tf transformer
1.0.0
Esta es una implementación de TensorFlow 2.x del modelo de transformador (la atención es todo lo que necesita) para la traducción del automóvil neural (NMT).
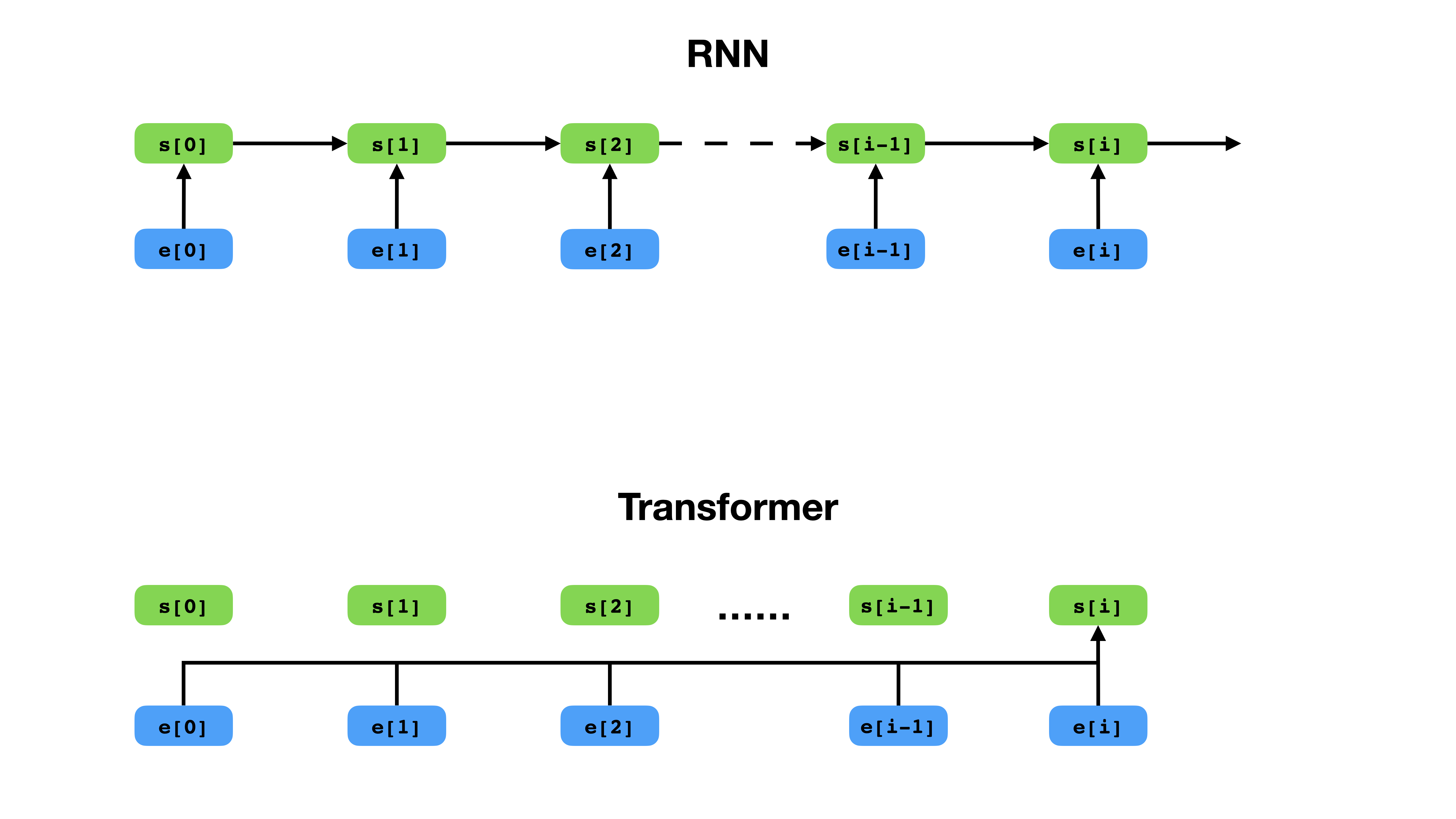
Transformer tiene una forma más flexible de representar el contexto en comparación con RNN.
Transformer es una arquitectura de red neuronal profunda para el modelado de secuencias, que es la tarea de estimar la probabilidad de tokens en una secuencia basada en su contexto textual. Mientras que las redes neuronales recurrentes colapsan las integridades de toda la historia de los tokens de contexto en un solo vector, el transformador tiene acceso al vector de incrustación de cada token individual, sin importar cuán lejos esté el contexto. Esto lo hace muy adecuado para modelar relaciones de dependencia de larga distancia, lo cual es clave para los avances recientes en métodos para el aprendizaje de representación de texto como Bert y GPT-2.
