tf transformer
1.0.0
이것은 신경 기계 번역 (NMT)을위한 변압기 모델 (주의가 필요한 모든 것)의 TensorFlow 2.X 구현입니다.
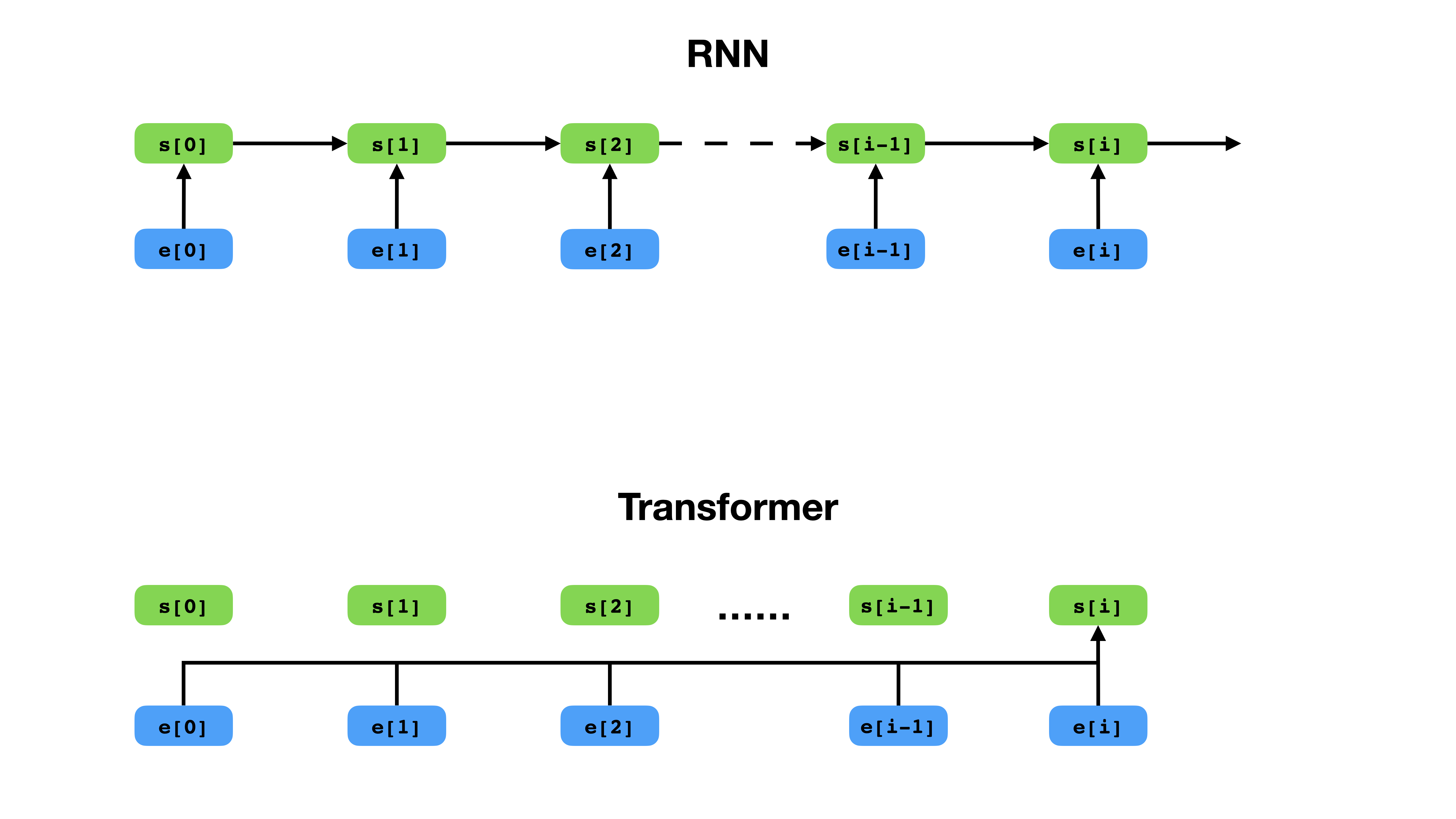
변압기는 RNN과 비교하여 컨텍스트를 표현하는보다 유연한 방법을 가지고 있습니다.
Transformer는 시퀀스 모델링을위한 깊은 신경 네트워크 아키텍처로, 텍스트 컨텍스트에 따라 시퀀스에서 토큰의 가능성을 추정하는 작업입니다. 반복 신경 네트워크가 컨텍스트 토큰의 전체 이력의 임베딩을 단일 벡터로 붕괴시키는 반면, 변압기는 컨텍스트가 얼마나 멀리 떨어져 있더라도 각 개별 토큰의 임베딩 벡터에 액세스 할 수 있습니다. 이로 인해 장거리 의존성 관계 모델링에 적합합니다. 이는 Bert 및 GPT-2와 같은 텍스트 표현 학습 방법의 최근 획기적인 획기적인 핵심입니다.
