tf transformer
1.0.0
Dies ist eine TensorFlow 2.x -Implementierung des Transformatormodells (Aufmerksamkeit ist alles, was Sie brauchen) für die neuronale maschinelle Übersetzung (NMT).
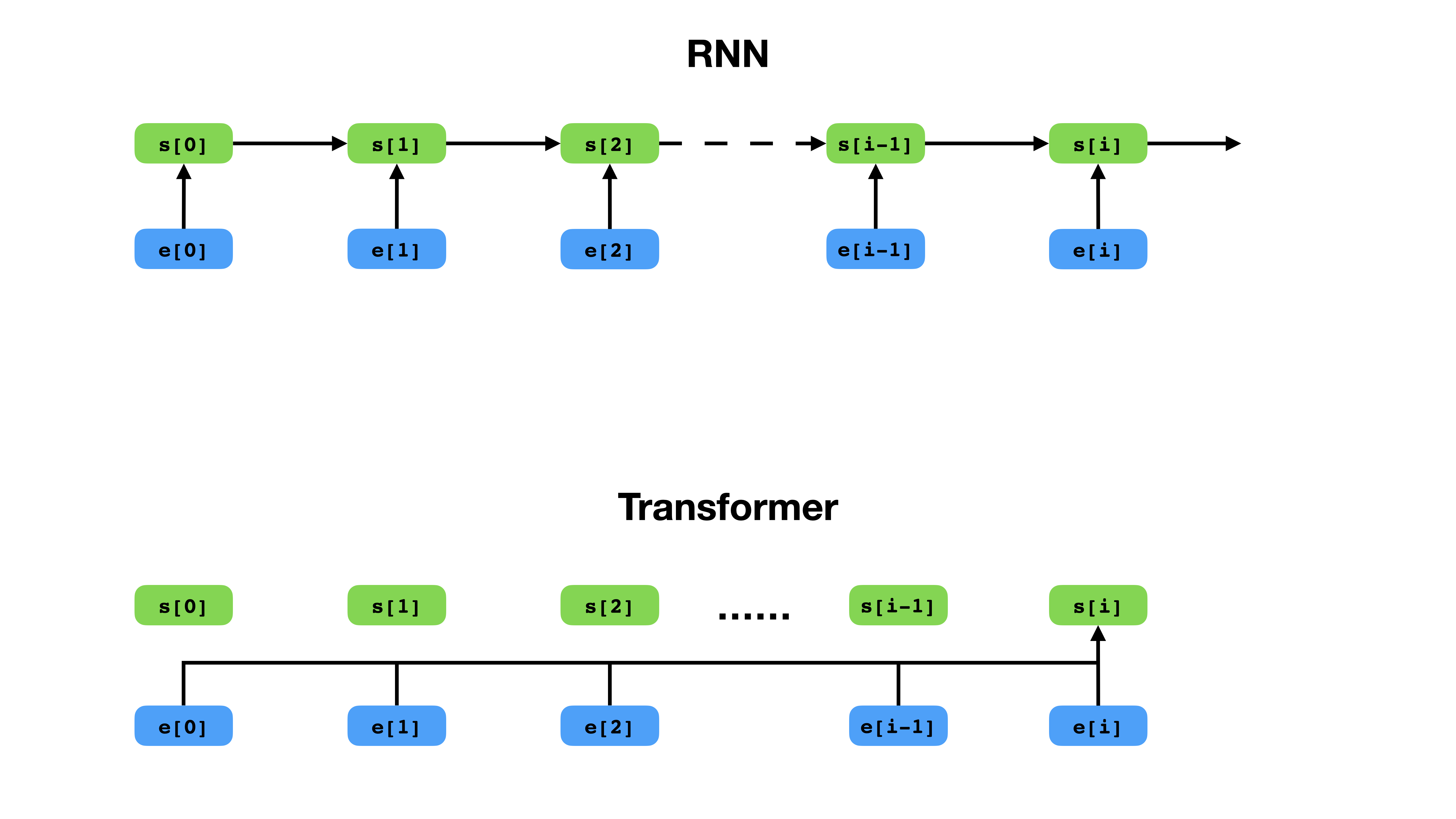
Transformator hat eine flexiblere Möglichkeit, den Kontext im Vergleich zu RNN darzustellen.