En el núcleo del transformador está el mecanismo de autoatención , donde el objetivo es calcular una representación contextualizada de cada token en una secuencia permitiéndoles "prestar atención" entre sí. Dadas las representaciones vectoriales iniciales e[i] para todas las posiciones i , primero aplica proyecciones lineales para obtener vectores q[i] , k[i] , v[i] , donde k 'sy v ' s juega el papel de la clave y el valor de una base de conocimiento sobre el contenido de secuencia, que debe ser considerado por q[i] para determinar qué tokens son más similares a la token en el índice en el índice i . El resultado de la consulta es simplemente los puntajes de similitud entre q[i] y k (típicamente productos de puntos), que se usan como pesos para calcular un promedio ponderado de las v como la nueva representación de e[i] . Tenga en cuenta que q , k y v se derivan de la misma secuencia, lo que significa que la secuencia se considera efectivamente (de ahí el nombre de autoatención).
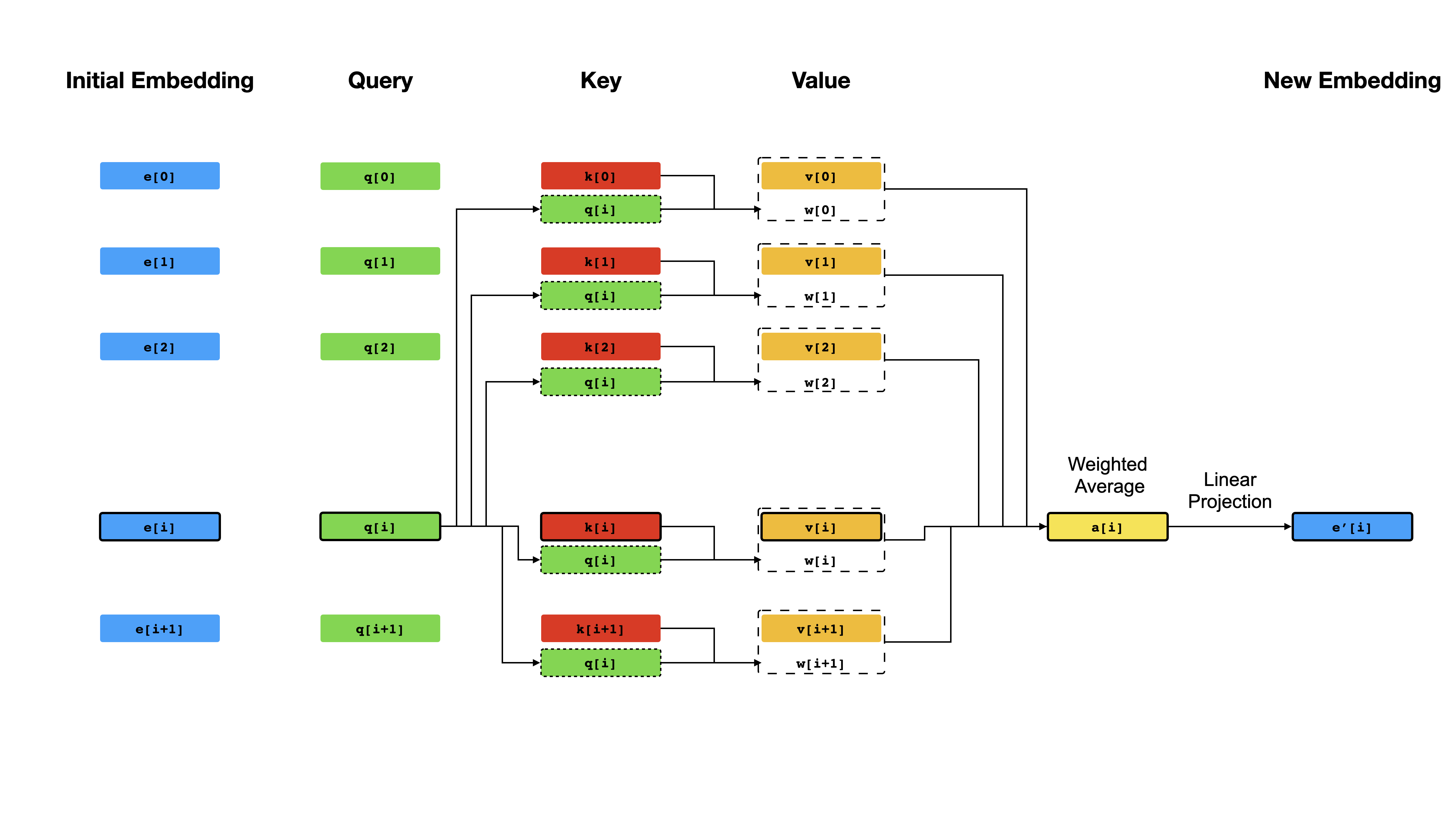
Mecanismo de autoatención.