변압기의 핵심에는 자체 변환 메커니즘이 있는데, 여기서 목표는 서로 "주의를 기울여"각 토큰의 상황에 맞는 표현을 계산하는 것입니다. 모든 위치 i 에 대해 초기 벡터 표현 e[i] 를 고려할 때, 먼저 벡터 q[i] , k[i] , v[i] 얻기 위해 선형 투영을 적용합니다. 여기서 k 's 및 v 는 시퀀스 내용에 대한 지식 기반의 핵심 과 값 의 역할을 q [ i q[i] 에 의해 쿼리 해야합니다. 쿼리의 결과는 단순히 q[i] 와 k 's (일반적으로 도트-제품) 사이의 유사성 점수이며, e[i] 의 새로운 표현으로서 v 's의 가중 평균을 계산하는 데 가중치로 사용됩니다. q , k 및 v 는 동일한 시퀀스에서 파생되므로 시퀀스가 효과적으로 자체적으로 쿼리됩니다 (따라서 자체 변환).
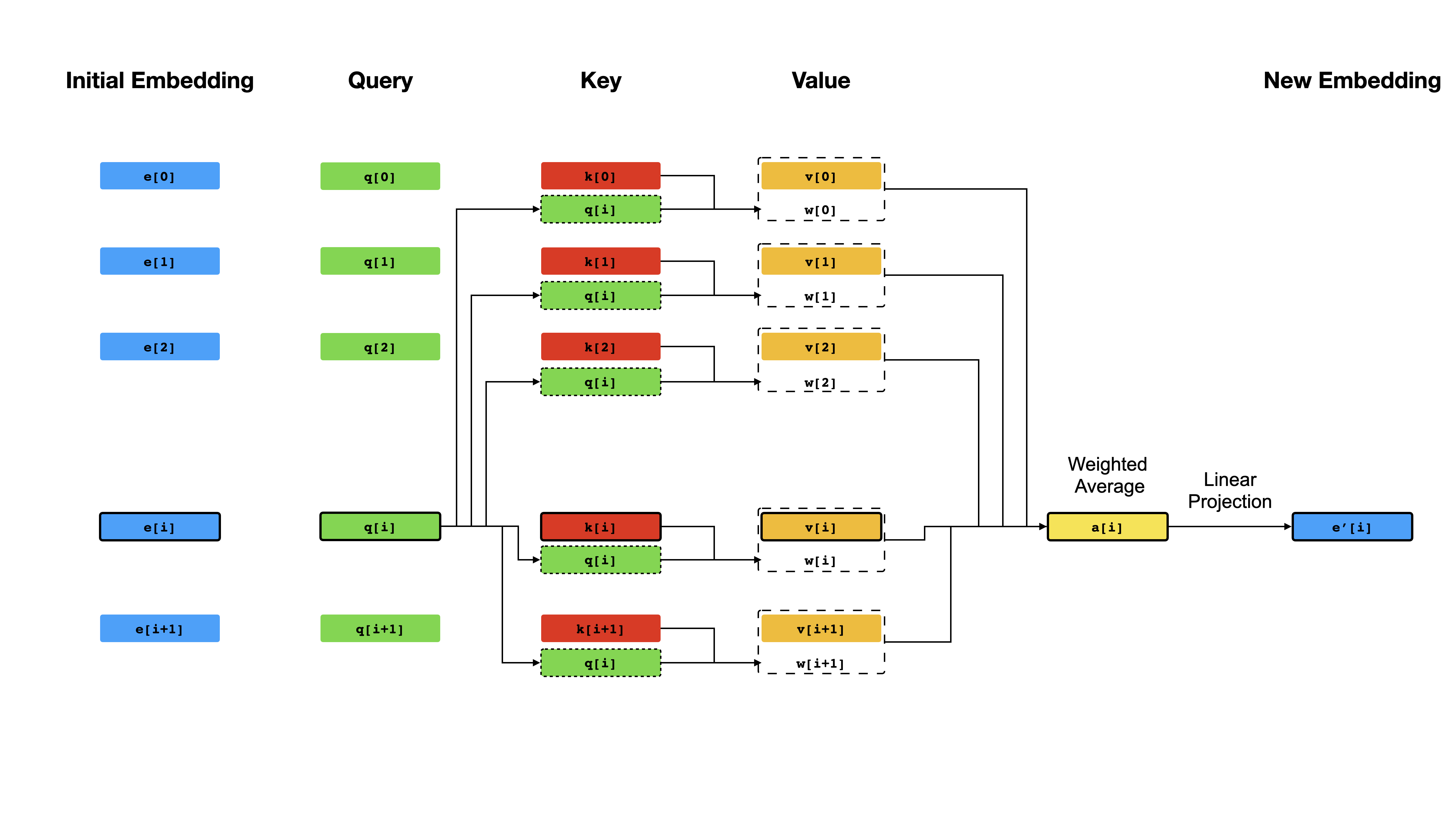
자기 변환 메커니즘.
