tf transformer
1.0.0
Esta é uma implementação do TensorFlow 2.x do modelo de transformador (é tudo o que você precisa) para a tradução da máquina neural (NMT).
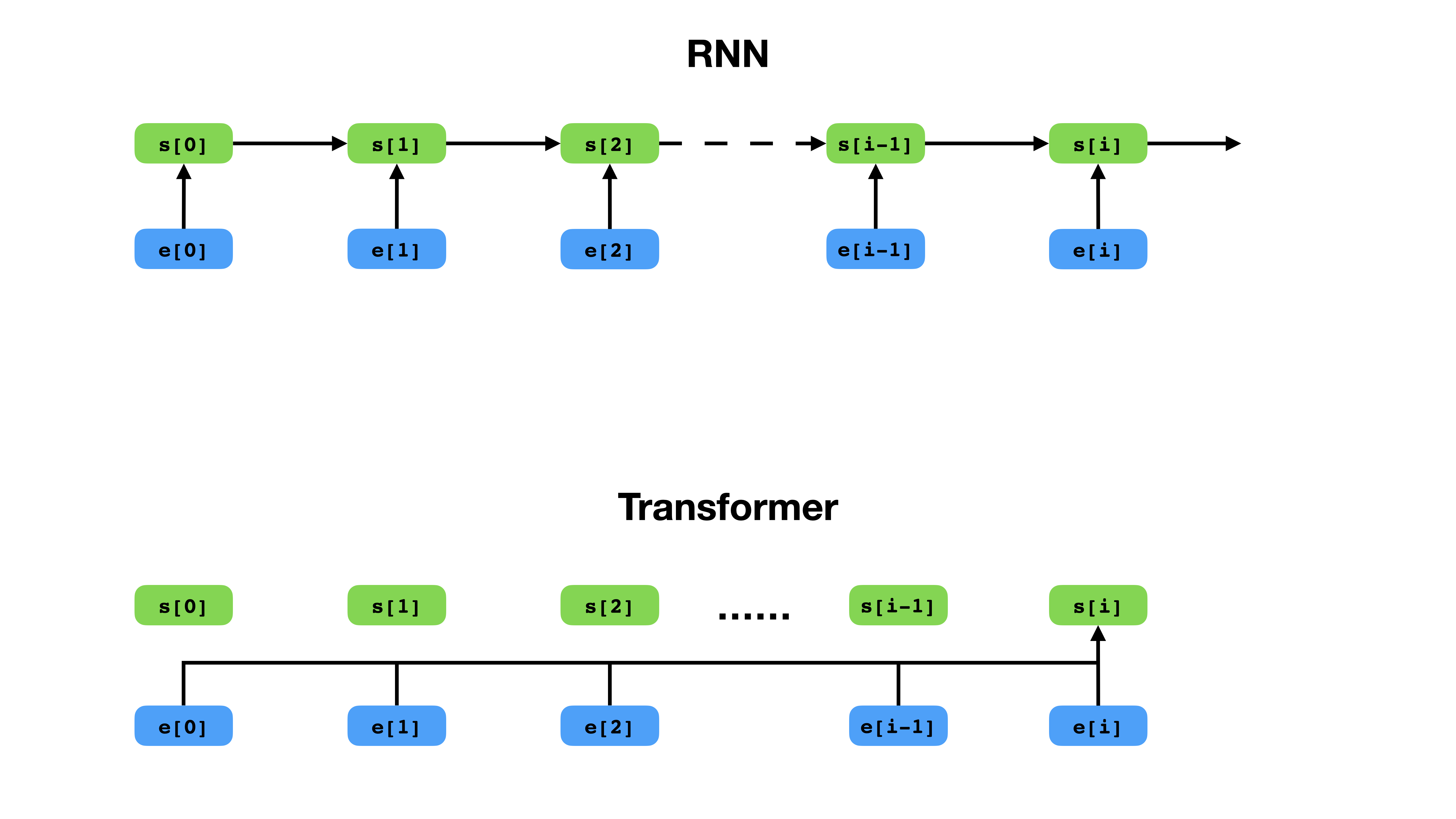
O transformador tem uma maneira mais flexível de representar o contexto em comparação com o RNN.
O Transformer é uma arquitetura de rede neural profunda para modelagem de seqüências, que é tarefa para estimar a probabilidade de tokens em uma sequência baseada em seu contexto textual. Enquanto as redes neurais recorrentes entram em colapso nas incorporações de toda a história dos tokens de contexto em um único vetor, o Transformer tem acesso ao vetor de incorporação de cada token individual, não importa o quão longe o contexto se estenda. Isso o torna adequado para modelar as relações de dependência de longa distância, que são essenciais para os recentes avanços nos métodos para o aprendizado de representação de texto, como BERT e GPT-2.
