tf transformer
1.0.0
这是Tonsorflow 2.x变压器模型的实现(您需要注意的是您需要的)神经机器翻译(NMT)。
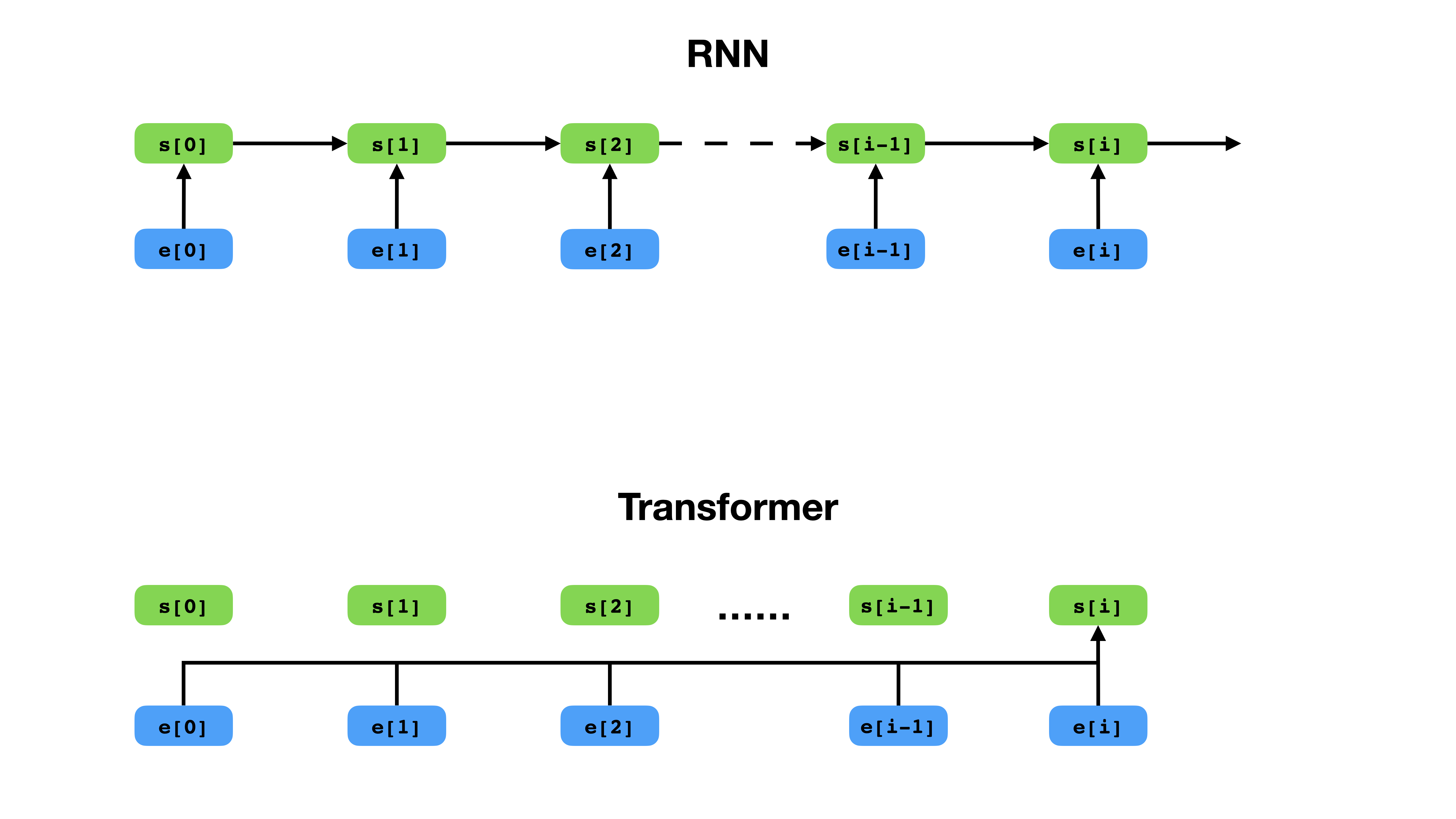
与RNN相比,变压器具有更灵活的表示上下文的方式。
变形金刚是用于序列建模的深度神经网络体系结构,这是根据其文本上下文估算序列中令牌可能性的任务。尽管复发性神经网络将上下文令牌的整个历史记录的嵌入到单个向量中,但无论上下文跨越多远,变形金刚都可以访问每个单个令牌的嵌入向量。这使其非常适合建模长距离依赖关系,这是文本表示学习方法(例如BERT和GPT-2)的最新突破的关键。
变形金刚的核心是自我发挥作用机制,其目标是通过让他们彼此“注意”来计算每个令牌的上下文表示。 Given the initial vector representations e[i] for all positions i , it first applies linear projections