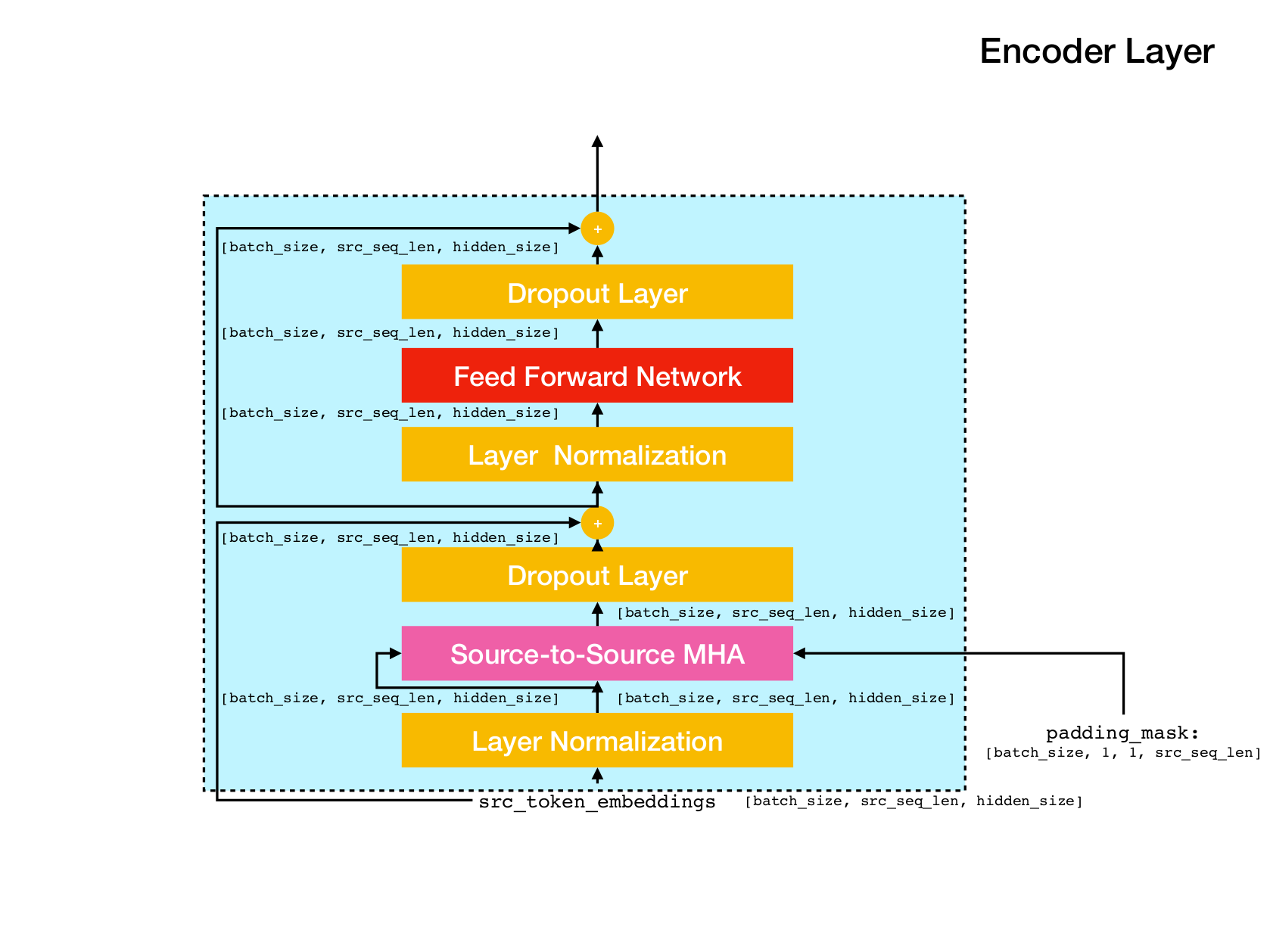
