tf transformer
1.0.0
นี่คือการใช้ Tensorflow 2.x ของโมเดลหม้อแปลง (ความสนใจคือสิ่งที่คุณต้องการ) สำหรับการแปลเครื่องประสาท (NMT)
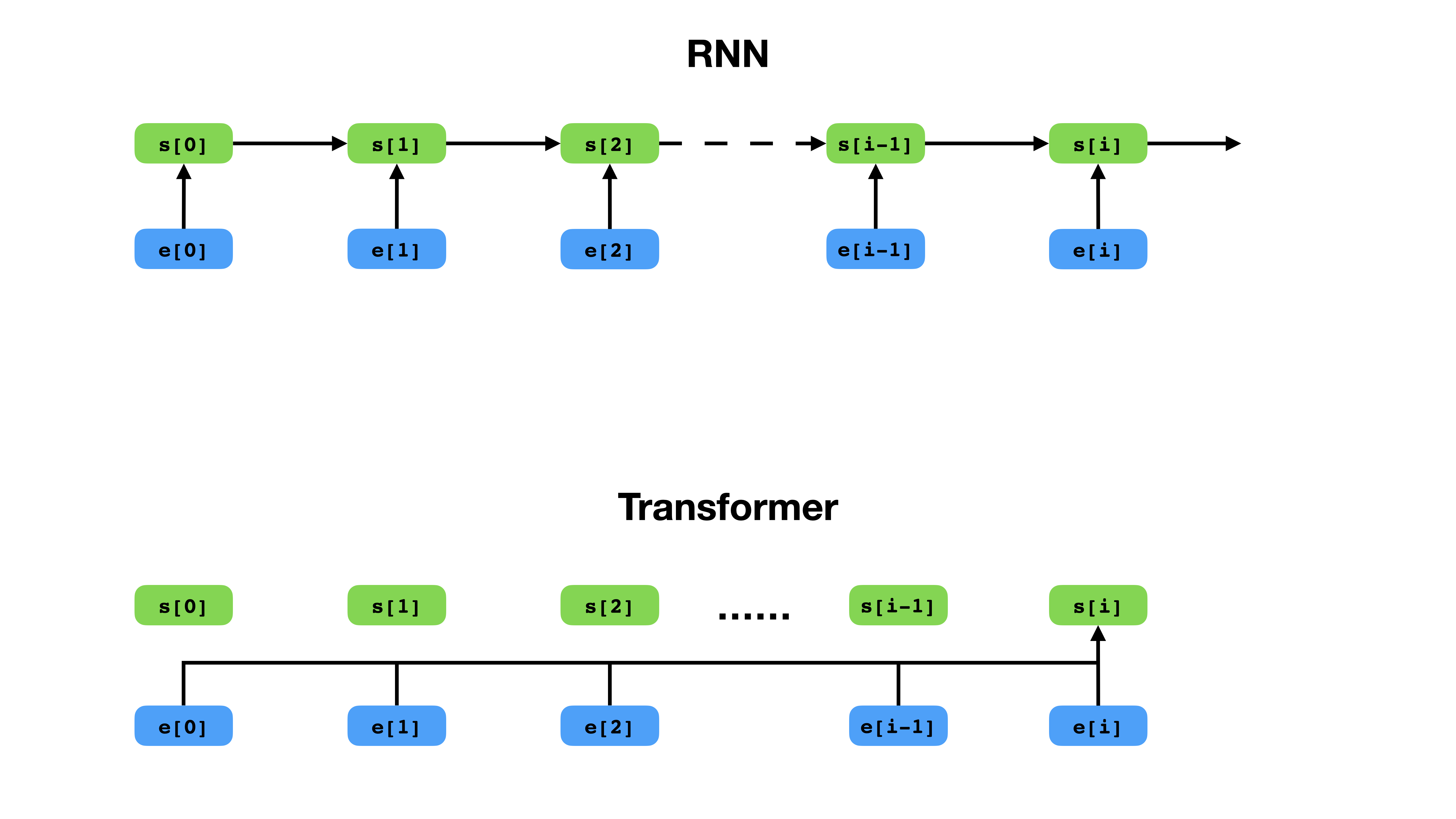
Transformer มีวิธีที่ยืดหยุ่นมากขึ้นในการแสดงบริบทเมื่อเทียบกับ RNN
Transformer เป็นสถาปัตยกรรมเครือข่ายประสาทลึกสำหรับการสร้างแบบจำลองลำดับซึ่งเป็นหน้าที่ในการประเมินโอกาสของโทเค็นในลำดับตามบริบทของข้อความ ในขณะที่เครือข่ายประสาทกำเริบล่มสลายการฝังตัวของประวัติศาสตร์ทั้งหมดของโทเค็นบริบทเป็นเวกเตอร์เดียวหม้อแปลงสามารถเข้าถึงเวกเตอร์ฝังตัวของโทเค็นแต่ละคนไม่ว่าบริบทจะครอบคลุมไกลแค่ไหน สิ่งนี้ทำให้เหมาะสำหรับการสร้างแบบจำลองความสัมพันธ์ในการพึ่งพาทางไกลซึ่งเป็นกุญแจสำคัญในการพัฒนาล่าสุดในวิธีการสำหรับการเรียนรู้การเป็นตัวแทนข้อความเช่น Bert และ GPT-2