to obtain vectors q[i] , k[i] , v[i] , where k 's and v 's play the role of the key and value of a knowledge base about the sequence content, which is to be queried by q[i] to determine which tokens are most similar to the token at index i .查询的结果仅仅是q[i]和k (通常是点产品)之间的相似性得分,这些分数被用作权重,以计算v的加权平均值作为e[i]的新表示。请注意, q , k和v源自相同的序列,这意味着该序列有效地查询自己(因此名称自我注意)。
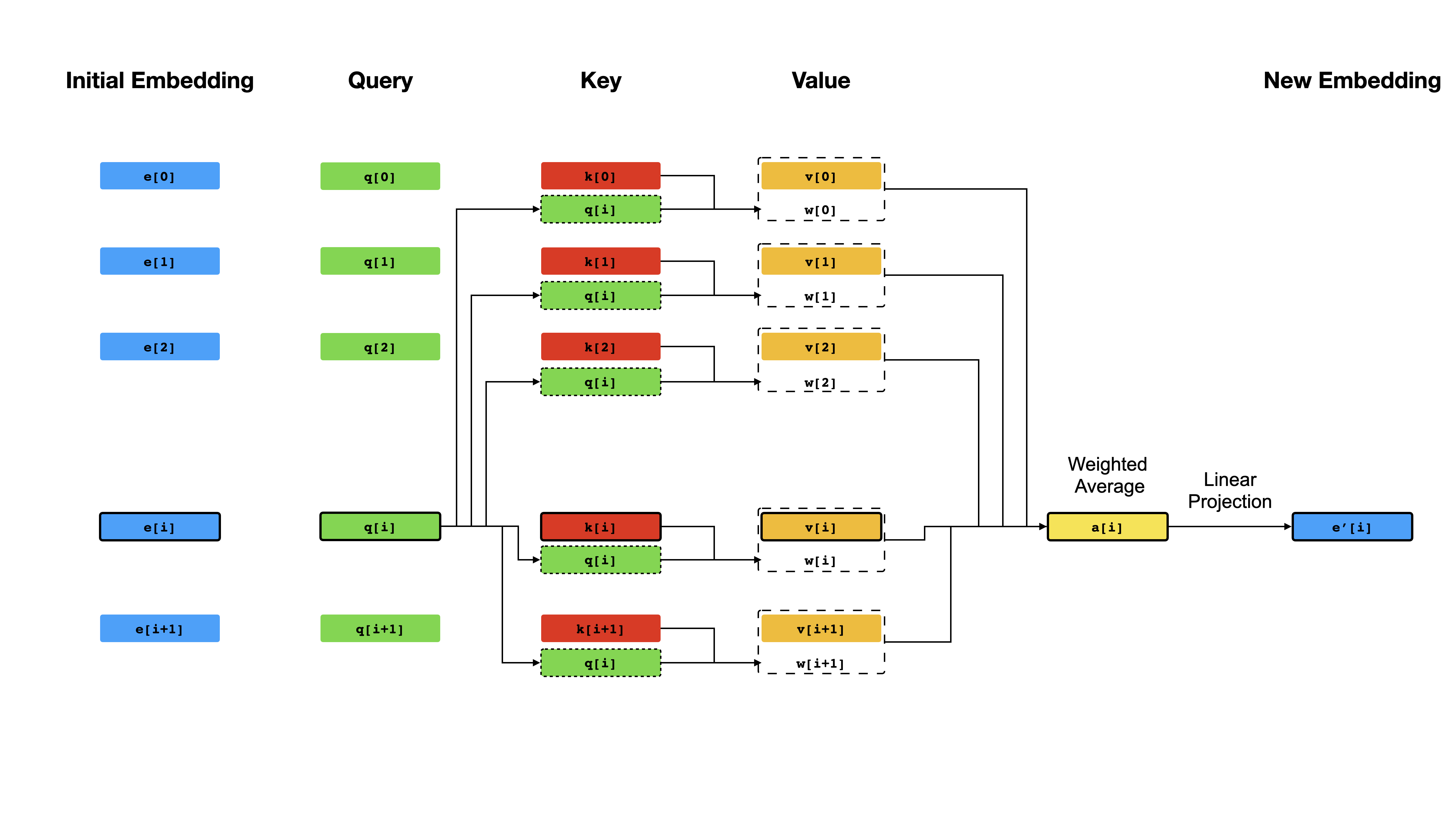
自我注意机制。
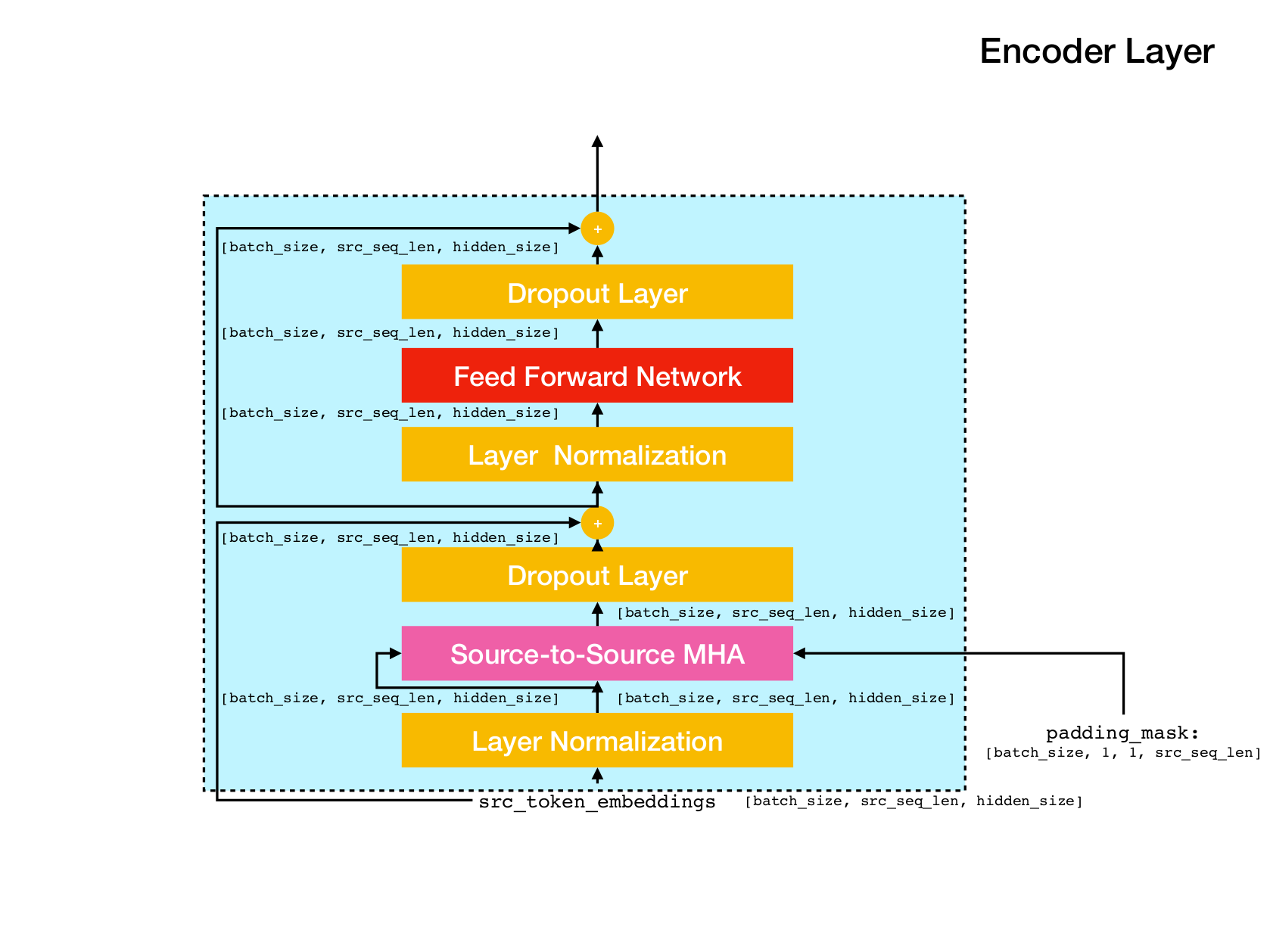