No centro do transformador, está o mecanismo de auto-ataque , onde o objetivo é calcular uma representação contextualizada de cada token em uma sequência, permitindo que eles "prestem atenção" entre si. Given the initial vector representations e[i] for all positions i , it first applies linear projections to obtain vectors q[i] , k[i] , v[i] , where k 's and v 's play the role of the key and value of a knowledge base about the sequence content, which is to be queried by q[i] to determine which tokens are most similar to the token at index i . O resultado da consulta são simplesmente os escores de similaridade entre q[i] e k de K (normalmente produtos de pontos), que são usados como pesos para calcular uma média ponderada dos v 's como a nova representação de e[i] . Observe que q , k e v são derivados da mesma sequência, o que significa que a sequência está efetivamente consulta a si mesma (daí o nome de auto-atimento).
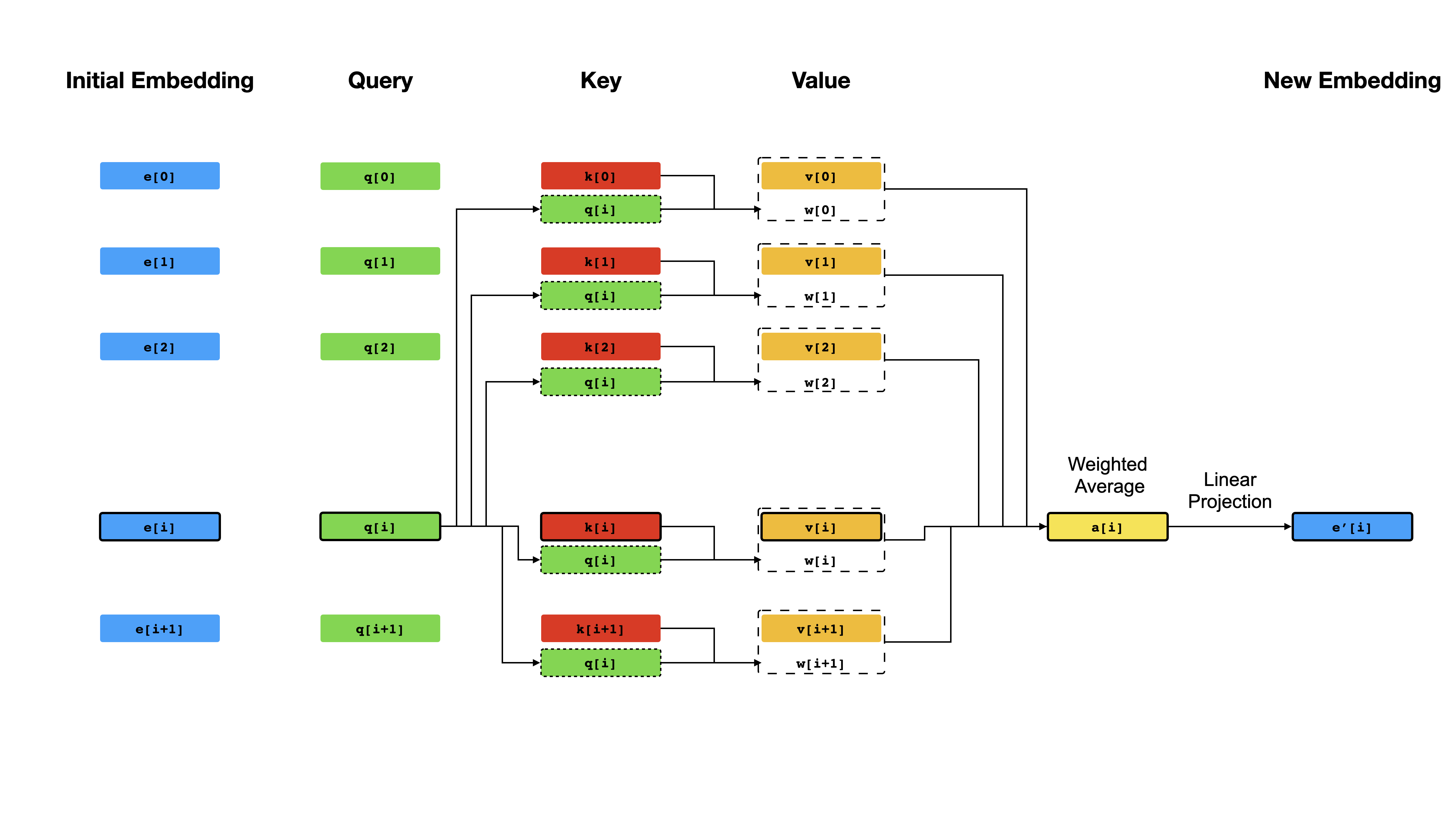
Mecanismo de auto-ataque.