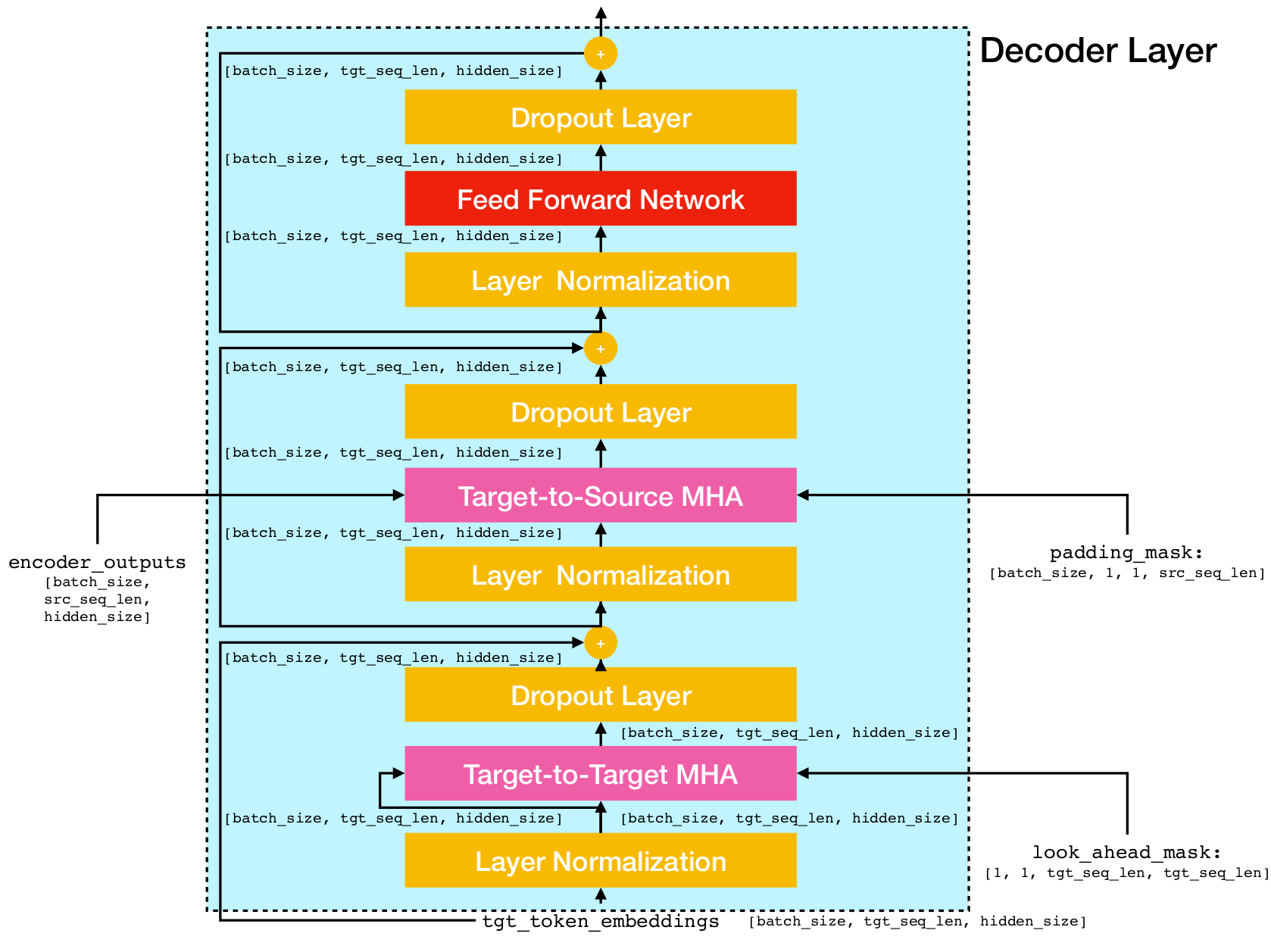
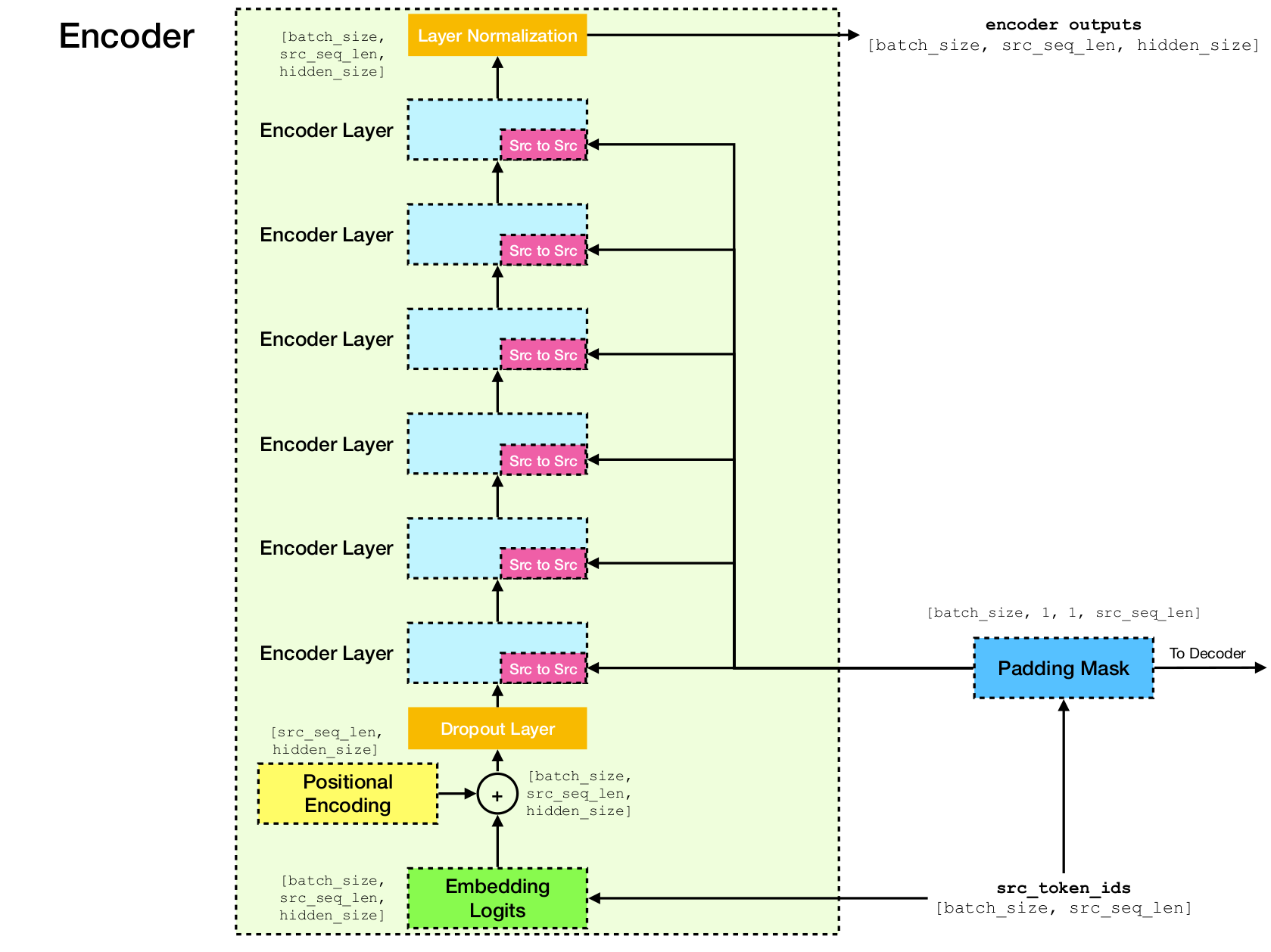