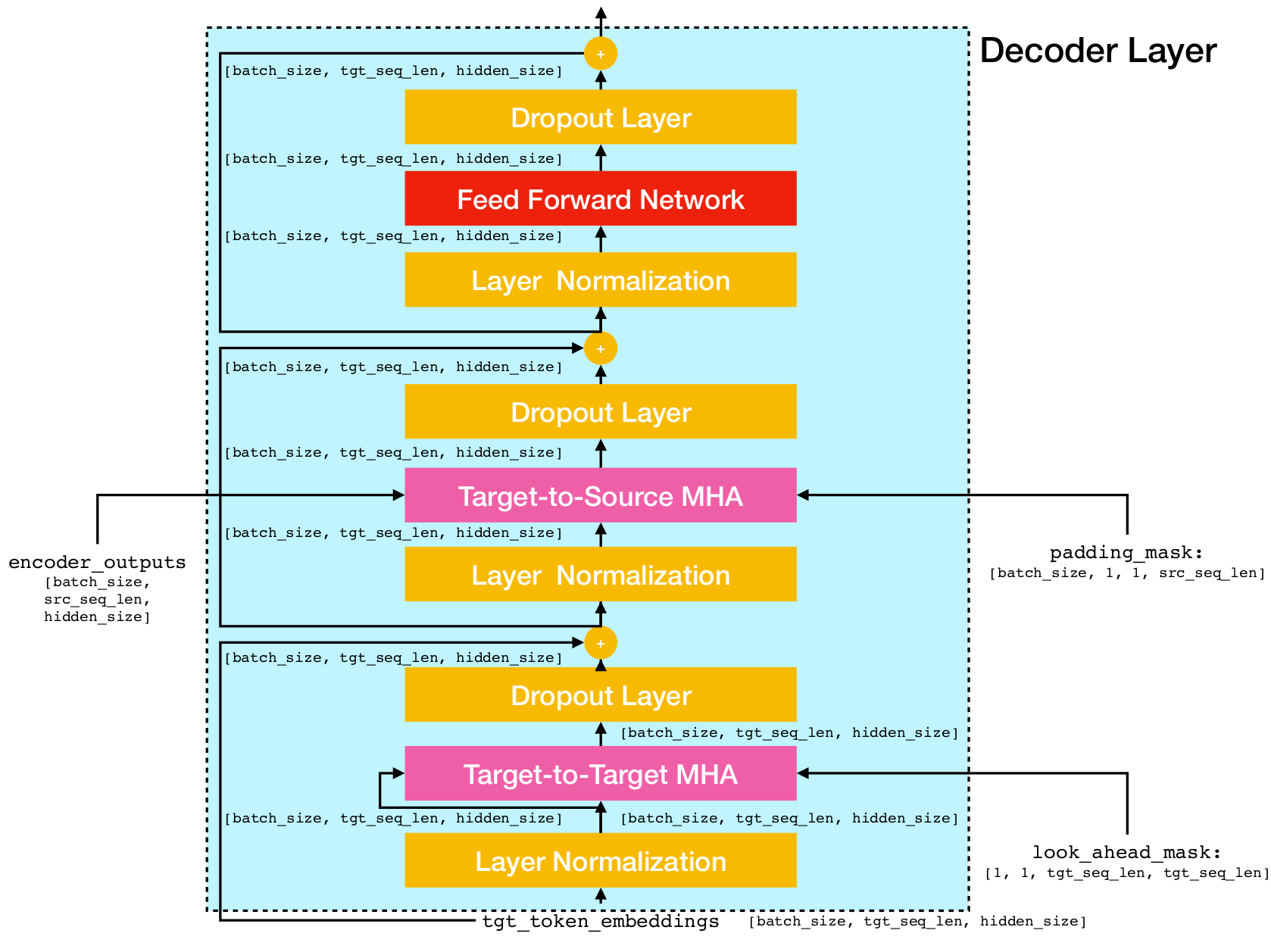
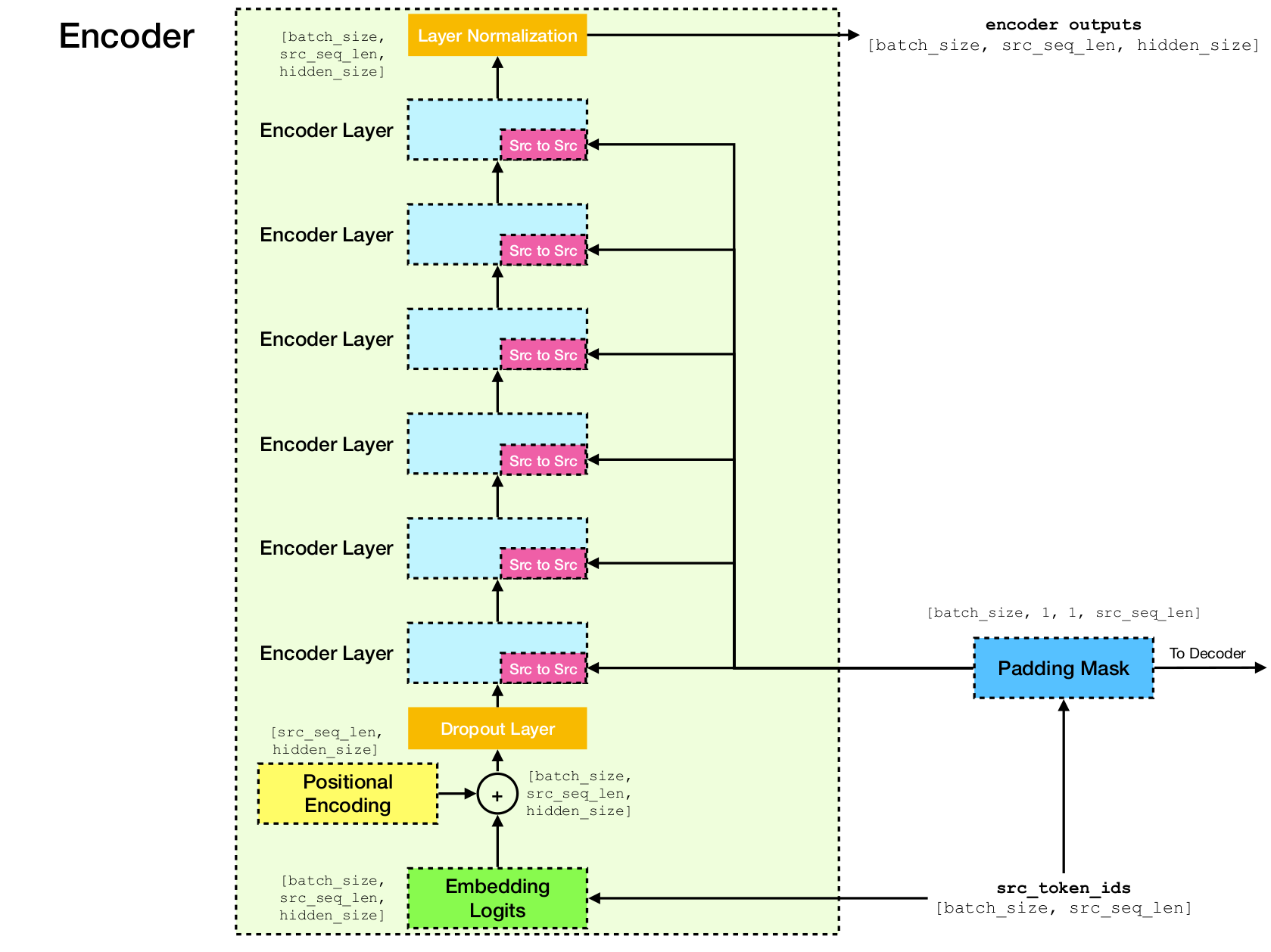
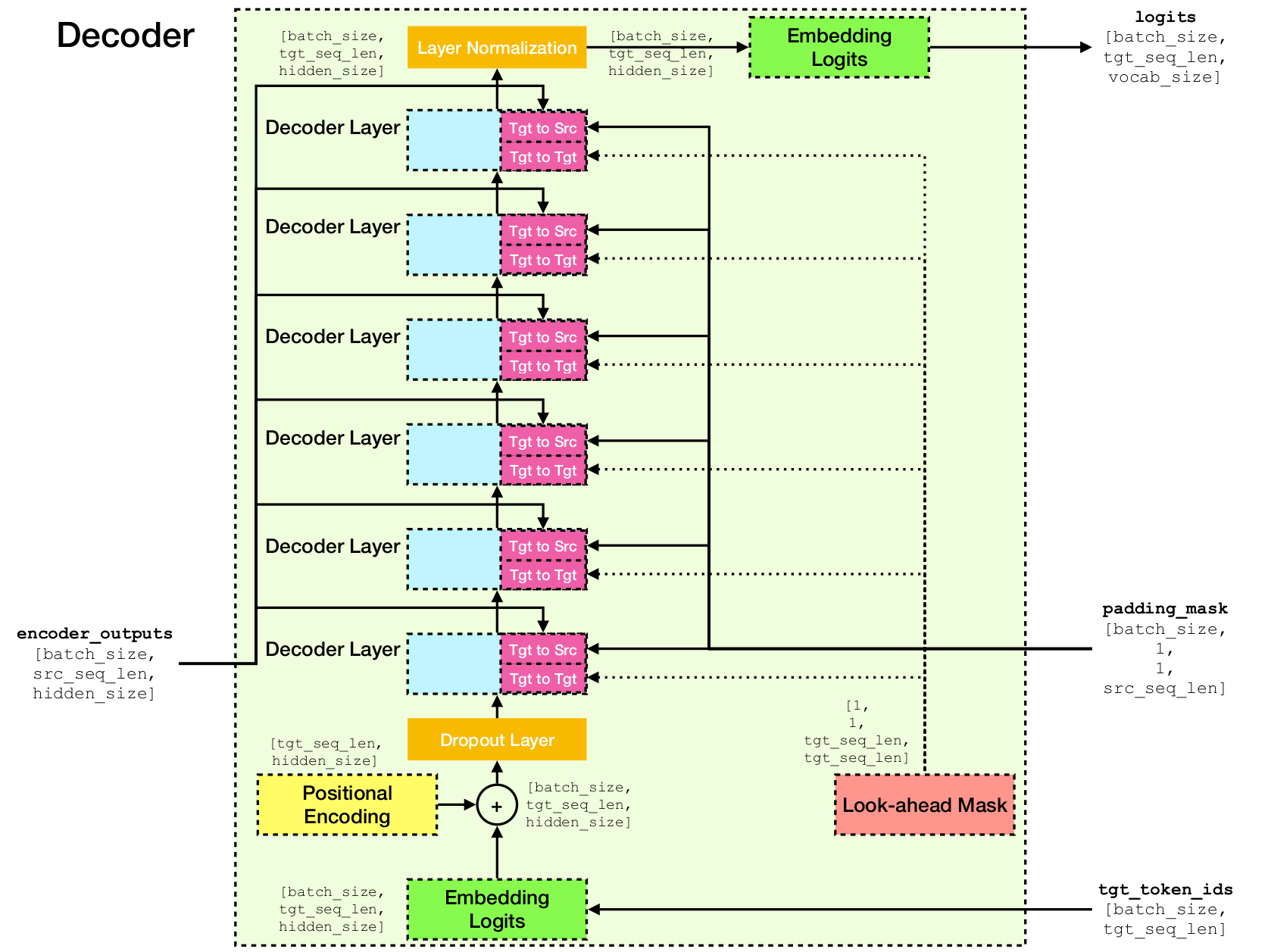
变压器网络体系结构。
该实现基于Tensorflow 2.x和Python3。此外,需要NLTK来计算BLEU评分进行评估。
您可以通过运行来克隆此存储库
git clone [email protected]:chao-ji/tf-transformer.git然后克隆并通过运行来更新子模块
cd tf-transformer
git submodule update --init --recursive培训语料库应采用源语言的文本文件列表的形式,并与目标语言中的文本文件列表配对,其中源语言文本文件中的行(IE句子)具有与目标语言文本文件中的行的一对一信件
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