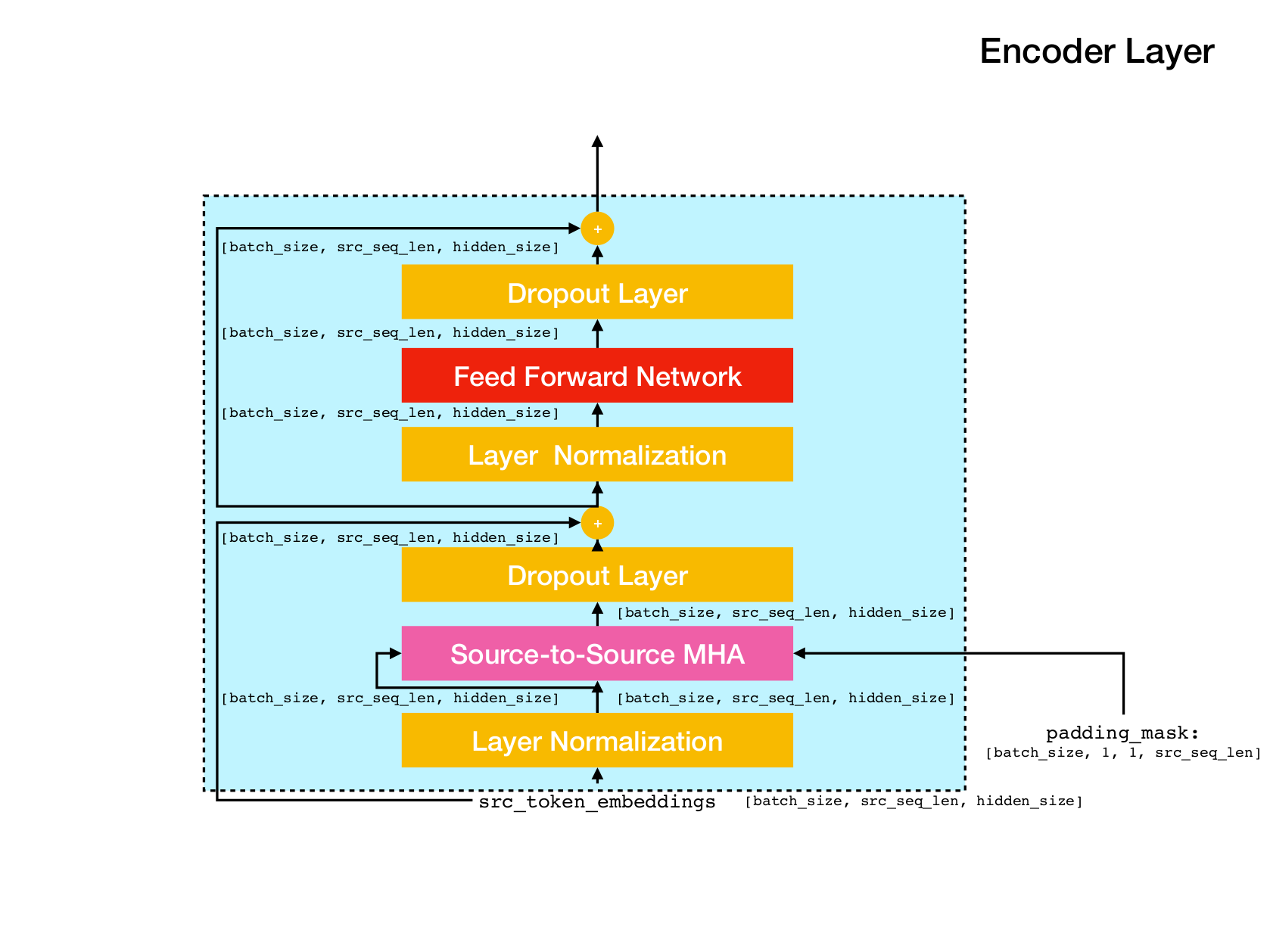
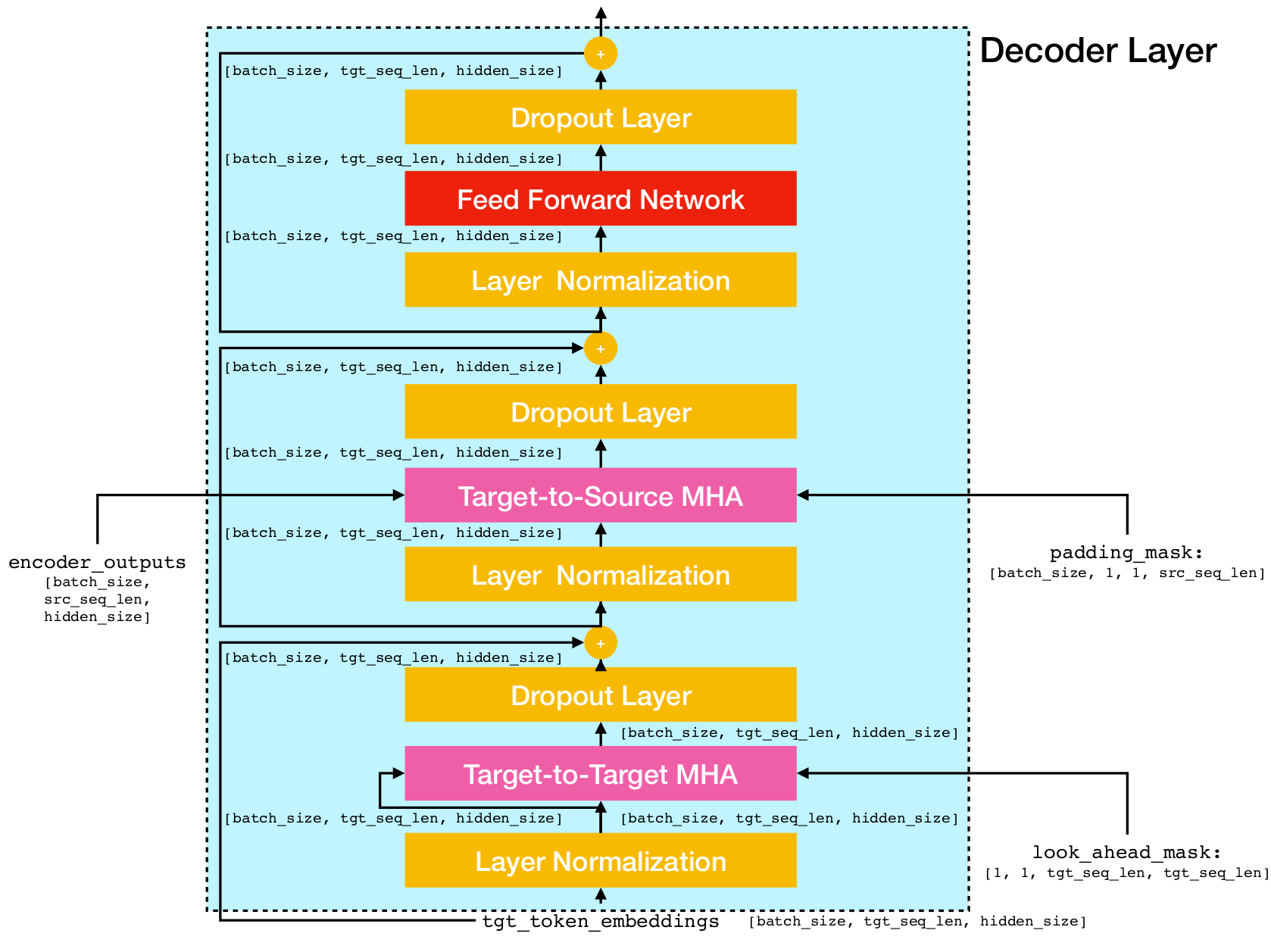