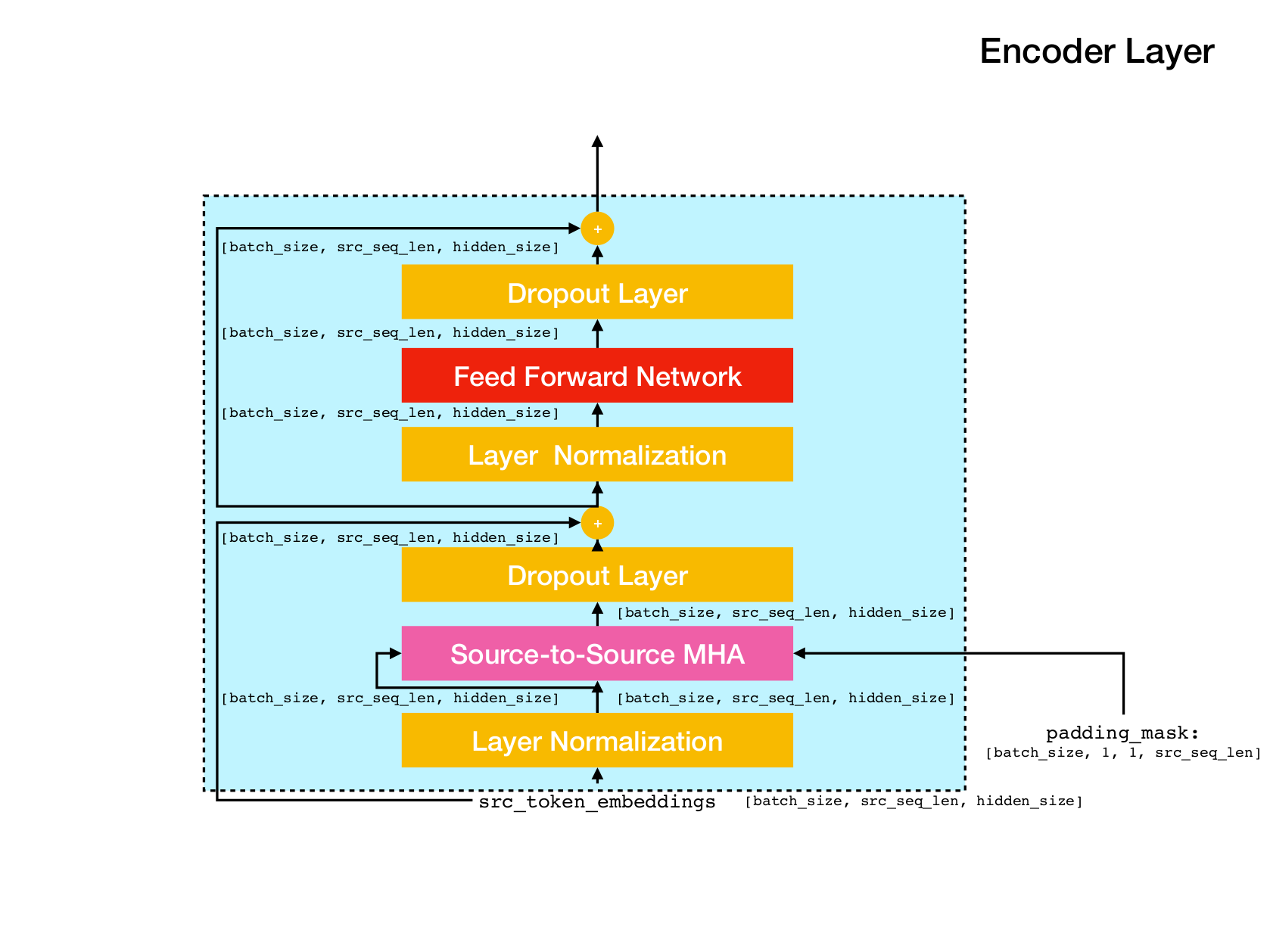
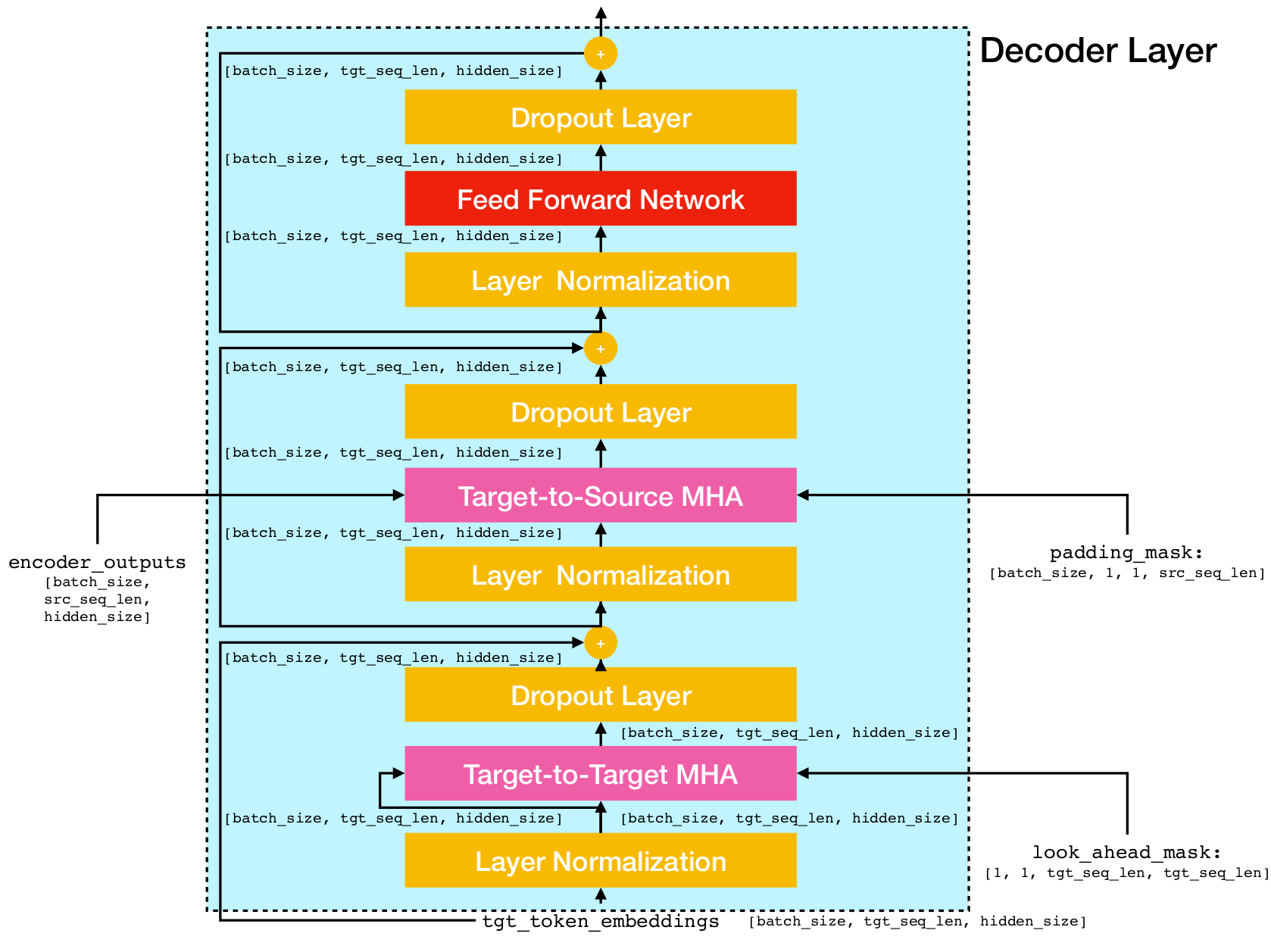
