléatoires
Étape 2: Implémentation et test de la mise en œuvre de la couche PConv2D
Étape 3: Implémentation et test de l'architecture UNET avec les couches PConv2D
Étape 4: Formation et test de l'architecture finale sur ImageNet
Étape 5: Tentative simpliste de prédire les tailles d'image arbitraires à travers le secteur de l'image
J'ai porté les poids VGG16 de Pytorch à Keras; Cela signifie le 1/255. La mise à l'échelle des pixels peut être utilisée pour le réseau VGG16 similaire à Pytorch.
Vous pouvez soit accéder directement à l'étape 4, ou utiliser également la CLI (assurez-vous de télécharger les poids convertis VGG16):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
Les détails de la mise en œuvre sont dans le document lui-même, mais je vais essayer de résumer certains détails ici.
Dans l'article, ils utilisent une technique basée sur l'occlusion / la désocclusion entre deux trames consécutives dans des vidéos pour créer des masques irréguliers aléatoires - j'ai plutôt opté pour simplement la création d'une fonction de générateur de masque simple qui utilise OpenCV pour dessiner des formes irrégulières aléatoires qui J'utilise ensuite pour les masques. Il ne devrait cependant pas être un problème, et je pense que les résultats finaux sont également assez décents en utilisant cette méthode.
Un élément clé de cette implémentation est la couche de convolution partielle. Fondamentalement, étant donné le filtre convolutionnel W et le biais correspondant B , la convolution partielle suivante est appliquée au lieu d'une convolution normale:
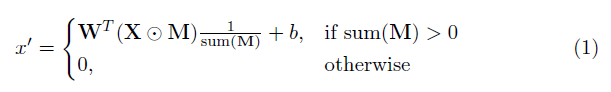
où ⊙ est la multiplication par élément et m est un masque binaire de 0 et 1. Surtout, après chaque convolution partielle, le masque est également mis à jour, de sorte que si la convolution a pu conditionner sa sortie sur au moins une entrée valide, le masque est supprimé à cet endroit, c'est-à-dire
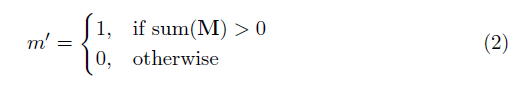
Le résultat est qu'avec un réseau suffisamment profond, le masque sera finalement tout (c'est-à-dire disparaître)
Des détails spécifiques de l'architecture peuvent être trouvés dans l'article, mais essentiellement il est basé sur une structure de type non-non, où toutes les couches convolutionnelles normales sont remplacées par des couches convolutionnelles partielles, de sorte que dans tous les cas, l'image passe par le réseau à côté du masque . Ce qui suit donne un aperçu de l'architecture. 
La fonction de perte utilisée dans le document est un peu intense et peut être examinée dans le document. En bref, il comprend:
La pondération de tous ces termes de perte est la suivante: 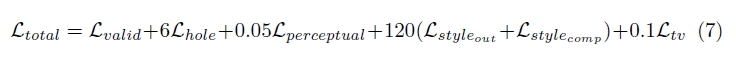
Le réseau a été formé sur ImageNet avec une taille de lot de 1, et chaque époque a été spécifiée comme étant de 10 000 lots. La formation a en outre été effectuée en utilisant l'optimiseur ADAM en deux étapes, car la normalisation par lots présente un problème pour les convolutions masquées (car la moyenne et la variance sont calculées pour les pixels du trou).
Taux d'apprentissage de l'étape 1 de 0,0001 pour 50 époques avec normalisation par lots activés dans toutes les couches
Le taux d'apprentissage de l'étape 2 de 0,00005 pour 50 époques où la normalisation par lots dans toutes les couches de codage est désactivé.
Le temps de formation pour les images montrés était absolument fou, mais c'est probablement à cause de ma mauvaise configuration personnelle. Les quelques tests que j'ai essayés sur un 1080ti (avec une taille de lot de 4) indiquent que le temps de formation pourrait être d'environ 10 jours, comme spécifié dans le document.