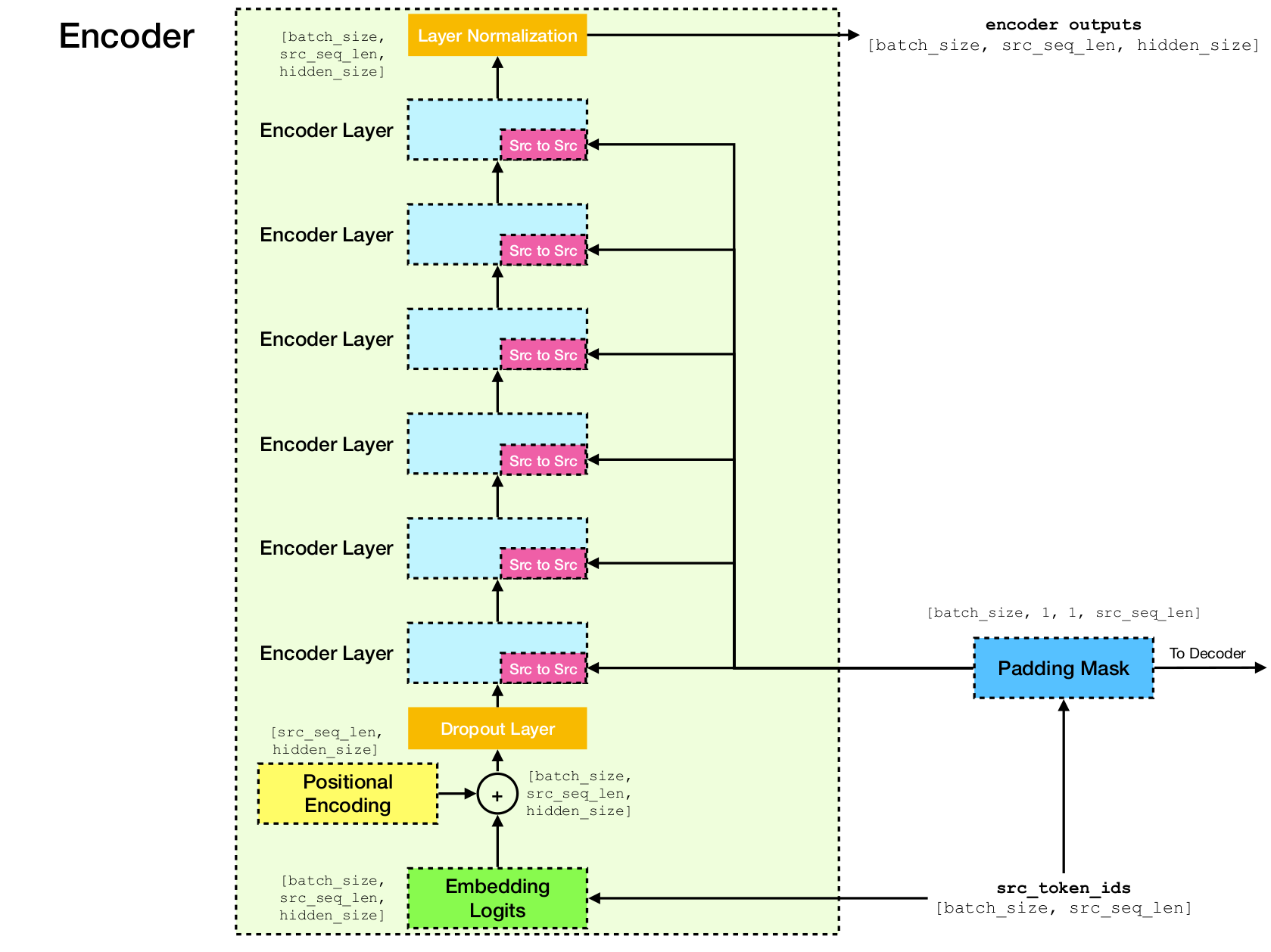