Transformator ist eine tiefe neuronale Netzwerkarchitektur für die Sequenzmodellierung, die die Aufgabe ist, die Wahrscheinlichkeit von Token in einer Sequenz basierend auf ihrem Textkontext zu schätzen. Während wiederkehrende neuronale Netze die Einbettungen der gesamten Geschichte von Kontext -Token in einen einzelnen Vektor zusammenbrechen, hat Transformator Zugang zum Einbettungsvektor jedes einzelnen Tokens, unabhängig davon, wie weit der Kontext erstreckt. Dies macht es gut für die Modellierung von Fernbeziehungen für Fernabhängungen, die für die jüngsten Durchbrüche in Methoden zum Lernen von Textrepräsentationen wie Bert und GPT-2 von entscheidender Bedeutung sind.
Im Kern des Transformators steht der Selbstbekämpfungsmechanismus , bei dem das Ziel darin besteht, eine kontextualisierte Darstellung jedes Tokens in einer Sequenz zu berechnen, indem sie sich gegenseitig "aufpassen" lassen. Angesichts k anfänglichen Vektor -Darstellungen e[i] k[i] q[i] v[i] i v es zunächst lineare Projektionen an q[i] um Vektoren zu erhalten i Das Ergebnis der Abfrage sind einfach die Ähnlichkeitswerte zwischen q[i] und k (typischerweise dot-produkte), die als Gewichte verwendet werden, um einen gewichteten Durchschnitt der v als neue Darstellung von e[i] zu berechnen. Beachten Sie, dass q , k und v aus derselben Sequenz abgeleitet sind, was bedeutet, dass sich die Sequenz selbst effektiv selbst abfragt (daher der Name Selbstbegegnung).
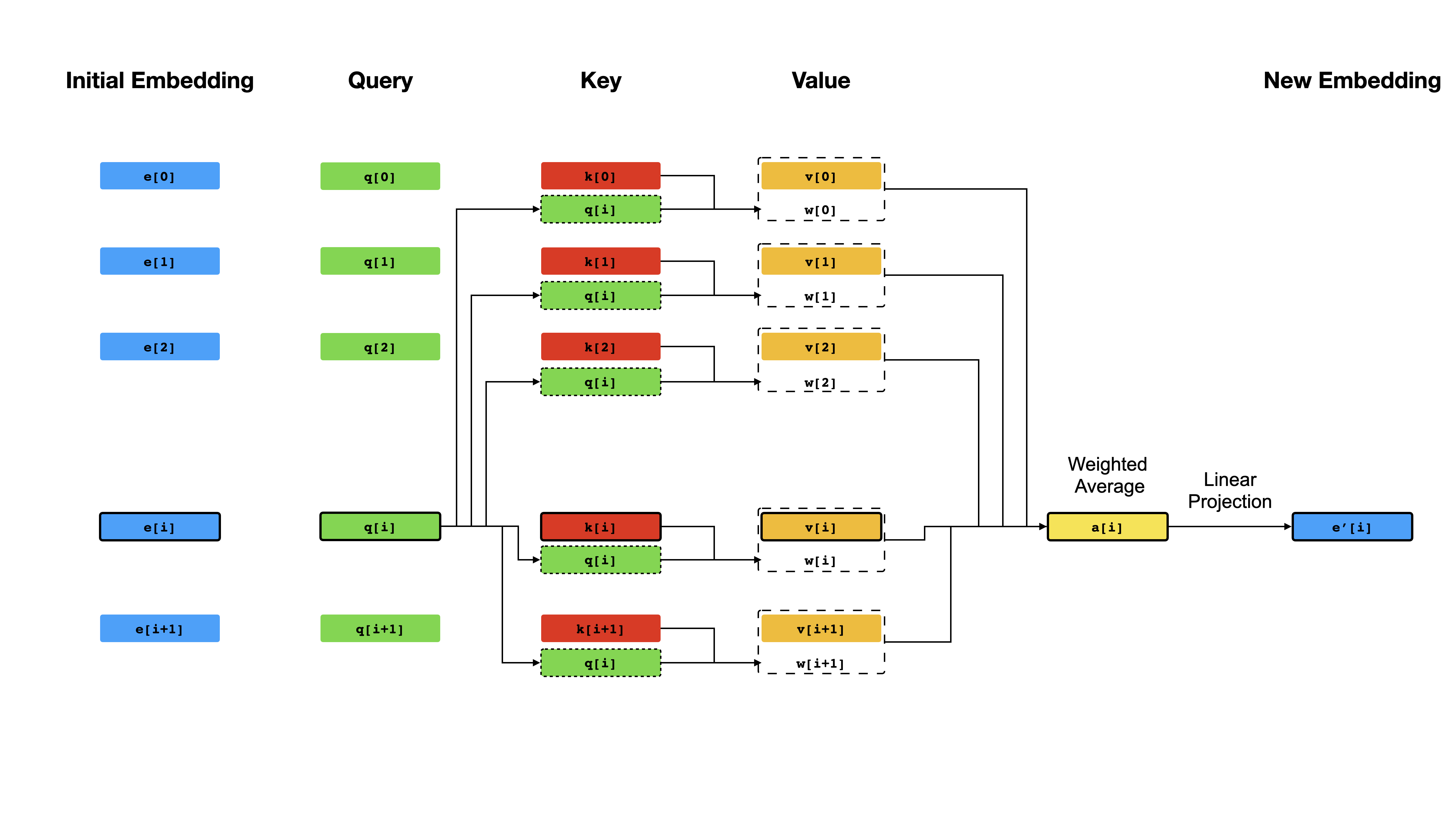
Selbstbekämpfungsmechanismus.