หัวใจหลักของหม้อแปลงคือกลไก การใส่ใจในตนเอง ซึ่งเป้าหมายคือการคำนวณการเป็นตัวแทน ตามบริบท ของโทเค็นแต่ละตัวในลำดับโดยให้พวกเขา "ให้ความสนใจ" ซึ่งกันและกัน ด้วยการเป็นตัวแทนเวกเตอร์เริ่มต้น e[i] สำหรับทุกตำแหน่ง i มันใช้การคาดการณ์เชิง เส้น เป็นครั้งแรกเพื่อให้ได้เวกเตอร์ q[i] q[i] k[i] , v[i] , ที่ k 's และ v ของ v ของบทบาทของ คีย์ และ คุณค่า ของฐานความรู้เกี่ยวกับเนื้อหา i ผลลัพธ์ของการสืบค้นเป็นเพียงคะแนนความคล้ายคลึงกันระหว่าง q[i] และ k 'S (โดยทั่วไปแล้วผลิตภัณฑ์ดอท) ซึ่งใช้เป็นน้ำหนักเพื่อคำนวณค่าเฉลี่ยถ่วงน้ำหนักของ v เป็นตัวแทนใหม่ของ e[i] โปรดทราบว่า q , k และ v นั้นได้มาจากลำดับ เดียวกัน ซึ่งหมายความว่าลำดับนั้นมีการสอบถามตัวเองอย่างมีประสิทธิภาพ (ดังนั้นชื่อการตั้งใจด้วยตนเอง)