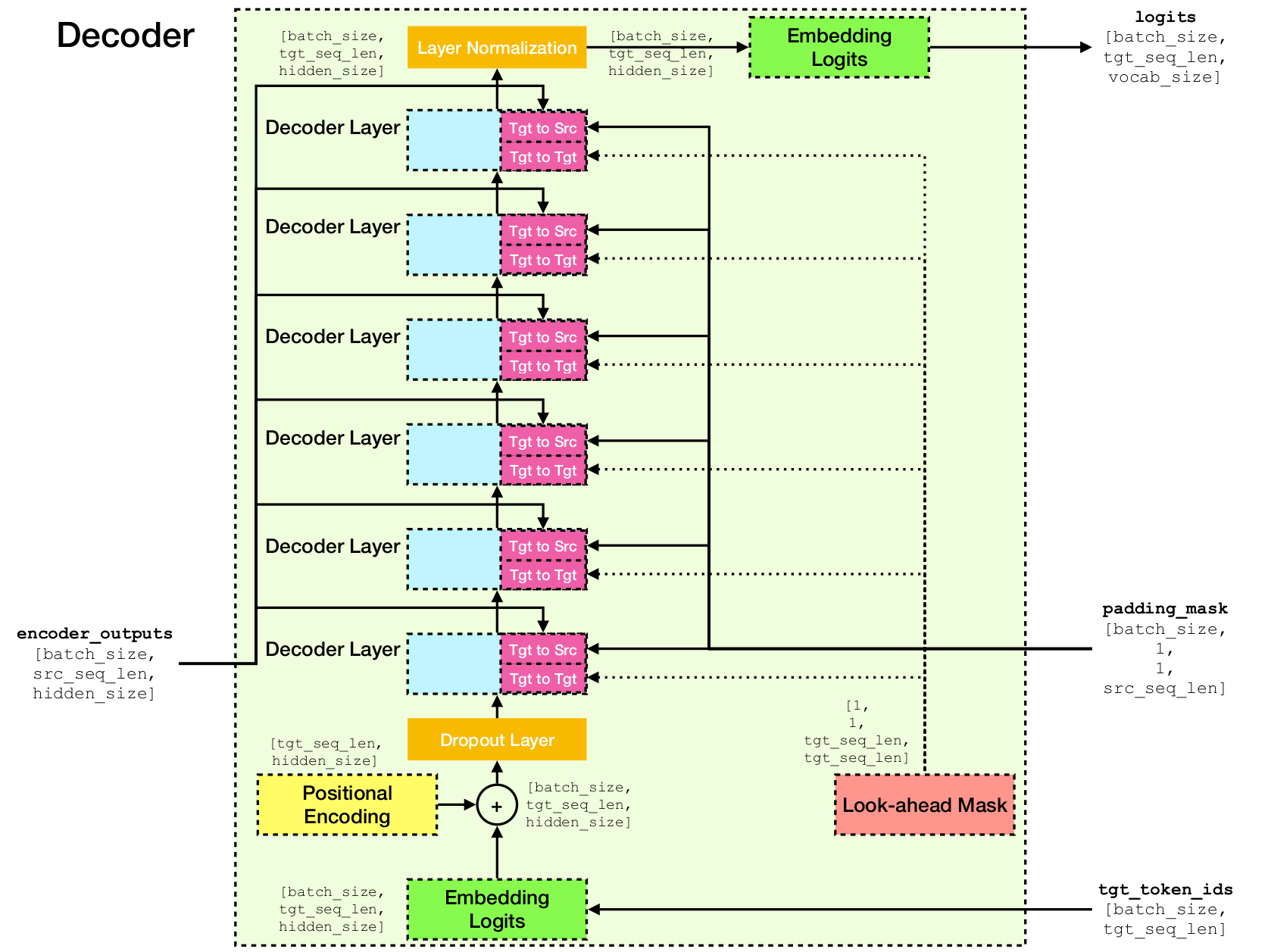
변압기 네트워크 아키텍처.