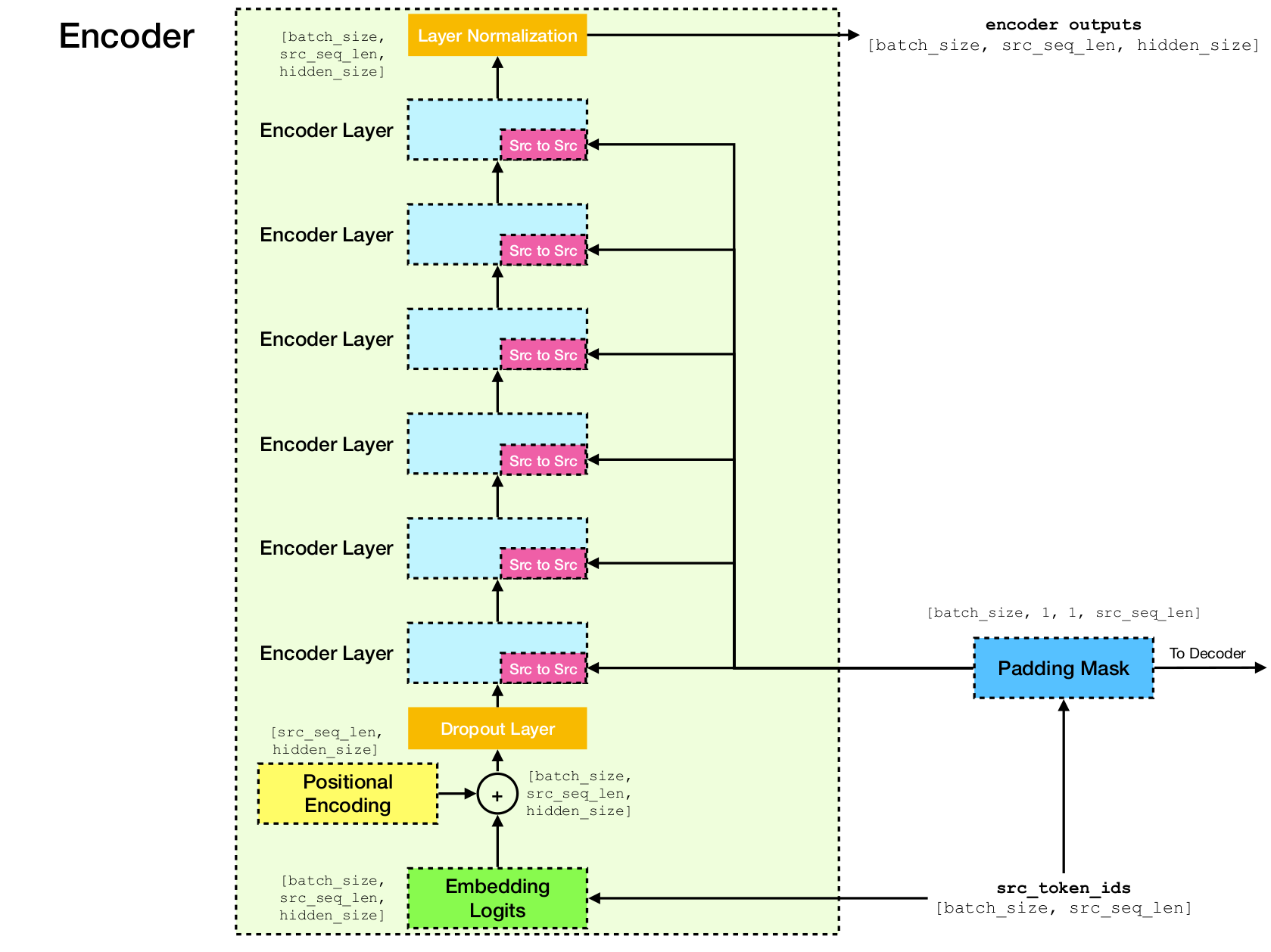