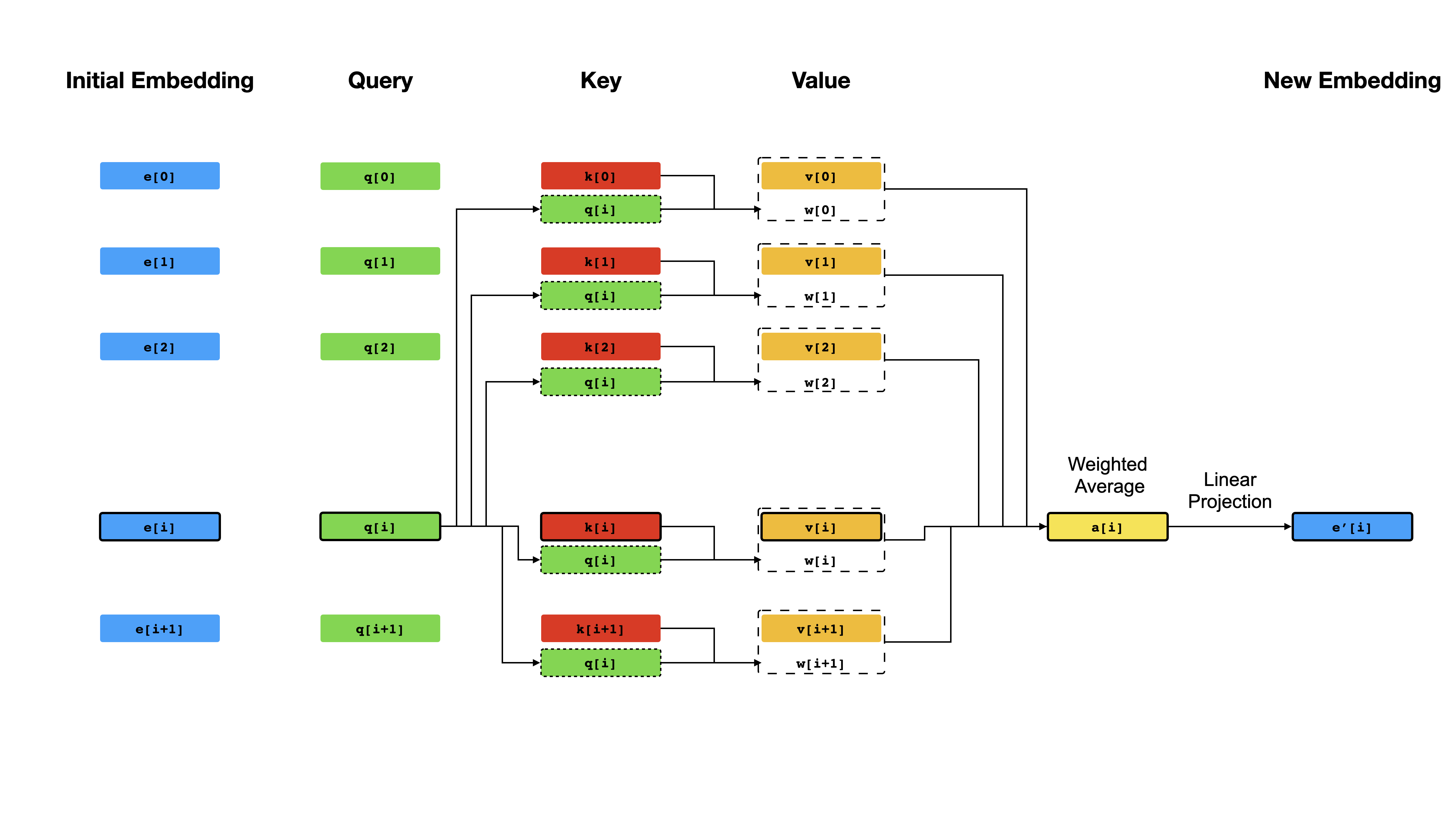
กลไกการดูแลตนเอง
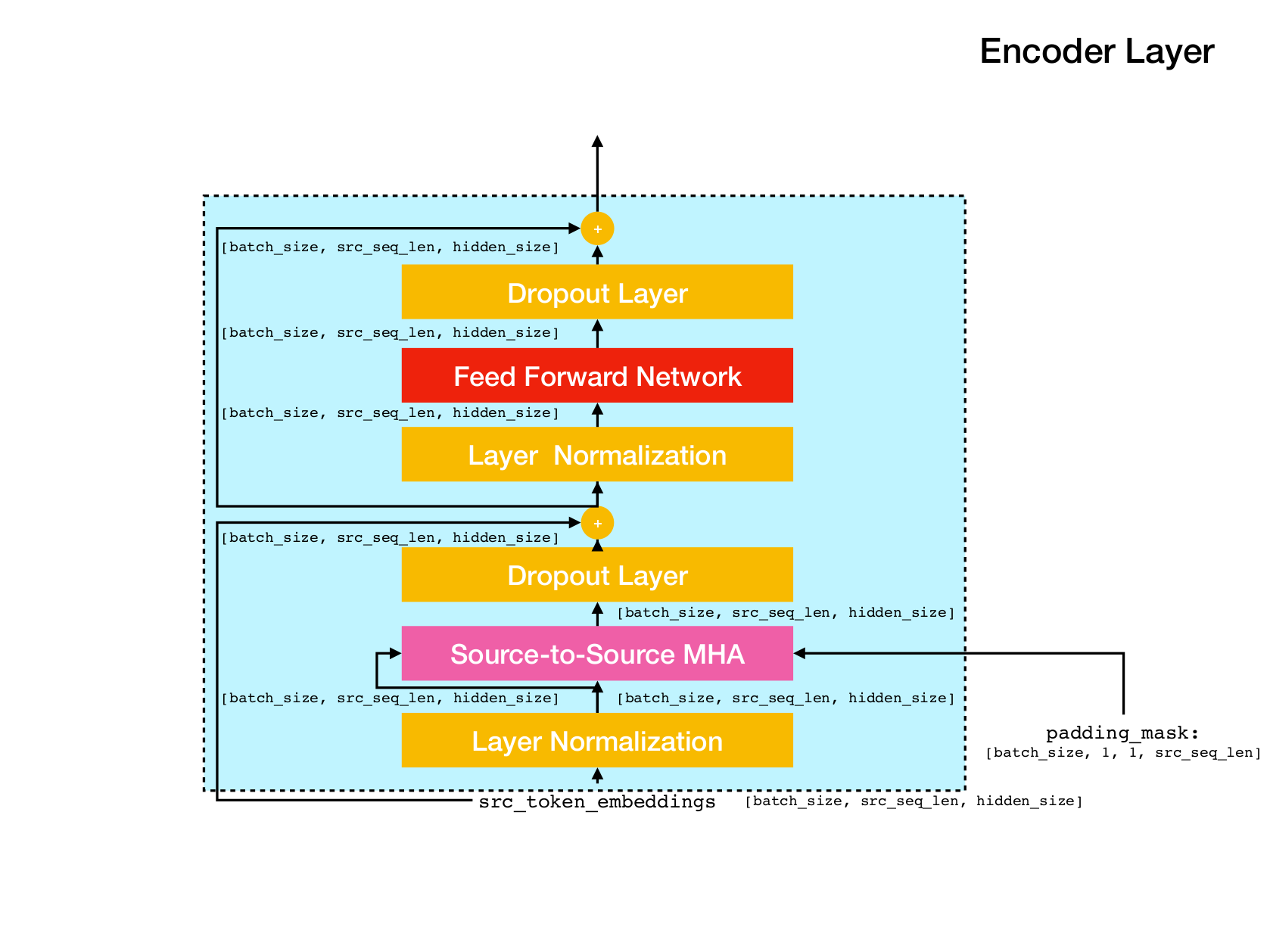
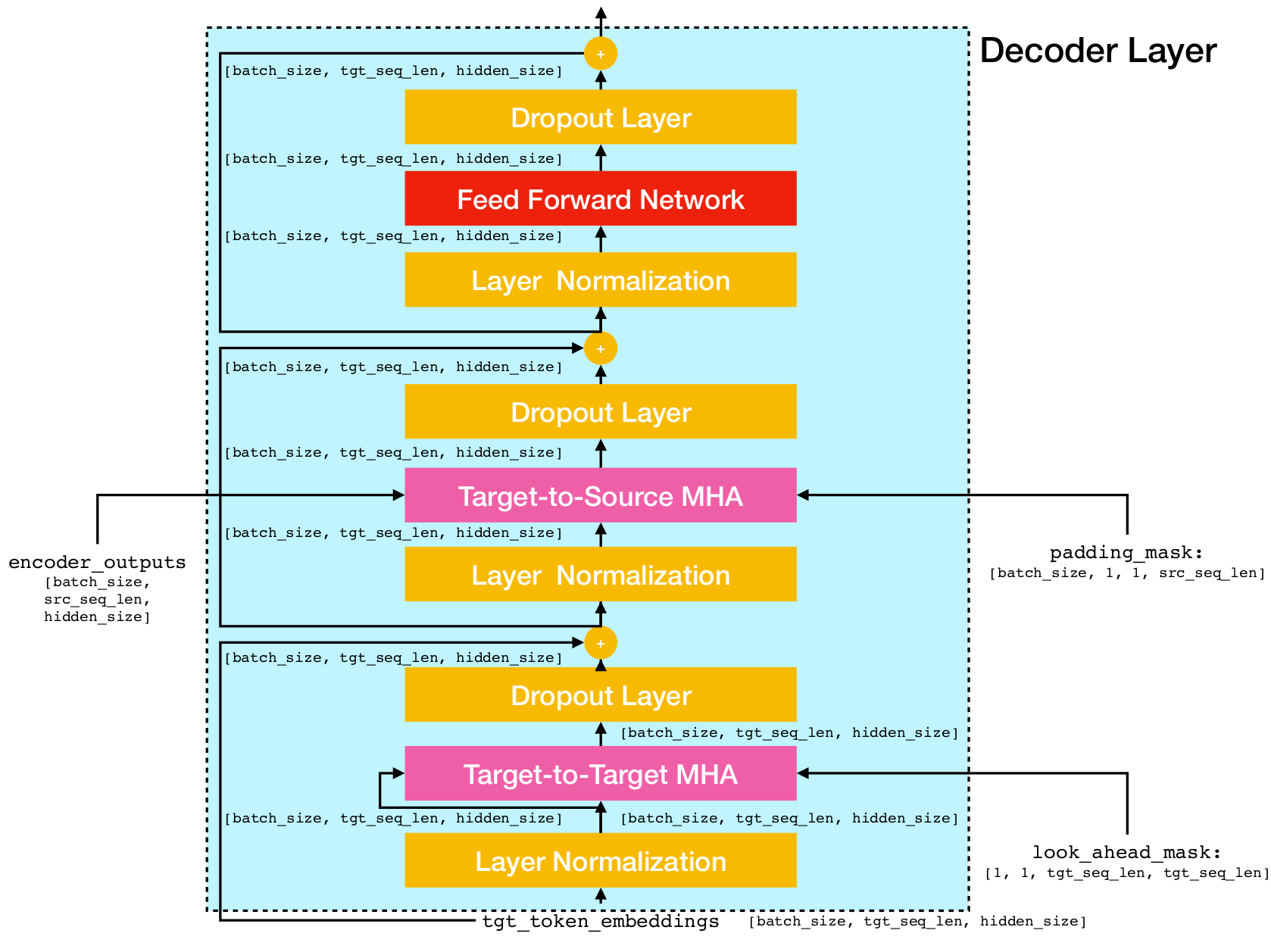
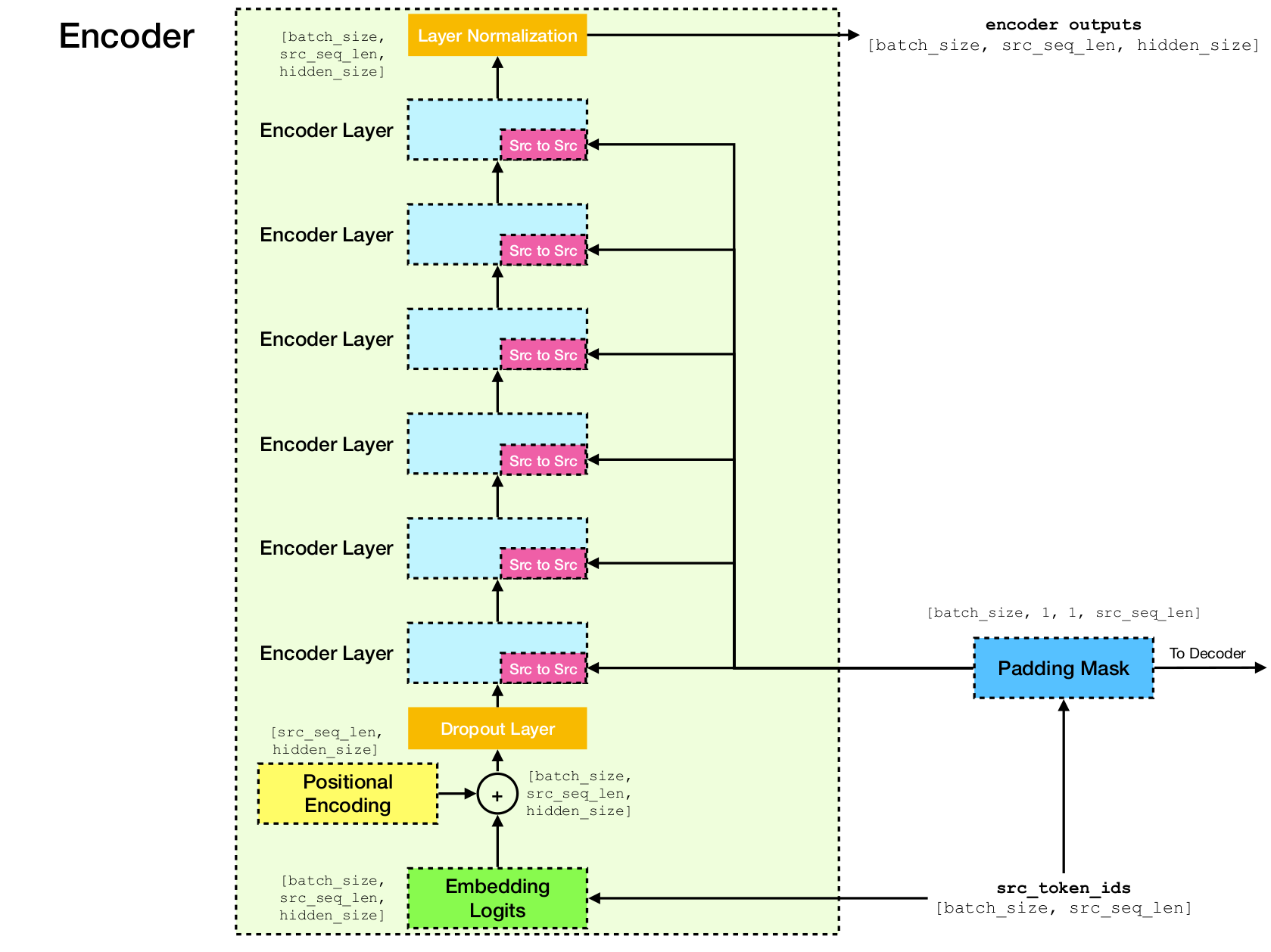
สถาปัตยกรรมเครือข่ายหม้อแปลง
การใช้งานนี้ขึ้นอยู่กับ TensorFlow 2.x และ Python3 นอกจากนี้จำเป็นต้องใช้ NLTK เพื่อคำนวณคะแนน Bleu สำหรับการประเมินผล
คุณสามารถโคลนพื้นที่เก็บข้อมูลนี้ได้โดยการวิ่ง
git clone [email protected]:chao-ji/tf-transformer.gitจากนั้นโคลนและอัปเดต submodule โดยการรัน
cd tf-transformer
git submodule update --init --recursiveคลังการฝึกอบรมควรอยู่ในรูปแบบของรายการไฟล์ข้อความในภาษาต้นฉบับจับคู่กับรายการไฟล์ข้อความในภาษาเป้าหมายซึ่งบรรทัด (เช่นประโยค) ในไฟล์ข้อความภาษาต้นฉบับ
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