이 구현은 Tensorflow 2.X 및 Python3을 기반으로합니다. 또한 NLTK는 평가를 위해 BLEU 점수를 계산해야합니다.
이 저장소를 실행하여 복제 할 수 있습니다
git clone [email protected]:chao-ji/tf-transformer.git그런 다음 실행하여 하위 모듈을 복제하고 업데이트하십시오
cd tf-transformer
git submodule update --init --recursive훈련 코퍼스는 소스 언어의 텍스트 파일 목록 형식이어야하며, 대상 언어의 텍스트 파일 목록과 쌍을 이루어야하며, 여기서 소스 언어 텍스트 파일의 줄 (예 : 문장)은 대상 언어 텍스트 파일의 줄에 일대일 서신을 갖습니다.
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
먼저 실행하여 원시 텍스트 파일을 tfrecord 파일로 변환해야합니다.
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab 참고 :이 과정에는 훈련 코퍼스에서 서브 워드 토큰의 어휘를 "학습"하는 것이 포함되며, 이는 파일 vocab.subtokens 및 vocab.alphabet 에 저장됩니다. 어휘는 나중에 원시 텍스트 문자열을 서브 워드 토큰 ID로 인코딩하거나 원시 텍스트 문자열로 다시 사용하는 데 사용됩니다.
자세한 사용 정보는 실행하십시오
python commons/create_tfrecord_machine_translation.py --help샘플 데이터는 data_sources.txt를 참조하십시오
모델을 훈련시키기 위해 실행하십시오
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir 는 tfrecord 파일을 저장 vocab.subtokens 디렉토리이며, vocab_path create_tfrecord_machine_translation.py 실행 vocab.alphabet 생성 된 vocab 파일의 model_dir 이름의 경로입니다.
자세한 사용 정보는 실행하십시오
python run_trainer.py --help평가는 소스 시퀀스를 대상 시퀀스로 변환하고 예측 된 대상과지면 대상 시퀀스 사이의 BLEU 점수를 계산하는 것입니다.
사전에 사전 모델을 평가하려면 실행하십시오
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename 및 target_text_filename 각각 소스와 대상 시퀀스를 보유하는 텍스트 파일의 경로입니다.
참고 명령 줄 인수 target_text_filename 선택 사항입니다. 삭제하면 평가자가 추론 모드로 실행되며 변환 만 출력 파일에 기록됩니다.
보다 자세한 사용 정보를 보려면 실행하십시오
python run_evaluator.py --help 주의 메커니즘은 다른 토큰에 대한주의가 어떻게 분포되는지 이해하기 위해 시각화 될 수있는 토큰 간 유사성을 계산합니다. python run_evaluator.py 실행하면주의 웨이트 매트릭스는 다음 항목의 덕트를 저장하는 삽화 attention_xxxx.npy 제출하도록 저장됩니다.
src : numpy array of shape [batch_size, src_seq_len] . 각 행은 1 ( EOS_ID )으로 끝나고 0으로 패딩하는 일련의 토큰 ID입니다.tgt : Numpy Shape of Shape [batch_size, tgt_seq_len] . 각 행은 1 ( EOS_ID )으로 끝나고 0으로 패딩하는 일련의 토큰 ID입니다.src_src_attention : numpy 모양의 배열 [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : numpy 모양의 배열 [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : numpy 모양의 배열 [batch_size, num_heads, tgt_seq_len, tgt_seq_len]주의 웨이트는 실행을 통해 표시 할 수 있습니다.
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files 여기서 head 는 [0, num_heads - 1] 의 정수이고 index [0, batch_size - 1] 의 정수입니다.
아래는 영어 (소스 언어)의 세 문장과 독일어 (대상 언어)로 번역 된 문장입니다.
소스 langauge의 입력 문장
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
대상 언어로 번역 된 문장
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
변압기 모델은 세 가지 유형의 관심을 계산합니다.