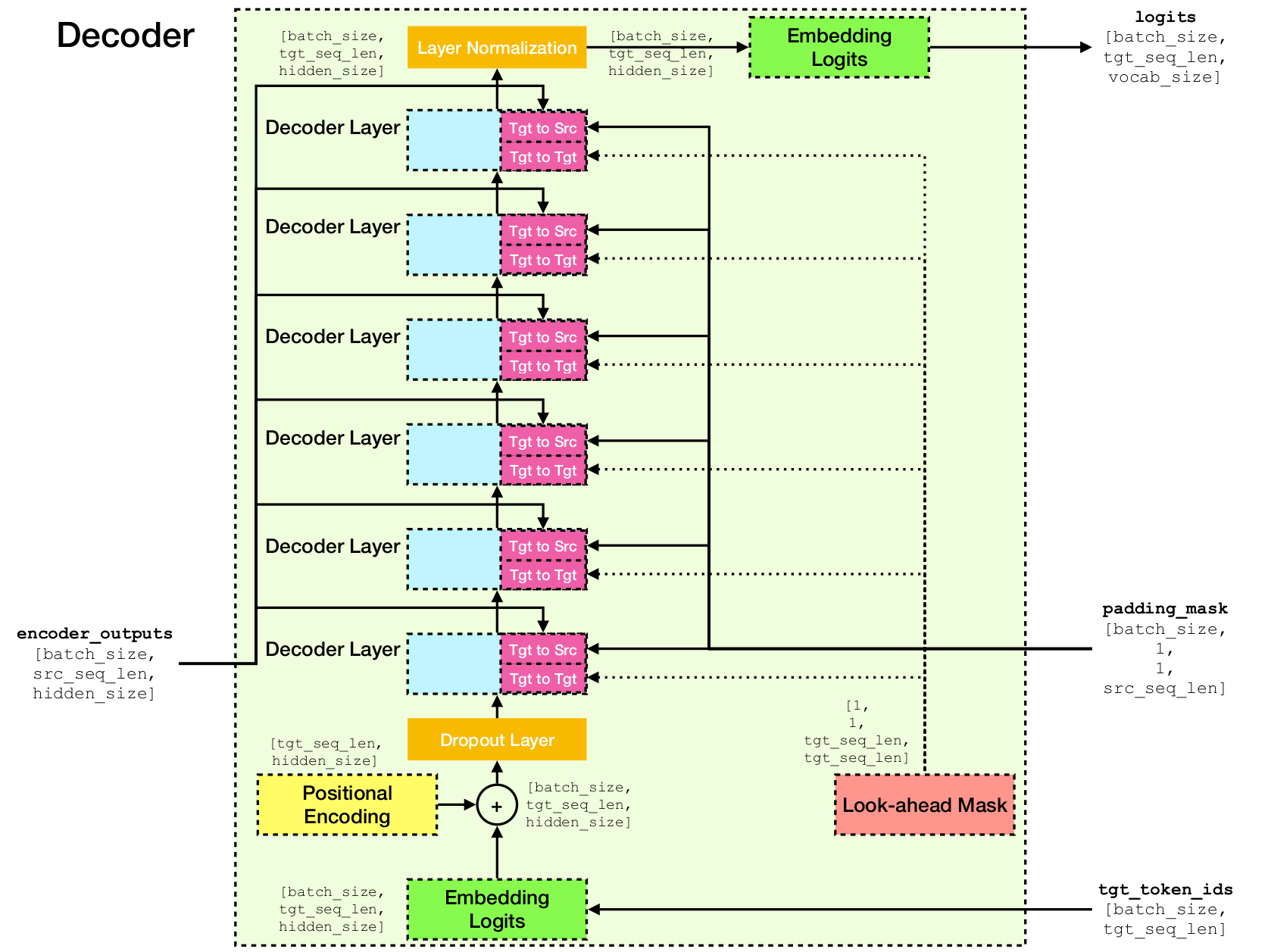
Arquitectura de red de transformadores.
