PConv Keras
1.0.0
Implementação de Keras de " Imagem que inclua orifícios irregulares usando convoluções parciais ", https://arxiv.org/abs/1804.07723. Um grande grito dos autores Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao e Bryan Catanzaro da Nvidia Corporation para lançar este artigo incrível, tem sido uma ótima experiência de aprendizado para implementar a arquitetura, a camada convolucional parcial e as funções de perda.

A maneira mais fácil de tentar algumas previsões com esse algoritmo é ir para www.fixmyphoto.ai, onde o implantei em um aplicativo REACT sem servidor com as funções da AWS Lambda que lidam com a inferência.
Se você quiser cavar o código, as principais implementações da nova camada de Keras PConv2D , bem como a arquitetura do tipo UNet usando essas camadas convolucionais parciais, podem ser encontradas em libs/pconv_layer.py e libs/pconv_model.py , respectivamente - this é onde a maior parte da implementação pode ser encontrada. Além disso, criei quatro notebooks Jupyter, que detalham as várias etapas pelas quais eu passo ao implementar a rede, a saber:
Etapa 1: Criando máscaras irregulares aleatórias
Etapa 2: Implementando e testando a implementação da camada PConv2D
Etapa 3: Implementando e testando a arquitetura UNET com camadas PConv2D
Etapa 4: Treinando e testando a arquitetura final no ImageNet
Etapa 5: Tentativa simplista de prever tamanhos de imagem arbitrários através de chunking de imagem
Eu porguei os pesos VGG16 de Pytorch para Keras; Isso significa o 1/255. A escala de pixel pode ser usada para a rede VGG16 de maneira semelhante ao Pytorch.
Você pode ir diretamente para a etapa 4 notebook ou usar alternativamente a CLI (certifique -se de baixar os pesos VGG16 convertidos):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
Os detalhes da implementação estão no próprio artigo, no entanto, tentarei resumir alguns detalhes aqui.
No artigo, eles usam uma técnica baseada na oclusão/disclusão entre dois quadros consecutivos em vídeos para criar máscaras irregulares aleatórias-em vez disso, optei por simplesmente criar uma função simples de gerador de máscara que usa OpenCV para desenhar algumas formas irregulares aleatórias que Eu então uso para máscaras. A conectar uma nova técnica de geração de máscara posteriormente não deve ser um problema, e acho que os resultados finais são bastante decentes usando esse método também.
Um elemento -chave nesta implementação é a camada convolucional parcial. Basicamente, dado o filtro convolucional W e o viés correspondente B , a seguinte convolução parcial é aplicada em vez de uma convolução normal:
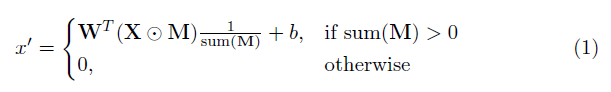
onde ⊙ é multiplicação no elemento e m é uma máscara binária de 0s e 1s. É importante ressaltar que, após cada convolução parcial, a máscara também é atualizada, de modo que, se a convolução foi capaz de condicionar sua saída em pelo menos uma entrada válida, a máscara é removida nesse local, ou seja,
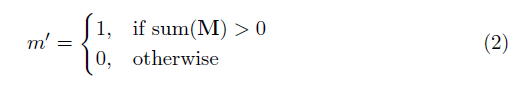
O resultado disso é que, com uma rede suficientemente profunda, a máscara acabará sendo todos (ou seja, desaparecerá)
Detalhes específicos da arquitetura podem ser encontrados no artigo, mas essencialmente é baseado em uma estrutura do tipo inadequada, onde todas as camadas convolucionais normais são substituídas por camadas convolucionais parciais, de modo que em todos os casos a imagem é passada pela rede ao lado da máscara . A seguir, fornece uma visão geral da arquitetura. 
A função de perda usada no artigo é meio intensa e pode ser revisada no artigo. Em resumo, inclui:
A ponderação de todos esses termos de perda é os seguintes: 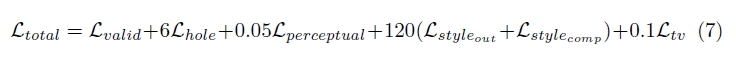
A rede foi treinada no Imagenet com um tamanho de lotes de 1 e cada época foi especificada como 10.000 lotes de comprimento. Além disso, o treinamento foi realizado usando o otimizador Adam em dois estágios, pois a normalização do lote apresenta um problema para as convoluções mascaradas (uma vez que a média e a variação são calculadas para pixels de furo).
Taxa de aprendizado do estágio 1 de 0,0001 para 50 épocas com normalização em lote ativada em todas as camadas
Taxa de aprendizado em estágio 2 de 0,00005 para 50 épocas, onde a normalização do lote em todas as camadas de codificação está desativada.
O tempo de treinamento para as imagens mostradas era absolutamente louco por muito tempo, mas isso é provável por causa da minha má configuração pessoal. Os poucos testes que tentei em um 1080Ti (com tamanho de lote de 4) indicam que o tempo de treinamento pode ser de cerca de 10 dias, conforme especificado no papel.