ก่อนอื่นคุณต้องแปลงไฟล์ข้อความดิบเป็นไฟล์ tfrecord โดยเรียกใช้
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab หมายเหตุ: กระบวนการนี้เกี่ยวข้องกับ "การเรียนรู้" คำศัพท์ของโทเค็น subword จากคลังการฝึกอบรมซึ่งบันทึกไว้ในไฟล์ vocab.subtokens และ vocab.alphabet คำศัพท์จะถูกใช้ในภายหลังเพื่อเข้ารหัสสตริงข้อความดิบลงในรหัสโทเค็น subword หรือถอดรหัสกลับไปเป็นสตริงข้อความดิบ
สำหรับข้อมูลการใช้งานโดยละเอียด Run
python commons/create_tfrecord_machine_translation.py --helpสำหรับข้อมูลตัวอย่างอ้างอิงถึง data_sources.txt
เพื่อฝึกนางแบบวิ่ง
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir เป็นไดเรกทอรีที่จัดเก็บไฟล์ tfrecord, vocab_path เป็นเส้นทางไปยัง basename ของไฟล์คำศัพท์ vocab.subtokens และ vocab.alphabet (เช่นเส้นทางไปยัง vocab ) ที่สร้างขึ้นโดยการใช้งาน create_tfrecord_machine_translation.py และ model_dir จุดตรวจ)
สำหรับข้อมูลการใช้งานโดยละเอียด Run
python run_trainer.py --helpการประเมินผลเกี่ยวข้องกับการแปลลำดับต้นทางเป็นลำดับเป้าหมายและการคำนวณคะแนน BLEU ระหว่างลำดับเป้าหมายที่คาดการณ์และความจริง
ในการประเมินแบบจำลองที่ผ่านการฝึกฝนให้เรียกใช้
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename และ target_text_filename เป็นพา ธ ไปยังไฟล์ข้อความที่ถือลำดับแหล่งที่มาและลำดับเป้าหมายตามลำดับ
หมายเหตุอาร์กิวเมนต์บรรทัดคำสั่ง target_text_filename เป็นตัวเลือก - หากปล่อยออกไปผู้ประเมินจะทำงานในโหมด การอนุมาน โดยที่การแปลจะถูกเขียนลงในไฟล์เอาต์พุตเท่านั้น