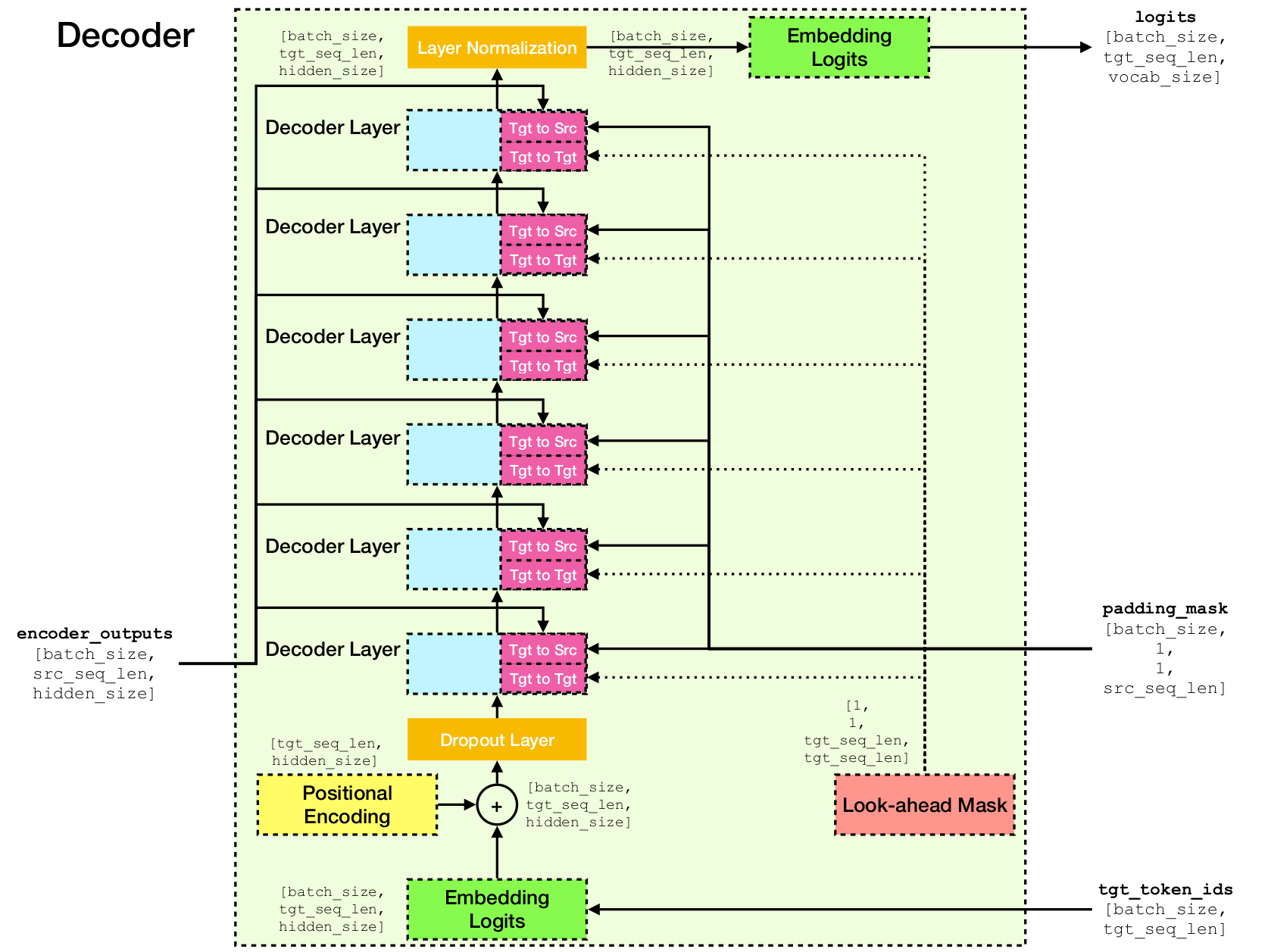
Arquitetura de rede de transformadores.