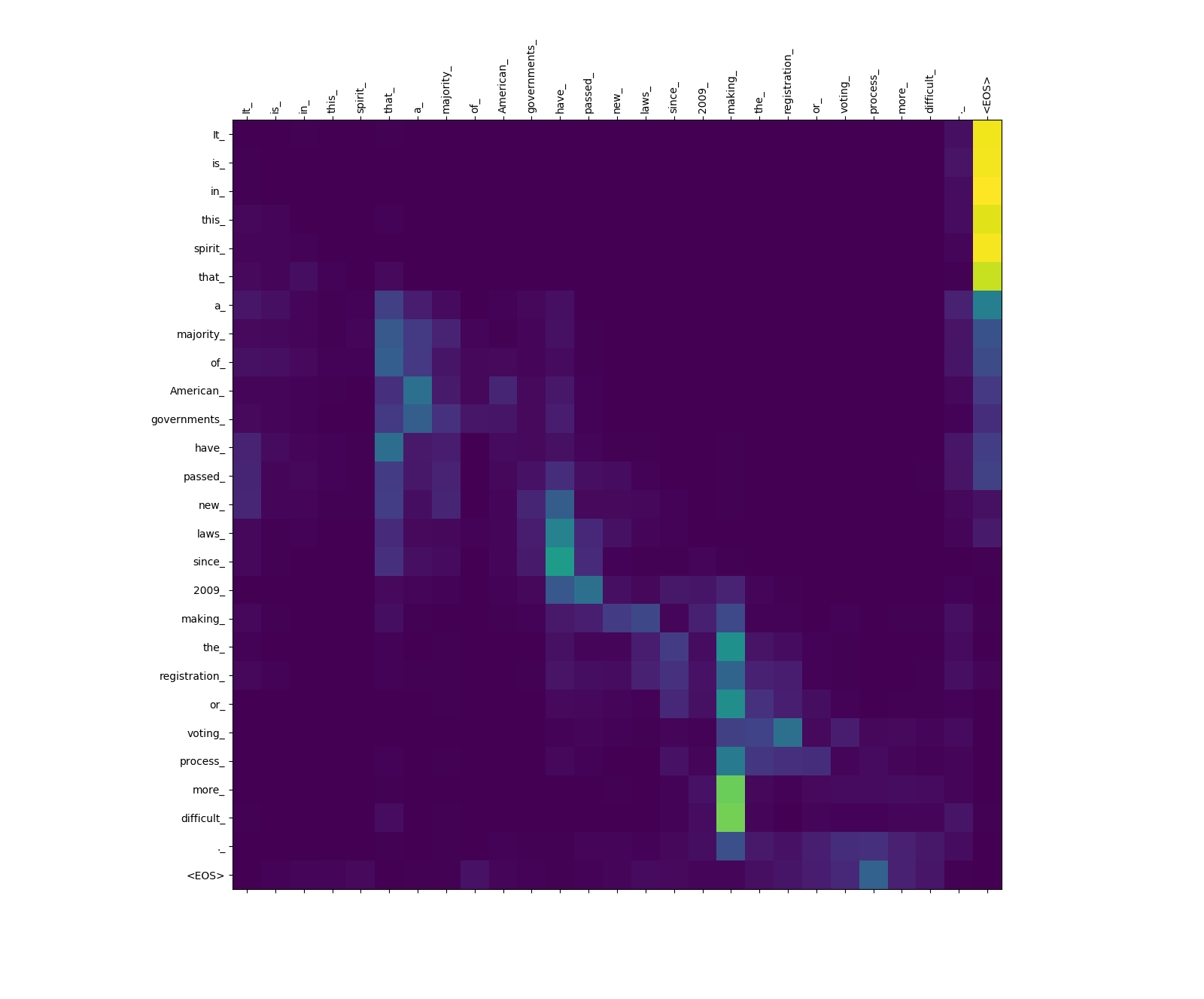
소스-소스주의 관심 웨이트.
more_ 및 difficult_ _에서 making_ 까지 주의력을 주목하십시오. 그들은 "Make ... 더 어려워"라는 문구를 완성하려고 할 때 동사 "Make"에 대한 "전망대에"입니다.
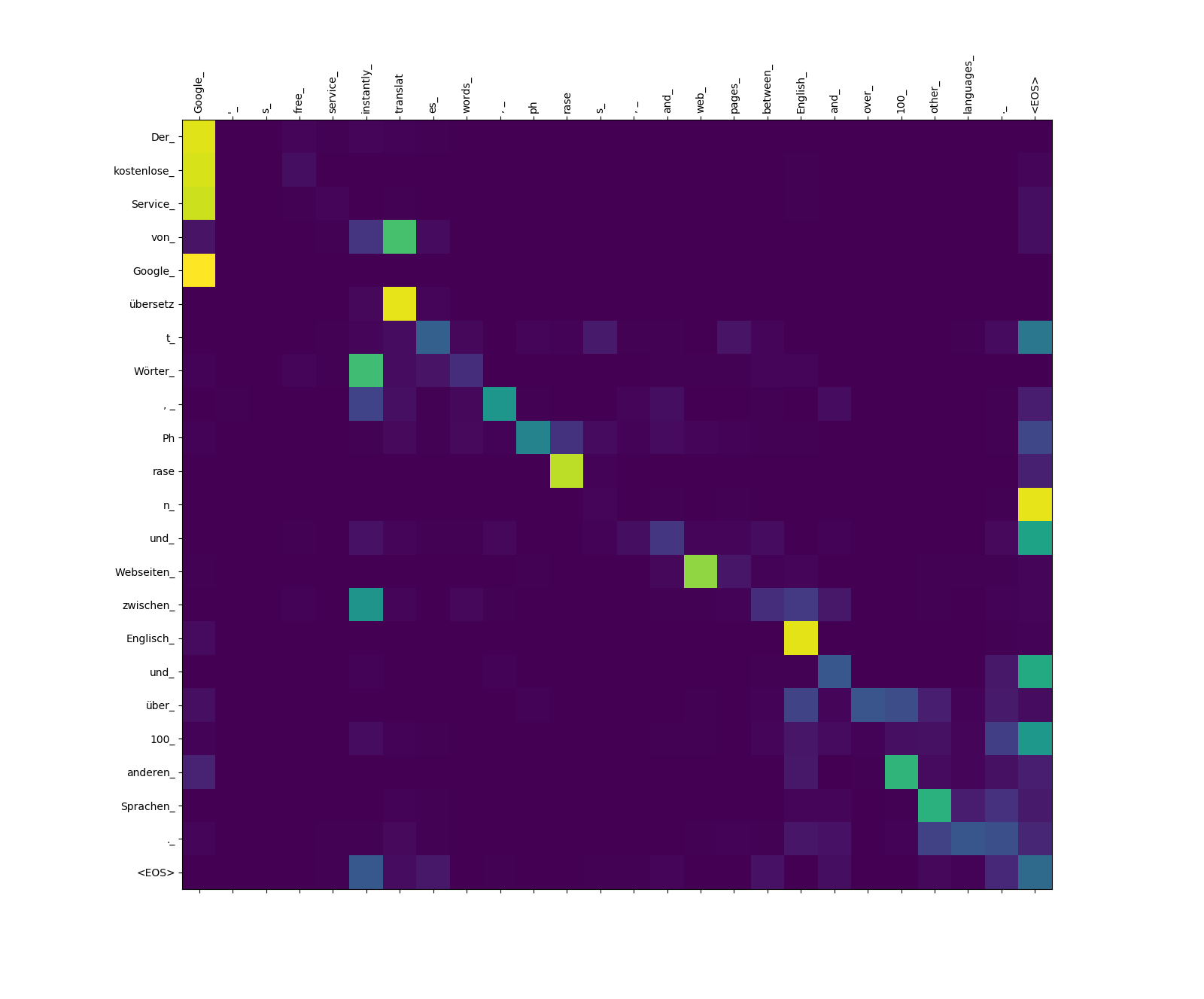
목표-소스주의 관심 웨이트.