สำหรับข้อมูลการใช้งานโดยละเอียดเพิ่มเติม Run
python run_evaluator.py --help โปรดทราบว่ากลไกความสนใจคำนวณความคล้ายคลึงกันแบบโทเค็นกับโทเค็นซึ่งสามารถมองเห็นได้เพื่อทำความเข้าใจว่าการกระจายความสนใจนั้นมีการกระจายผ่านโทเค็นที่แตกต่างกันอย่างไร เมื่อคุณเรียกใช้ python run_evaluator.py เมทริกซ์น้ำหนักความสนใจจะถูกบันทึกไว้ในไฟล์ attention_xxxx.npy ซึ่งเก็บคำสั่งของรายการต่อไปนี้:
src : อาร์เรย์ numpy ของรูปร่าง [batch_size, src_seq_len] โดยที่แต่ละแถวเป็นลำดับของรหัสโทเค็นที่ลงท้ายด้วย 1 ( EOS_ID ) และเบาะด้วยศูนย์tgt : อาร์เรย์ numpy ของรูปร่าง [batch_size, tgt_seq_len] โดยที่แต่ละแถวเป็นลำดับของรหัสโทเค็นที่ลงท้ายด้วย 1 ( EOS_ID ) และเบาะด้วยศูนย์src_src_attention : อาร์เรย์ numpy ของรูปร่าง [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : อาร์เรย์ numPy ของรูปร่าง [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : อาร์เรย์ numPy ของรูปร่าง [batch_size, num_heads, tgt_seq_len, tgt_seq_len]น้ำหนักความสนใจสามารถแสดงได้โดยการวิ่ง:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files โดยที่ head เป็นจำนวนเต็มใน [0, num_heads - 1] และ index เป็นจำนวนเต็มใน [0, batch_size - 1]
แสดงด้านล่างเป็นสามประโยคเป็นภาษาอังกฤษ (ภาษาต้นทาง) และการแปลเป็นภาษาเยอรมัน (ภาษาเป้าหมาย)
ประโยคอินพุตในแหล่งกำเนิด Langauge
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
ประโยคที่แปลเป็นภาษาเป้าหมาย
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
โมเดลหม้อแปลงคำนวณความสนใจสามประเภท:
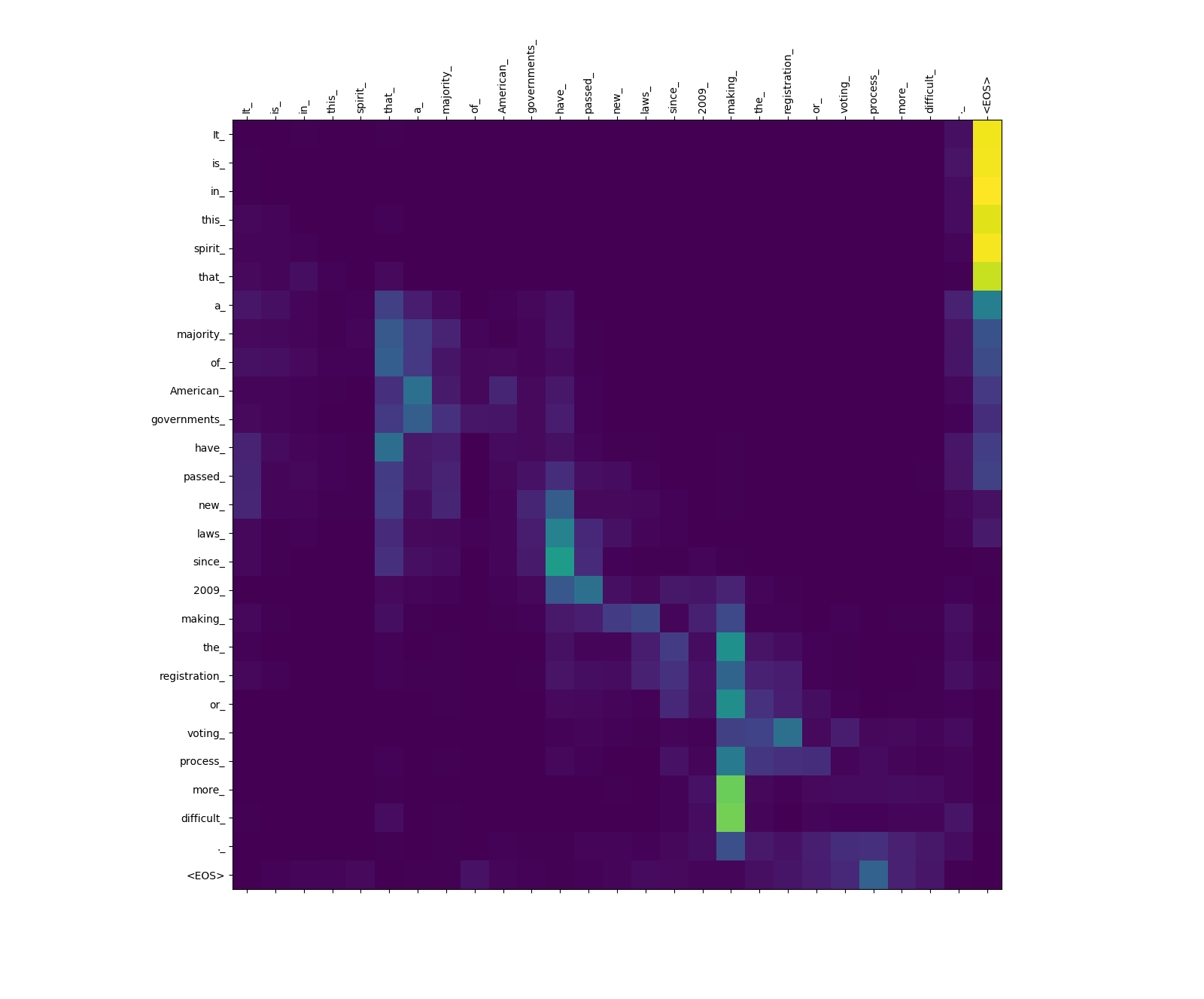