Esta implementação é baseada no TensorFlow 2.x e no Python3. Além disso, o NLTK é necessário para calcular a pontuação do BLEU para avaliação.
Você pode clonar este repositório executando
git clone [email protected]:chao-ji/tf-transformer.gitEm seguida, clone e atualize o submódulo executando
cd tf-transformer
git submodule update --init --recursiveO corpus de treinamento deve estar na forma de uma lista de arquivos de texto na linguagem de origem, emparelhados com uma lista de arquivos de texto na linguagem de destino, onde as linhas (ou seja, frases) nos arquivos de texto de linguagem de origem têm correspondência individual para linhas nos arquivos de texto de idioma de destino
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
Primeiro, você precisa converter arquivos de texto bruto em arquivos Tfrecord executando
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab Nota: Este processo envolve "aprender" um vocabulário de tokens de subpaltos do corpus de treinamento, que é salvo para os arquivos vocab.subtokens e vocab.alphabet . O vocabulário será usado posteriormente para codificar a string de texto bruto em IDs de token de subbordo ou decodificá -los de volta à sequência de texto bruto.
Para informações de uso detalhadas, execute
python commons/create_tfrecord_machine_translation.py --helpPara dados de amostra, consulte o data_sources.txt
Para treinar um modelo, execute
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir é o diretório que armazena os arquivos tfrecord, vocab_path é o caminho para o nome da base dos arquivos de vocabulário vocab.subtokens e vocab.alphabet (ou seja, caminho para vocab ) gerado por create_tfrecord_machine_translation.py , e model_dir é o conscientize que o checkpoint é que os arquivos de checkpoint seriam savings.
Para informações de uso detalhadas, execute
python run_trainer.py --helpA avaliação envolve a tradução de uma sequência de origem na sequência alvo e calculando o escore Bleu entre a sequência alvo prevista e de truta fundamental.
Para avaliar um modelo pré -terenciado, execute
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename e target_text_filename são os caminhos para os arquivos de texto que mantêm as seqüências de origem e destino, respectivamente.
Nota O argumento da linha de comando target_text_filename é opcional - se deixado de fora, o avaliador será executado no modo de inferência , onde apenas as traduções serão gravadas no arquivo de saída.
Para informações de uso mais detalhadas, execute
python run_evaluator.py --help Observe que o mecanismo de atenção calcula semelhanças token-token que podem ser visualizadas para entender como a atenção é distribuída em diferentes tokens. Quando você executa python run_evaluator.py as matrizes de peso de atenção serão salvas para arquivar attention_xxxx.npy , que armazena um ditado das seguintes entradas:
src : Matriz de forma Numpy [batch_size, src_seq_len] , onde cada linha é uma sequência de IDs de token que termina com 1 ( EOS_ID ) e acolchoado com zeros.tgt : Numpy Matriz de forma [batch_size, tgt_seq_len] , onde cada linha é uma sequência de IDs de token que termina com 1 ( EOS_ID ) e acolchoado com zeros.src_src_attention : Numpy Matriz of Shape [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : Numpy Matriz of Shape [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : Numpy Matriz of Shape [batch_size, num_heads, tgt_seq_len, tgt_seq_len]Os pesos de atenção podem ser exibidos em execução:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files onde head é um número inteiro em [0, num_heads - 1] e index é um número inteiro em [0, batch_size - 1] .
A seguir, são mostrados três frases em inglês (linguagem de origem) e suas traduções em alemão (idioma de destino).
