PConv Keras
1.0.0
تنفيذ keras لـ " Image inpainting للثقوب غير المنتظمة باستخدام تلوينات جزئية " ، https://arxiv.org/abs/1804.07723. صراخًا كبيرًا للمؤلفين Guilin Liu و Fitsum A. Reda و Kevin J. Shih و Ting-Chun Wang و Andrew Tao و Bryan Catanzaro من Nvidia Corporation لإصدار هذه الورقة الرائعة ، لقد كانت تجربة تعليمية رائعة بالنسبة لي لتنفيذ الهندسة المعمارية ، الطبقة التلافيفية الجزئية ، وظائف الخسارة.

أسهل طريقة لتجربة بعض التنبؤات مع هذه الخوارزمية هي الذهاب إلى www.fixmyphoto.ai ، حيث قمت بنشرها على تطبيق رد فعل بدون خادم مع وظائف AWS Lambda معالجة الاستدلال.
إذا كنت ترغب في البحث في الكود ، فيمكن العثور على التطبيقات الأساسية لطبقة Keras PConv2D الجديدة بالإضافة إلى البنية التي تشبه UNet باستخدام هذه الطبقات التلافيفية الجزئية في libs/pconv_layer.py و libs/pconv_model.py ، على التوالي - هذا هو المكان الذي يمكن العثور على الجزء الأكبر من التنفيذ. علاوة على ذلك ، قمت بإعداد أربعة أجهزة كمبيوتر محمولة Jupyter ، والتي تفصل الخطوات العديدة التي مررت بها أثناء تنفيذ الشبكة ، وهي:
الخطوة 1: إنشاء أقنعة غير منتظمة عشوائية
الخطوة 2: تنفيذ واختبار تنفيذ طبقة PConv2D
الخطوة 3: تنفيذ واختبار بنية UNET مع طبقات PConv2D
الخطوة 4: التدريب واختبار الهندسة المعمارية النهائية على ImageNet
الخطوة 5: محاولة التبسيطية للتنبؤ بأحجام الصور التعسفية من خلال تصحيح الصورة
لقد قمت بنقل أوزان VGG16 من Pytorch إلى Keras ؛ وهذا يعني 1/255. يمكن استخدام قياس البيكسل لشبكة VGG16 بشكل مشابه لـ Pytorch.
يمكنك إما الانتقال مباشرةً إلى دفتر Notes STEP 4 ، أو بدلاً من ذلك استخدام CLI (تأكد من تنزيل أوزان VGG16 المحولة):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
تفاصيل التنفيذ موجودة في الورقة نفسها ، ومع ذلك سأحاول تلخيص بعض التفاصيل هنا.
في الورقة ، يستخدمون تقنية تعتمد على انسداد/عدم الانسحاب بين إطارين متتاليين في مقاطع الفيديو لإنشاء أقنعة غير منتظمة عشوائية-بدلاً من ذلك ، اخترت ببساطة إنشاء وظيفة من مولد القناع البسيطة التي تستخدم OpenCV لرسم بعض الأشكال غير المنتظمة العشوائية التي أنا ثم استخدام الأقنعة. لا ينبغي أن يكون توصيل تقنية توليد قناع جديدة لاحقًا مشكلة ، وأعتقد أن النتائج النهائية لائقة إلى حد ما باستخدام هذه الطريقة أيضًا.
العنصر الرئيسي في هذا التنفيذ هو الطبقة التلافيفية الجزئية. في الأساس ، بالنظر إلى المرشح التلافييل W والتحيز المقابل B ، يتم تطبيق الالتفاف الجزئي التالي بدلاً من الالتفاف الطبيعي:
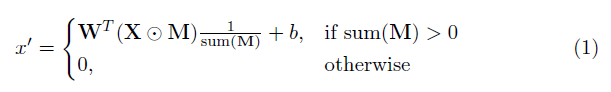
حيث ⊙ هو الضرب العناصر و M هو قناع ثنائي 0s و 1s. الأهم من ذلك ، بعد كل إيلاء جزئي ، يتم تحديث القناع أيضًا ، بحيث إذا كان الالتواء قادرًا على إجراء إخراجه على مدخلات صالحة واحدة على الأقل ، فسيتم إزالة القناع في هذا الموقع ، أي
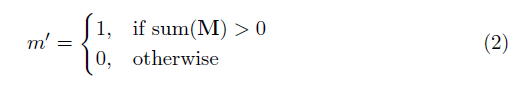
والنتيجة هي أنه مع شبكة عميقة بما فيه الكفاية ، سيكون القناع في نهاية المطاف (أي اختفاء)
يمكن العثور على تفاصيل محددة للهندسة المعمارية في الورقة ، ولكن بشكل أساسي تستند إلى بنية شبيهة بالوحدة ، حيث يتم استبدال جميع الطبقات التلافيفية العادية بطبقات تلغيرات جزئية ، بحيث يتم تمرير الصورة في جميع الحالات عبر الشبكة إلى جانب القناع . ما يلي يوفر نظرة عامة على الهندسة المعمارية. 
وظيفة الخسارة المستخدمة في الورقة مكثفة نوعًا ما ، ويمكن مراجعتها في الورقة. باختصار يشمل:
إن ترجيح كل مصطلحات الخسارة هذه على النحو التالي: 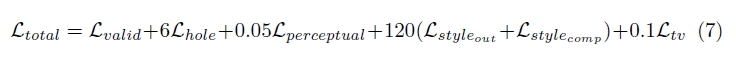
تم تدريب الشبكة على ImageNet بحجم دفعة 1 ، وتم تحديد كل عصر لتكون 10000 دفعة. تم تنفيذ التدريب علاوة على ذلك باستخدام Optimizer ADAM على مرحلتين نظرًا لأن تطبيع الدُفعات يمثل مشكلة للتلوين المقنعة (حيث يتم حساب المتوسط والتباين لبكسل الثقب).
معدل التعلم من المرحلة الأولى البالغ 0.0001 لـ 50 عصرًا مع تمكين تطبيع الدُفعات في جميع الطبقات
المرحلة 2 معدل التعلم من 0.00005 ل 50 عصر حيث يتم تعطيل تطبيع الدفعة في جميع طبقات الترميز.
كان وقت التدريب للصور المعروضة مجنونة طويلة للغاية ، ولكن هذا من المحتمل أن يكون ذلك بسبب الإعداد الشخصي السيئ. تشير الاختبارات القليلة التي جربتها على 1080TI (بحجم الدُفعة 4) إلى أن وقت التدريب قد يكون حوالي 10 أيام ، كما هو محدد في الورقة.


