PConv Keras
1.0.0
Implementación de Keras de " Inpaña de imagen para agujeros irregulares utilizando convoluciones parciales ", https://arxiv.org/abs/1804.07723. Un gran agradecimiento a los autores Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao y Bryan Catanzaro de Nvidia Corporation por lanzar este increíble artículo, ha sido una gran experiencia de aprendizaje para mí implementar la arquitectura, la capa convolucional parcial y las funciones de pérdida.

La forma más fácil de probar algunas predicciones con este algoritmo es ir a www.fixmyphoto.ai, donde la he implementado en una aplicación React sin servidor con las funciones de AWS Lambda manejo de inferencia.
Si desea profundizar en el código, las implementaciones principales de la nueva capa de Keras PConv2D , así como la arquitectura similar a UNet utilizando estas capas convolucionales parciales, se pueden encontrar en libs/pconv_layer.py y libs/pconv_model.py , respectivamente, esto, esto es donde se puede encontrar la mayor parte de la implementación. Más allá de esto, configuré cuatro cuadernos Jupyter, que detalla los varios pasos que pasé al implementar la red, a saber:
Paso 1: Crear máscaras irregulares aleatorias
Paso 2: Implementación y prueba de la implementación de la capa PConv2D
Paso 3: Implementación y prueba de la arquitectura de unlo con capas PConv2D
Paso 4: Entrenamiento y prueba de la arquitectura final en Imagenet
Paso 5: Intento simplista de predecir los tamaños de imagen arbitrarios a través de la fragmentación de imágenes
He portado los pesos VGG16 de Pytorch a Keras; Esto significa el 1/255. La escala de píxeles se puede usar para la red VGG16 de manera similar a Pytorch.
Puede ir directamente al cuaderno del paso 4 o, alternativamente, usar la CLI (asegúrese de descargar los pesos VGG16 convertidos):
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
Los detalles de la implementación están en el documento en sí, sin embargo, intentaré resumir algunos detalles aquí.
En el documento, utilizan una técnica basada en la oclusión/desaclusión entre dos cuadros consecutivos en videos para crear máscaras irregulares aleatorias; en su lugar, he optado por simplemente crear una función de generador de máscara simple que usa OpenCV para dibujar algunas formas irregulares aleatorias que Luego uso para máscaras. Sin embargo, enchufar una nueva técnica de generación de máscaras no debería ser un problema, y creo que los resultados finales también son bastante decentes utilizando este método.
Un elemento clave en esta implementación es la capa convolucional parcial. Básicamente, dado el filtro convolucional w y el sesgo correspondiente B , se aplica la siguiente convolución parcial en lugar de una convolución normal:
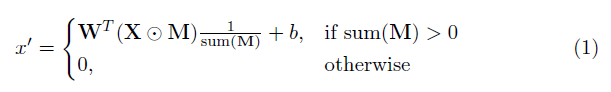
donde ⊙ es la multiplicación en términos de elementos y M es una máscara binaria de 0s y 1s. Es importante destacar que, después de cada convolución parcial, la máscara también se actualiza, de modo que si la convolución pudo acondicionar su salida en al menos una entrada válida, entonces la máscara se elimina en esa ubicación, es decir,
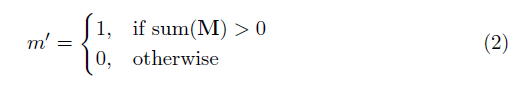
El resultado de esto es que con una red suficientemente profunda, la máscara eventualmente será todas (es decir, desaparecer)
Los detalles específicos de la arquitectura se pueden encontrar en el documento, pero esencialmente se basan en una estructura similar a un metro, donde todas las capas convolucionales normales se reemplazan con capas convolucionales parciales, de modo que en todos los casos la imagen se pasa a través de la red junto a la máscara . Lo siguiente proporciona una visión general de la arquitectura. 
La función de pérdida utilizada en el documento es un poco intensa y se puede revisar en el documento. En resumen, incluye:
La ponderación de todos estos términos de pérdida es el siguiente: 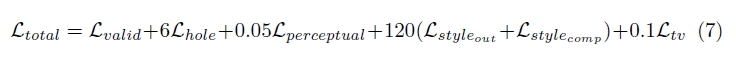
La red fue entrenada en Imagenet con un tamaño por lotes de 1, y cada época se especificó como de 10,000 lotes de largo. Además, el entrenamiento se realizó utilizando el Optimizer Adam en dos etapas, ya que la normalización por lotes presenta un problema para las convoluciones enmascaradas (ya que la media y la varianza se calculan para los píxeles de agujeros).
Tasa de aprendizaje de etapa 1 de 0.0001 para 50 épocas con normalización por lotes habilitados en todas las capas
Tasa de aprendizaje de etapa 2 de 0.00005 para 50 épocas donde la normalización por lotes en todas las capas de codificación está deshabilitada.
El tiempo de entrenamiento para las imágenes mostradas fue absolutamente loca, pero eso es probable que sea por mi mala configuración personal. Las pocas pruebas que he probado en un 1080TI (con un tamaño de lote de 4) indican que el tiempo de entrenamiento podría ser de alrededor de 10 días, como se especifica en el papel.