übersetz (대상)에서 translat (Source), Webseiten (Target)에서 web (소스)까지의 관심을 주목하십시오. 이것은 아마도 독일어와 영어의 동의어 때문일 수 있습니다.
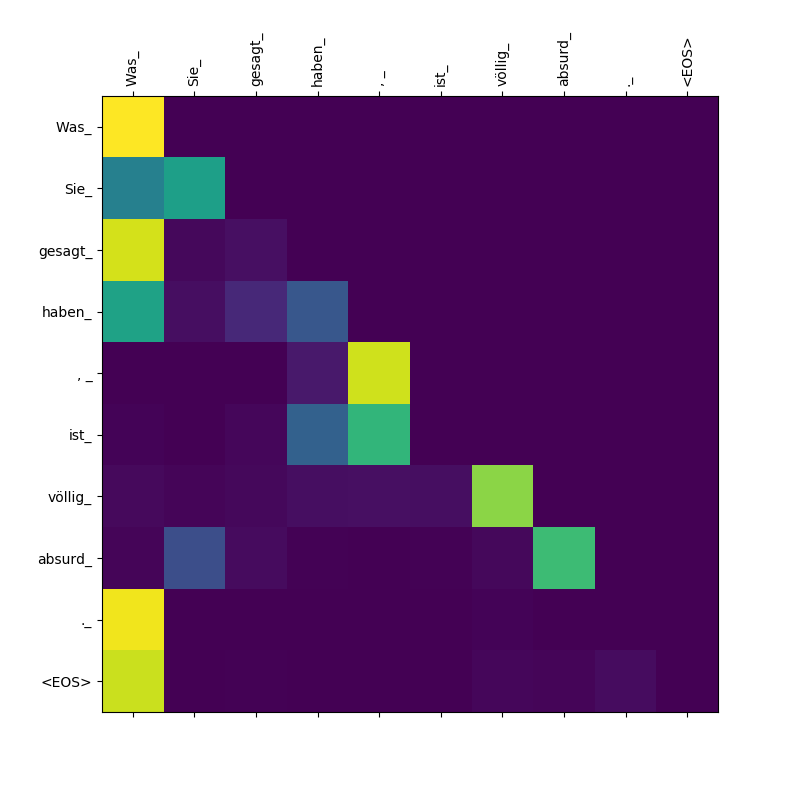
목표 대 표적에 대한 관심 웨이트.
Was , gesagt , Sie_ haben_ 의해 Was 된 관심에 주목하십시오. 디코더 가이 하위 톨렌을 뱉어 내면서이 조항의 범위를 "알아야"( " Was Sie gesagt haben 것").