น้ำหนักความสนใจที่มาจากแหล่งที่มา
สังเกตน้ำหนักความสนใจจาก more_ และ difficult_ to making_ - พวกเขา "อยู่ในการเฝ้าระวัง" สำหรับคำกริยา "ทำ" เมื่อพยายามทำวลี "ทำให้ ... ยากขึ้น"
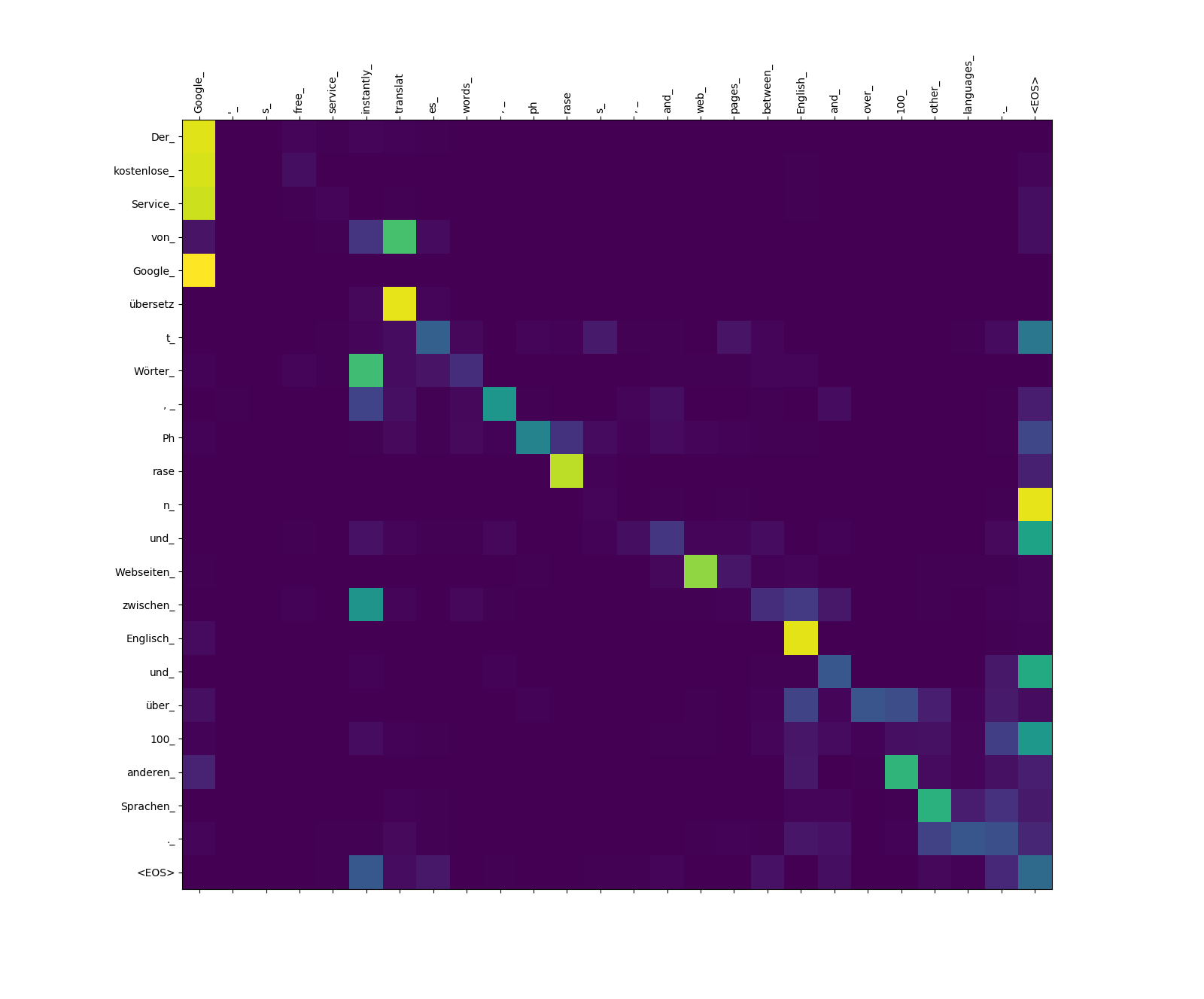
น้ำหนักความสนใจเป้าหมายไปยังแหล่งที่มา
สังเกตน้ำหนักความสนใจจาก übersetz (เป้าหมาย) ไปยัง translat (แหล่งที่มา) และจาก Webseiten (เป้าหมาย) ไปยัง web (แหล่งที่มา) ฯลฯ ซึ่งอาจเป็นเพราะคำพ้องความหมายของพวกเขาในภาษาเยอรมันและภาษาอังกฤษ
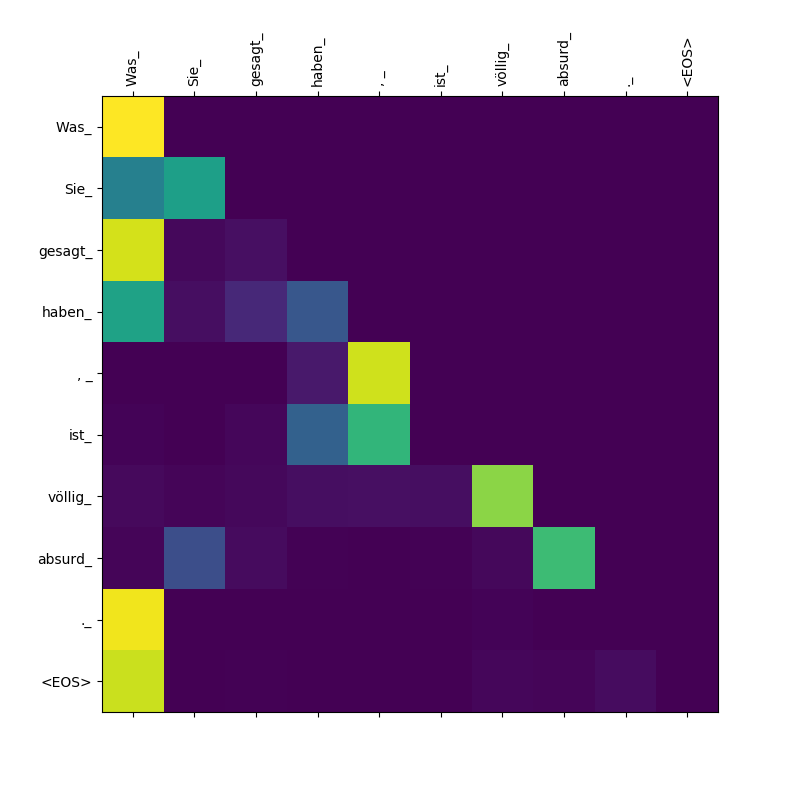
น้ำหนักความสนใจเป้าหมายเป็นเป้าหมาย
สังเกตความสนใจที่จ่าย Was Was Sie_ , gesagt , haben_ - ในขณะที่ตัวถอดรหัสพ่น subtokens เหล่านี้มันจำเป็นต้อง "ระวัง" ของขอบเขตของประโยค Was Sie gesagt haben (หมายถึง "สิ่งที่คุณพูด")