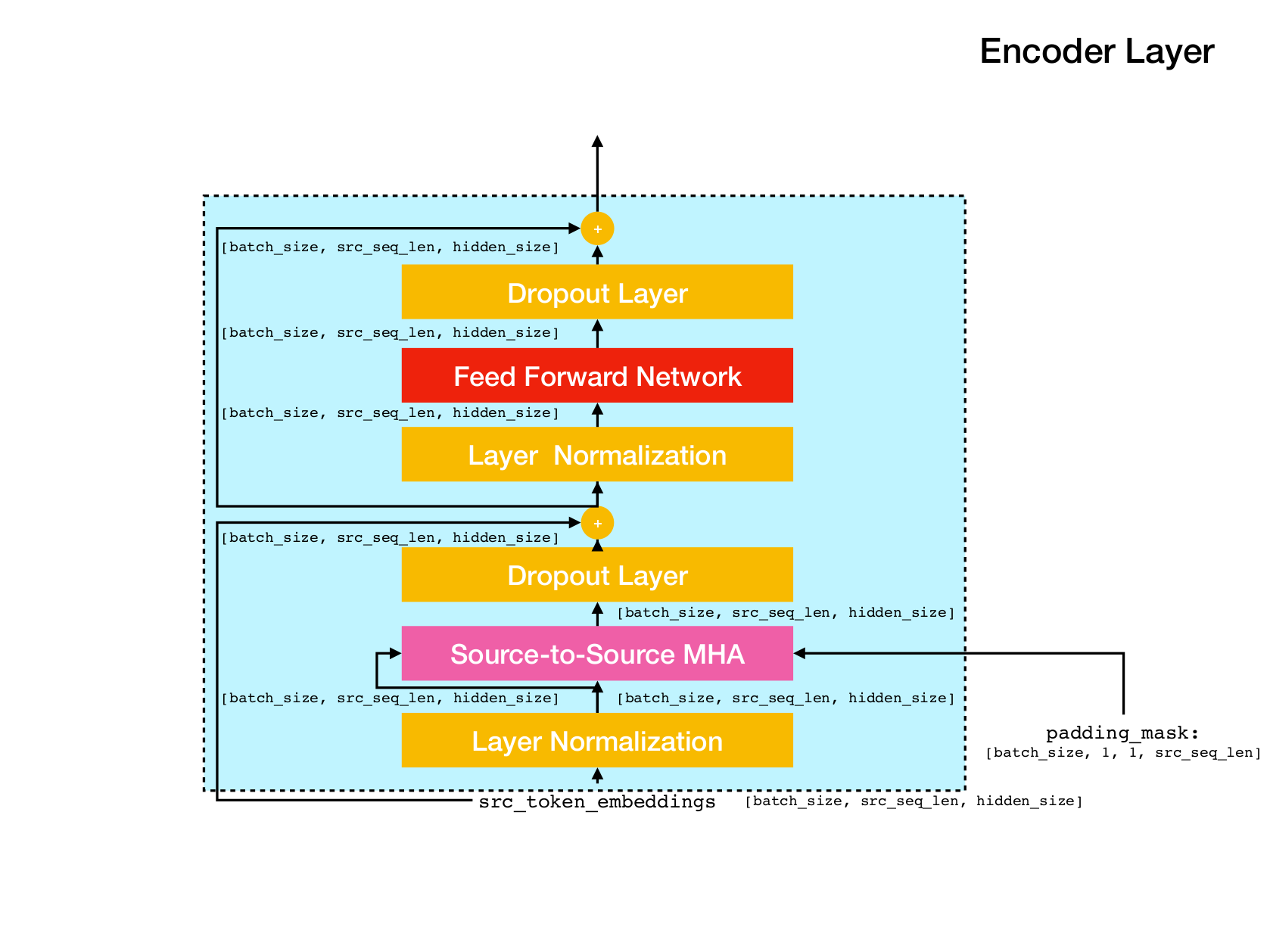