Esta implementación se basa en TensorFlow 2.x y Python3. Además, se requiere que NLTK calcule la puntuación BLEU para la evaluación.
Puede clonar este repositorio ejecutando
git clone [email protected]:chao-ji/tf-transformer.gitLuego clon y actualice el submódulo ejecutando
cd tf-transformer
git submodule update --init --recursiveEl corpus de capacitación debe estar en forma de una lista de archivos de texto en el lenguaje de origen, junto con una lista de archivos de texto en el lenguaje de destino, donde las líneas (es decir, las oraciones) en los archivos de texto del lenguaje de origen tienen correspondencia individual a las líneas en archivos de texto de idioma de destino
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
Primero debe convertir archivos de texto sin procesar en archivos TFRecord ejecutando
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab Nota: Este proceso implica "aprender" un vocabulario de tokens de subvenciones del corpus de entrenamiento, que se guarda en archivos vocab.subtokens y vocab.alphabet . El vocabulario se usará más tarde para codificar la cadena de texto sin procesar en ID de token de subvención, o decodificarlos de nuevo a la cadena de texto sin procesar.
Para obtener información sobre el uso detallada, ejecute
python commons/create_tfrecord_machine_translation.py --helpPara datos de muestra, consulte data_sources.txt
Para entrenar un modelo, ejecutar
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir is the directory storing the TFRecord files, vocab_path is the path to the basename of the vocabulary files vocab.subtokens and vocab.alphabet (ie path to vocab ) generated by running create_tfrecord_machine_translation.py , and model_dir is the directory that checkpoint files will be saved to (or loaded from if training is resumed from a previous punto de control).
Para obtener información sobre el uso detallada, ejecute
python run_trainer.py --helpLa evaluación implica traducir una secuencia de origen en la secuencia de destino y calcular la puntuación BLU entre la secuencia de destino predicha y la TRUTH.
Para evaluar un modelo previamente en el estado previo, ejecute
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename y target_text_filename son las rutas a los archivos de texto que contienen secuencias de origen y destino, respectivamente.
Tenga en cuenta que el argumento de la línea de comandos target_text_filename es opcional: si queda fuera, el evaluador se ejecutará en modo de inferencia , donde solo las traducciones se escribirán en el archivo de salida.
Para obtener información de uso más detallada, ejecute
python run_evaluator.py --help Tenga en cuenta que el mecanismo de atención calcula las similitudes de token para verse que se pueden visualizar para comprender cómo se distribuye la atención sobre diferentes tokens. Cuando ejecute python run_evaluator.py las matrices de peso de atención se guardarán para archivar attention_xxxx.npy , que almacena un dict de las siguientes entradas:
src : matriz numpy de forma [batch_size, src_seq_len] , donde cada fila es una secuencia de ID de token que termina con 1 ( EOS_ID ) y acolchada con ceros.tgt : matriz numpy de forma [batch_size, tgt_seq_len] , donde cada fila es una secuencia de ID de token que termina con 1 ( EOS_ID ) y acolchada con ceros.src_src_attention : numpy matriz de forma [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : numpy matriz de forma [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : numpy matriz de forma [batch_size, num_heads, tgt_seq_len, tgt_seq_len]Los pesos de atención se pueden mostrar ejecutando:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files donde head es un entero en [0, num_heads - 1] y index es un entero en [0, batch_size - 1] .
A continuación se muestran tres oraciones en inglés (idioma fuente) y sus traducciones en alemán (idioma de destino).
