PConv Keras
1.0.0
Keras는 " 부분적인 컨볼 루션을 사용한 불규칙한 구멍에 대한 이미지 입력 "의 keras 구현, https://arxiv.org/abs/1804.07723. 저자 Guilin Liu, Fitum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao 및 Nvidia Corporation의 Bryan Catanzaro 가이 멋진 논문을 발표 한 대규모 소리로 건축을 구현하는 것은 훌륭한 학습 경험이었습니다. 부분 컨볼 루션 층 및 손실 기능.

이 알고리즘으로 몇 가지 예측을 시도하는 가장 쉬운 방법은 www.fixmyphoto.ai로 이동하여 AWS Lambda 기능을 사용하여 Serverless React Application에 배포 한 것입니다.
코드를 파헤치려면 새로운 PConv2D KERAS 계층의 주요 구현과 이러한 부분 컨볼 루션 레이어를 사용하는 UNet 유사 아키텍처는 각각 libs/pconv_layer.py 및 libs/pconv_model.py 에서 찾을 수 있습니다. 구현의 대부분을 찾을 수있는 곳입니다. 이 외에도 4 개의 Jupyter 노트북을 설정했습니다.이 노트북은 네트워크를 구현하는 동안 여러 단계를 자세히 설명합니다.
1 단계 : 임의 불규칙한 마스크 생성
2 단계 : PConv2D 계층 구현 구현 및 테스트
3 단계 : PConv2D 층으로 UNET 아키텍처 구현 및 테스트
4 단계 : Imagenet의 최종 아키텍처 교육 및 테스트
5 단계 : 이미지 청킹을 통해 임의의 이미지 크기를 예측하려는 단순한 시도
나는 Pytorch에서 Keras로 VGG16 무게를 포팅했습니다. 이것은 1/255. Pytorch와 유사하게 VGG16 네트워크에 픽셀 스케일링을 사용할 수 있습니다.
4 단계 노트북으로 직접 이동하거나 CLI를 사용할 수 있습니다 (변환 된 VGG16 가중치를 다운로드하십시오).
python main.py
--name MyDataset
--train TRAINING_PATH
--validation VALIDATION_PATH
--test TEST_PATH
--vgg_path './data/logs/pytorch_to_keras_vgg16.h5'
구현에 대한 자세한 내용은 논문 자체에 있지만 여기에 몇 가지 세부 사항을 요약하려고합니다.
이 논문에서 그들은 임의의 불규칙한 마스크를 만들기 위해 비디오의 두 연속 프레임 사이의 폐색/혼합을 기반으로하는 기술을 사용합니다. 그런 다음 마스크에 사용합니다. 나중에 새로운 마스크 생성 기술을 연결하는 것은 문제가되지 않아야하며, 최종 결과는이 방법을 사용하여 상당히 괜찮다고 생각합니다.
이 구현의 핵심 요소는 부분 컨볼 루션 레이어입니다. 기본적으로, 컨볼 루션 필터 W 및 해당 바이어스 B 를 고려할 때, 다음 부분 컨볼 루션이 정상적인 컨볼 루션 대신 적용됩니다.
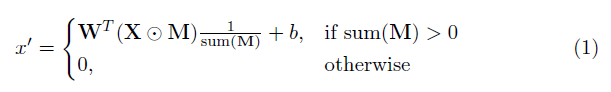
여기서 multip는 요소 별 곱셈이고 M은 0과 1의 이진 마스크입니다. 중요하게도, 각 부분 컨볼 루션 후에 마스크도 업데이트되므로 컨퍼런스가 적어도 하나의 유효한 입력에서 출력을 조절할 수 있으면 마스크가 해당 위치에서 제거됩니다.
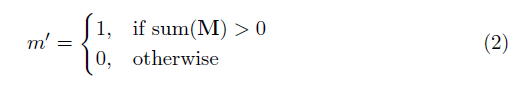
결과는 충분히 깊은 네트워크를 사용하면 마스크가 결국 모든 네트워크가 될 것입니다 (즉, 사라집니다)
아키텍처의 구체적인 세부 사항은 논문에서 찾을 수 있지만 본질적으로는 모든 정상적인 컨볼 루션 레이어가 부분 컨볼 루션 레이어로 대체되는 Unet-kike 구조를 기반으로합니다. . 다음은 아키텍처에 대한 개요를 제공합니다. 
논문에 사용 된 손실 기능은 다소 강하며 논문에서 검토 할 수 있습니다. 요컨대에는 다음이 포함됩니다.
이 모든 손실 용어의 가중치는 다음과 같습니다. 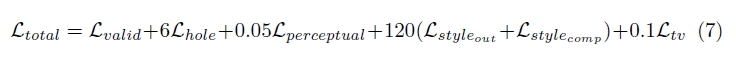
네트워크는 배치 크기가 1 인 Imagenet에 대한 교육을 받았으며 각 에포크는 10,000 배치 길이로 지정되었습니다. 배치 정규화는 마스크 된 컨볼 루션에 대한 문제를 제시하기 때문에 두 단계로 Adam Optimizer를 사용하여 훈련을 수행했습니다 (홀 픽셀에 대해 평균 및 분산이 계산되기 때문에).
1 단계 학습 속도는 모든 레이어에서 배치 정규화가 활성화 된 50 개의 에포크에 대해 0.0001입니다.
모든 인코딩 층에서의 배치 정규화가 비활성화되는 50 개의 에포크에 대해 2 단계 학습 속도 0.00005.
표시된 이미지에 대한 훈련 시간은 절대적으로 미쳤지 만 개인 설정이 좋지 않기 때문일 수 있습니다. 내가 1080TI (배치 크기 4 인)에서 시도한 몇 가지 테스트는 논문에 지정된대로 훈련 시간이 약 10 일이 될 수 있음을 나타냅니다.