Sentenças de entrada na fonte Langauge
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
Frases traduzidas no idioma de destino
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
O modelo do transformador calcula três tipos de atenção:
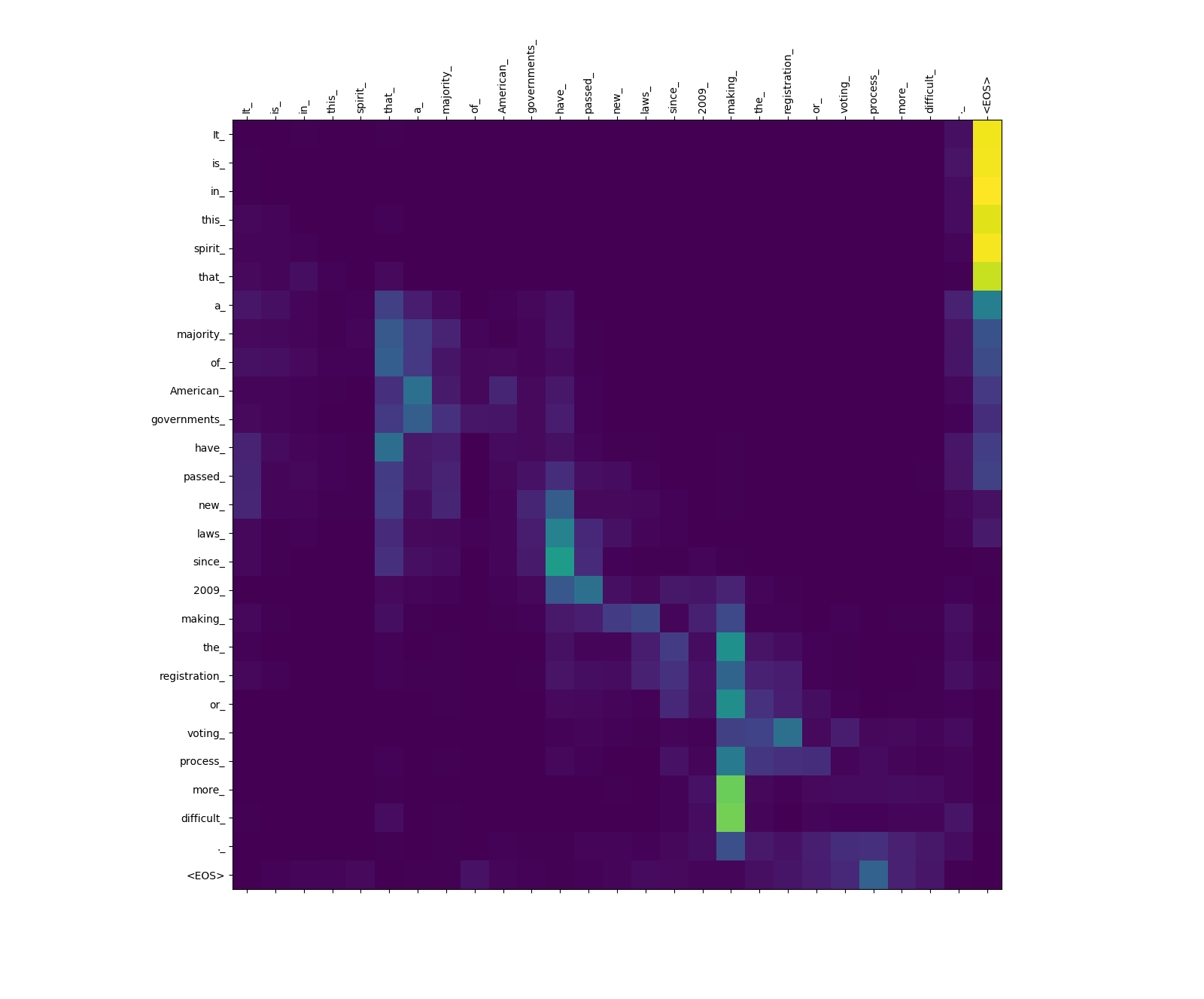
Pesos de atenção da fonte a fonte.
Observe o peso da atenção de more_ e difficult_ de making_ - eles estão "no mirante" para o verbo "make" ao tentar concluir a frase "tornar ... mais difícil".
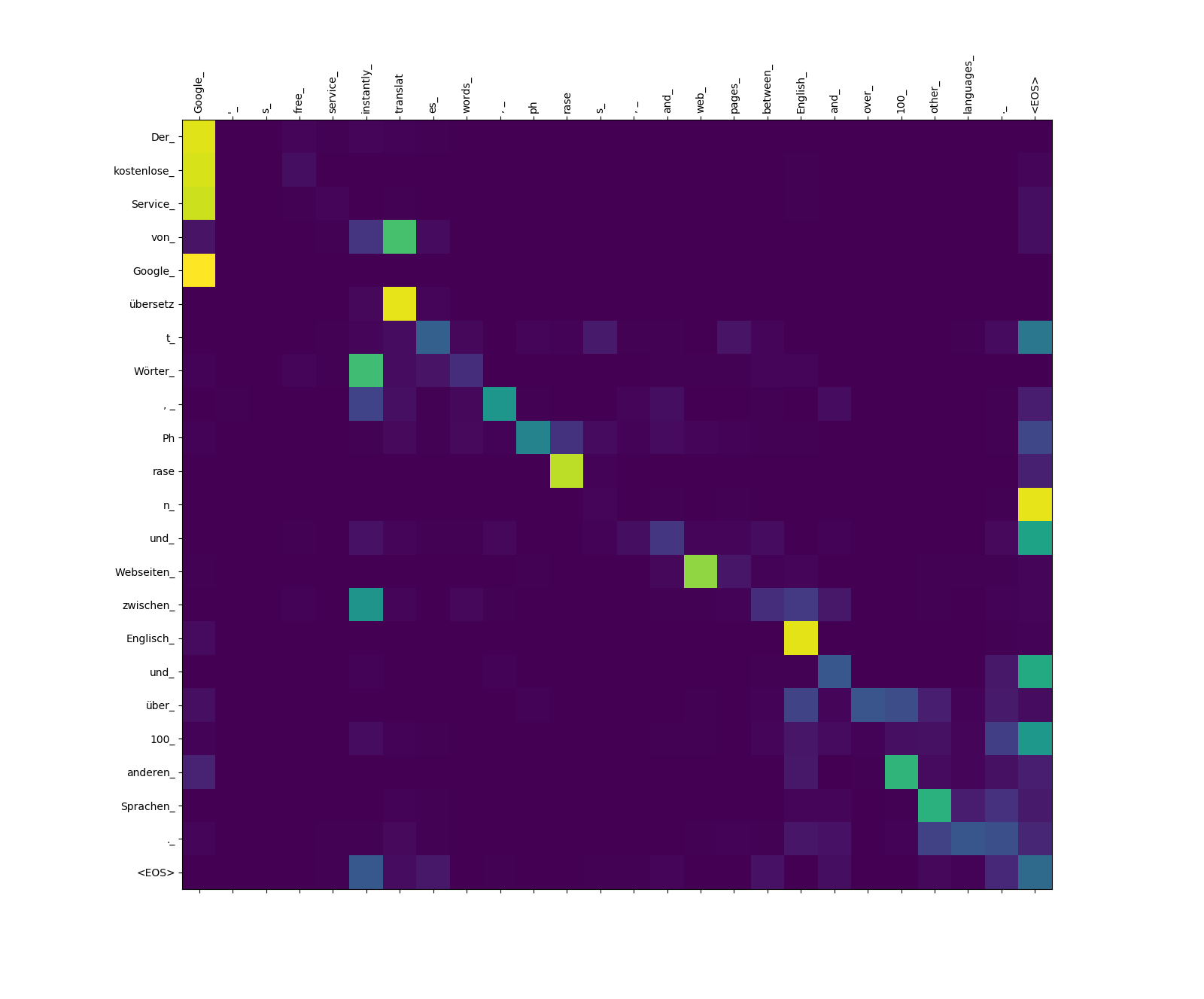