Oraciones de entrada en la fuente Langauge
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
Oraciones traducidas en lenguaje de destino
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
El modelo Transformer calcula tres tipos de atenciones:
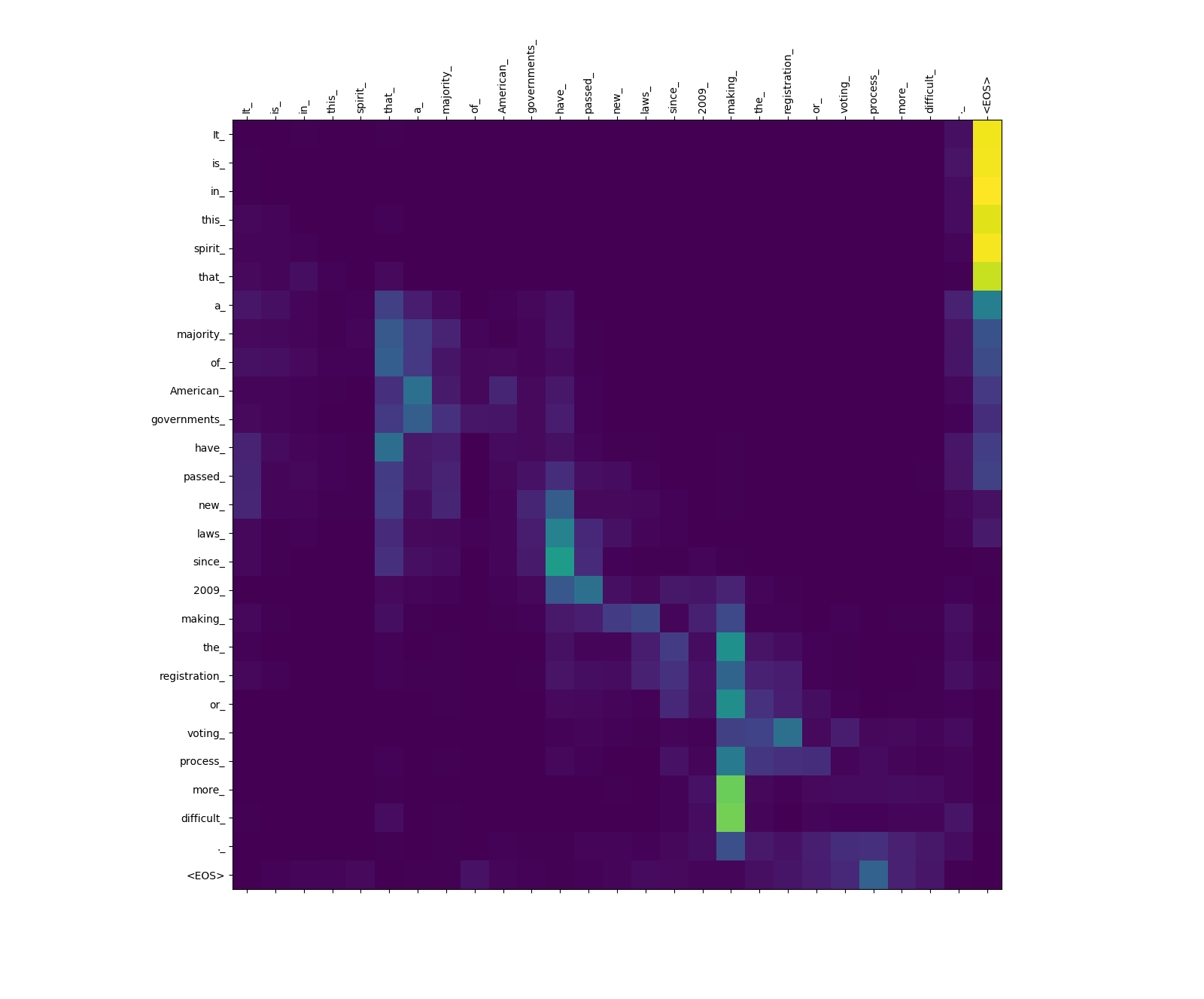
Pesos de atención de origen a fuente.
Observe el peso de atención de more_ y difficult_ a making_ - están "en el vigilante" para el verbo "hacer" al tratar de completar la frase "hacer ... más difícil".
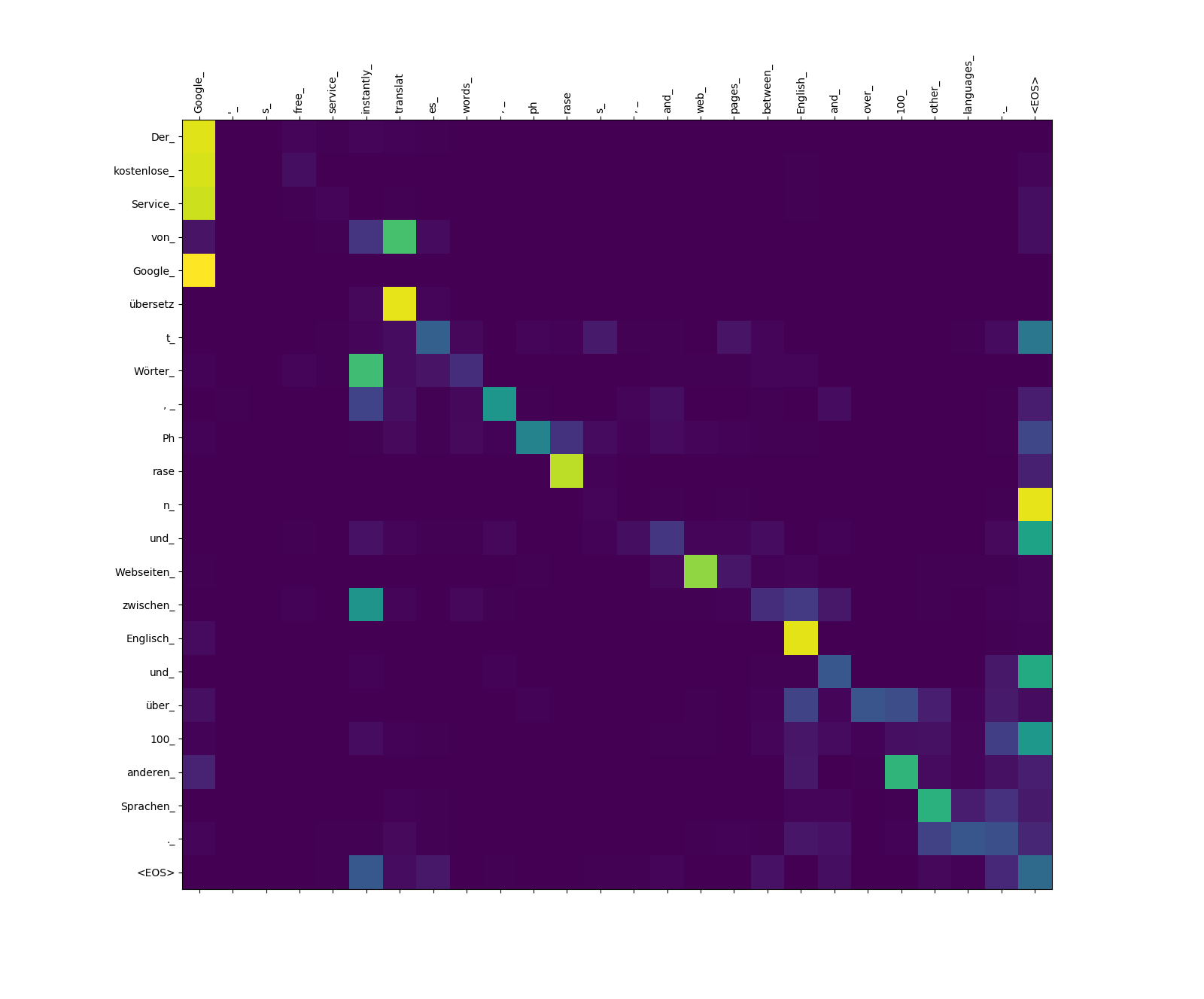