首先,您需要通过运行将原始文本文件转换为tfrecord文件
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab注意:此过程涉及从培训语料库中“学习”子字代币的词汇,该子词将其保存到vocab.subtokens和vocab.alphabet中。词汇将稍后用于将原始文本字符串编码为子字代币ID,或将其解码回原始文本字符串。
有关详细的用法信息,请运行
python commons/create_tfrecord_machine_translation.py --help有关示例数据,请参阅data_sources.txt
训练模型,运行
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir is the directory storing the TFRecord files, vocab_path is the path to the basename of the vocabulary files vocab.subtokens and vocab.alphabet (ie path to vocab ) generated by running create_tfrecord_machine_translation.py , and model_dir is the directory that checkpoint files will be saved to (or loaded from if training is resumed from a previous checkpoint).
有关详细的用法信息,请运行
python run_trainer.py --help评估涉及将源序列转换为目标序列,并计算预测目标和地面目标序列之间的BLEU评分。
为了评估预贴模型,运行
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename和target_text_filename分别是保存源和目标序列的文本文件的路径。
请注意,命令行参数target_text_filename是可选的 - 如果排除在外,则评估器将在推理模式下运行,其中仅将翻译写入输出文件。
有关更详细的用法信息,请运行
python run_evaluator.py --help请注意,注意机制计算了可以可视化的令牌与犯罪的相似性,以了解如何在不同令牌上分布注意力。当您运行python run_evaluator.py时,注意力矩阵将被保存到attention_xxxx.npy ,其中存储以下条目:
src :形状的numpy阵列[batch_size, src_seq_len] ,其中每一行都是以1( EOS_ID )结尾并用零填充的令牌ID序列。tgt :形状的numpy阵列[batch_size, tgt_seq_len] ,其中每一行都是以1( EOS_ID )结尾的令牌ID序列,并用零填充。