Pesos de atenção de alvo a fonte.
Observe o peso da atenção de übersetz (Target) para translat (fonte) e do Webseiten (Target) para web (fonte), etc. Isso provavelmente se deve ao seu sinônimo de alemão e inglês.
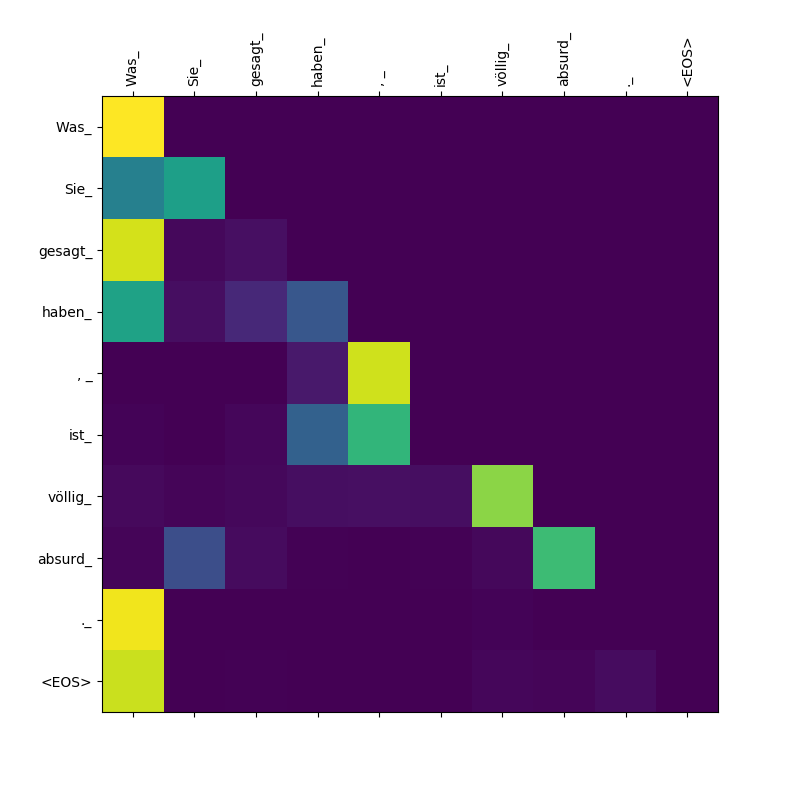
Pesos de atenção de alvo a alvo.
Observe que a atenção prestada Was por isso Was , Sie_ , gesagt , haben_ - Como o decodificador cospe essas sugerentes, ele precisa "estar ciente" do escopo da cláusula Was Sie gesagt haben (que significa "o que você disse").