Pesos de atención de objetivo a fuente.
Observe el peso de atención de übersetz (objetivo) para translat (fuente), y de Webseiten (objetivo) a web (fuente), etc. Esto probablemente se deba a su sinónimo en alemán e inglés.
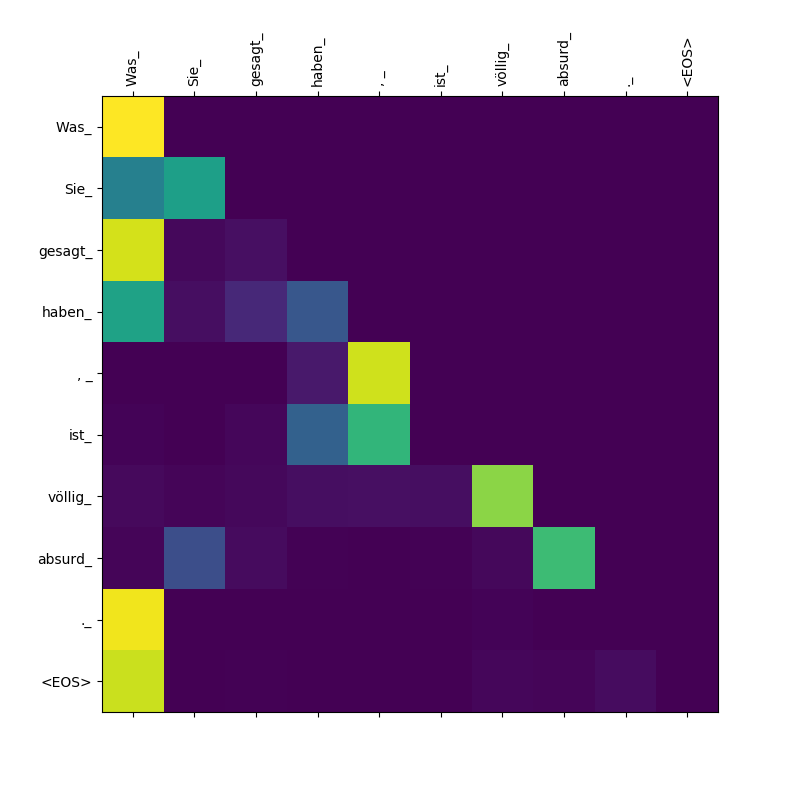
Pesos de atención de objetivo a objetivo.
Observe la atención prestada a Was por Was , Sie_ , gesagt , haben_ - Como el decodificador escupe estos subtoques, debe "estar al tanto del alcance de la cláusula Was Sie gesagt haben (es decir," lo que ha dicho ").