src_src_attention :形状的numpy阵列[batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention :形状的numpy阵列[batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention :形状的numpy阵列[batch_size, num_heads, tgt_seq_len, tgt_seq_len]注意力可以通过运行来显示:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files其中, head是[0, num_heads - 1]中的整数,而index是[0, batch_size - 1]中的整数。
下面显示的是英语(源语言)的三个句子及其用德语(目标语言)的翻译。
来源langauge中的输入句子
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
用目标语言翻译句子
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
变压器模型计算三种类型的注意力:
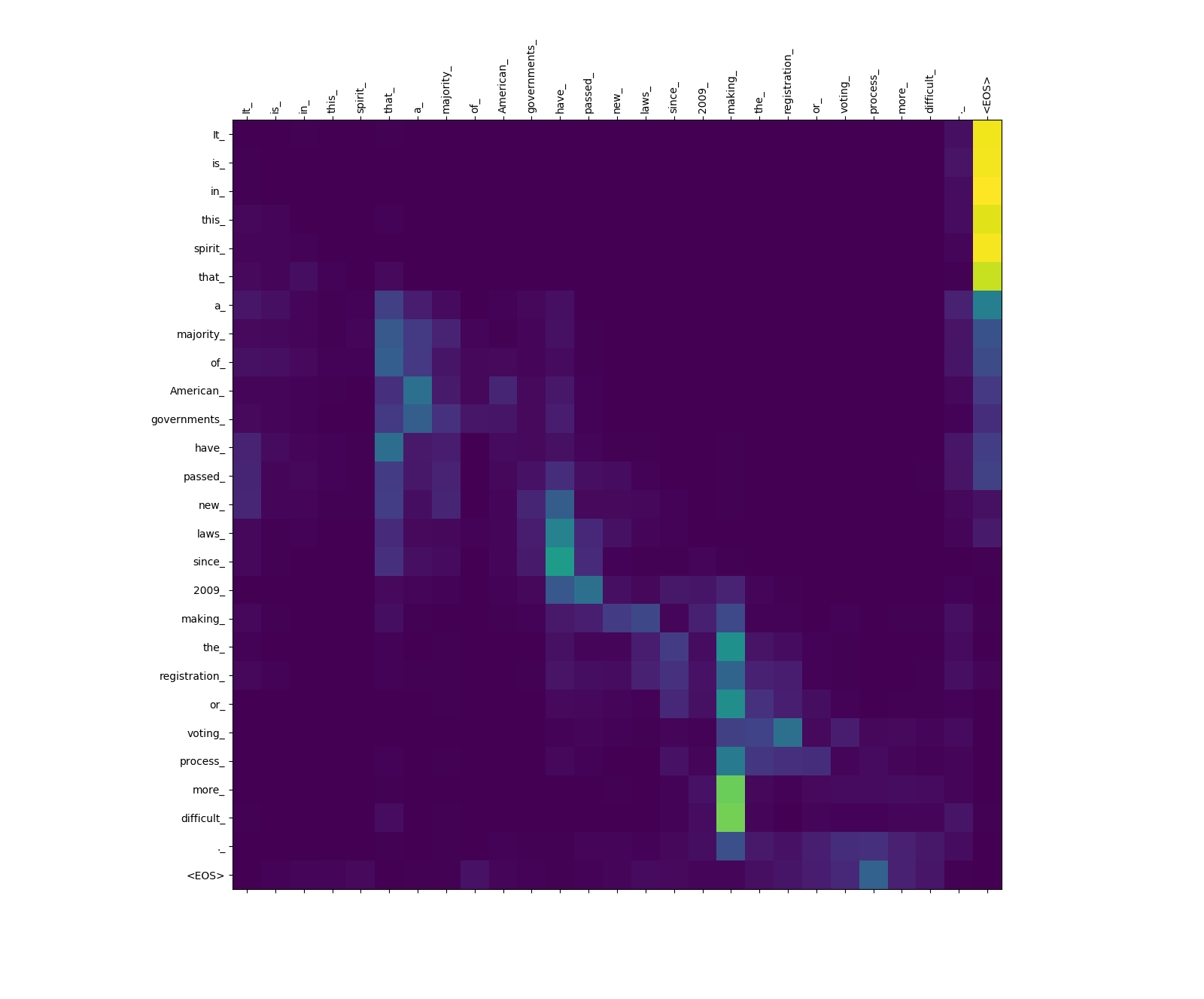
来源的注意力重量。
请注意,从more_和difficult_ making_注意力的重量 - 在尝试完成短语“使...更困难”时,它们是“在监视”中。
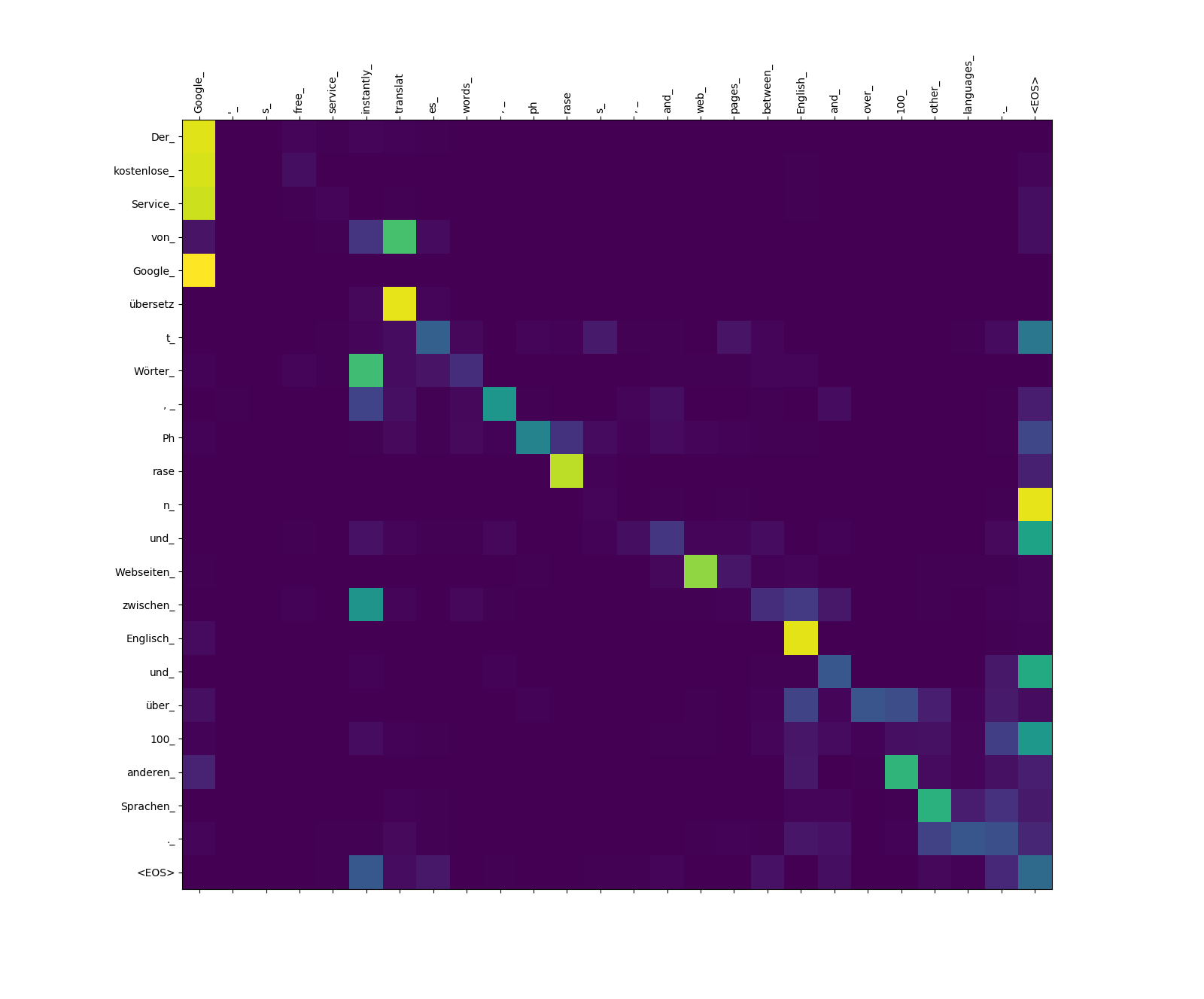
目标到源的注意力重量。
请注意, übersetz (目标)到translat (源)以及从Webseiten (Target)到web (源)等的注意力重量。这可能是由于它们在德语和英语中的同义词所致。
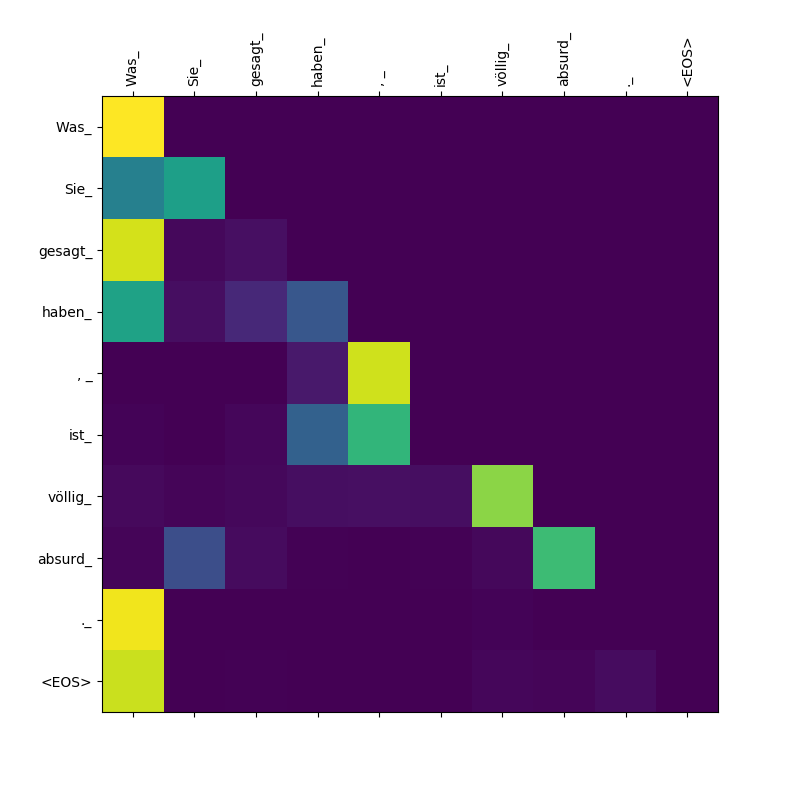
目标到目标的注意力重量。
请注意, Was Sie_ , gesagt , haben_关注 - 当解码器吐出这些微动物Was ,它需要“意识到”该条款的范围Was Sie gesagt haben (意思是“您所说的”)。