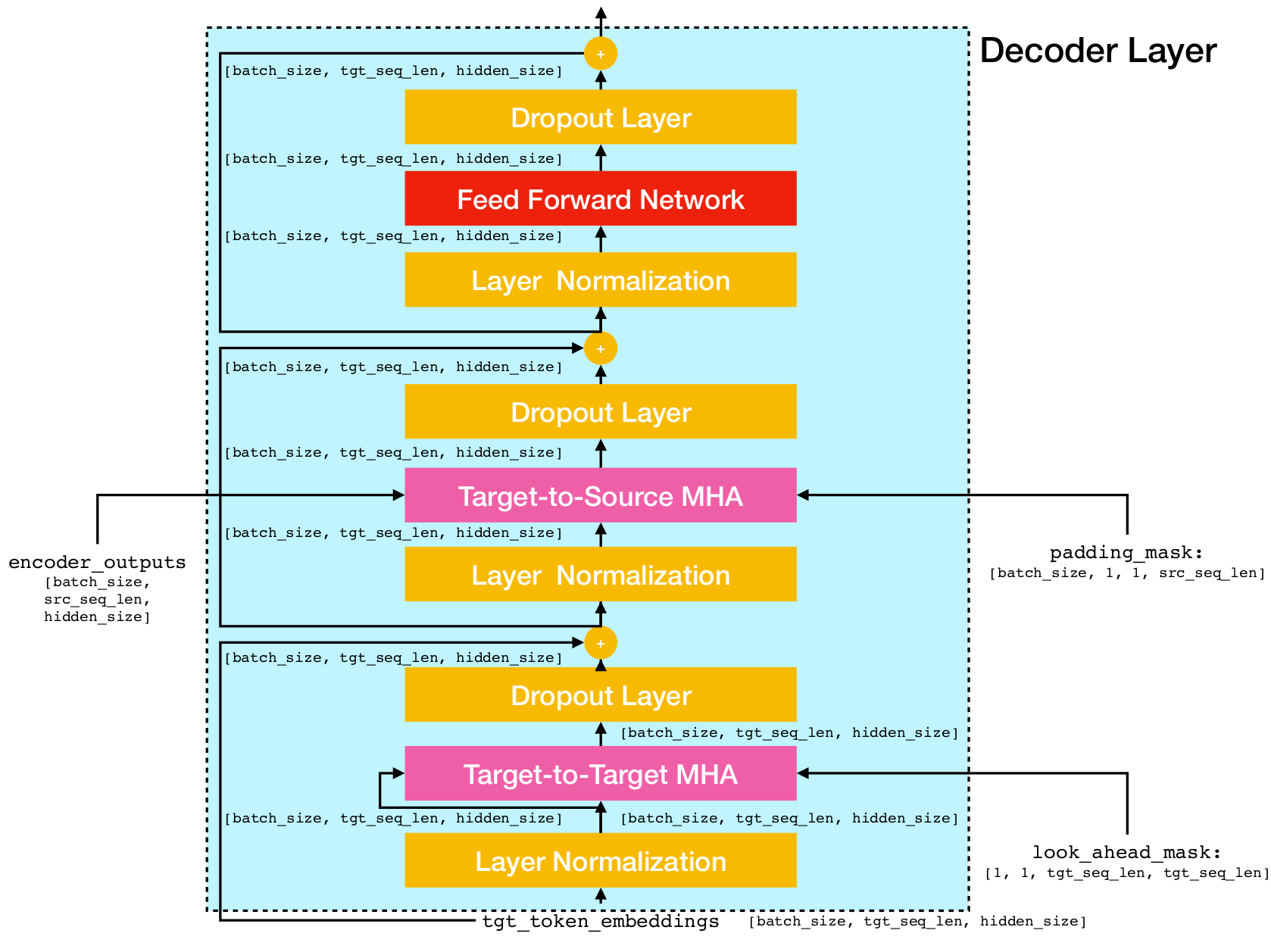
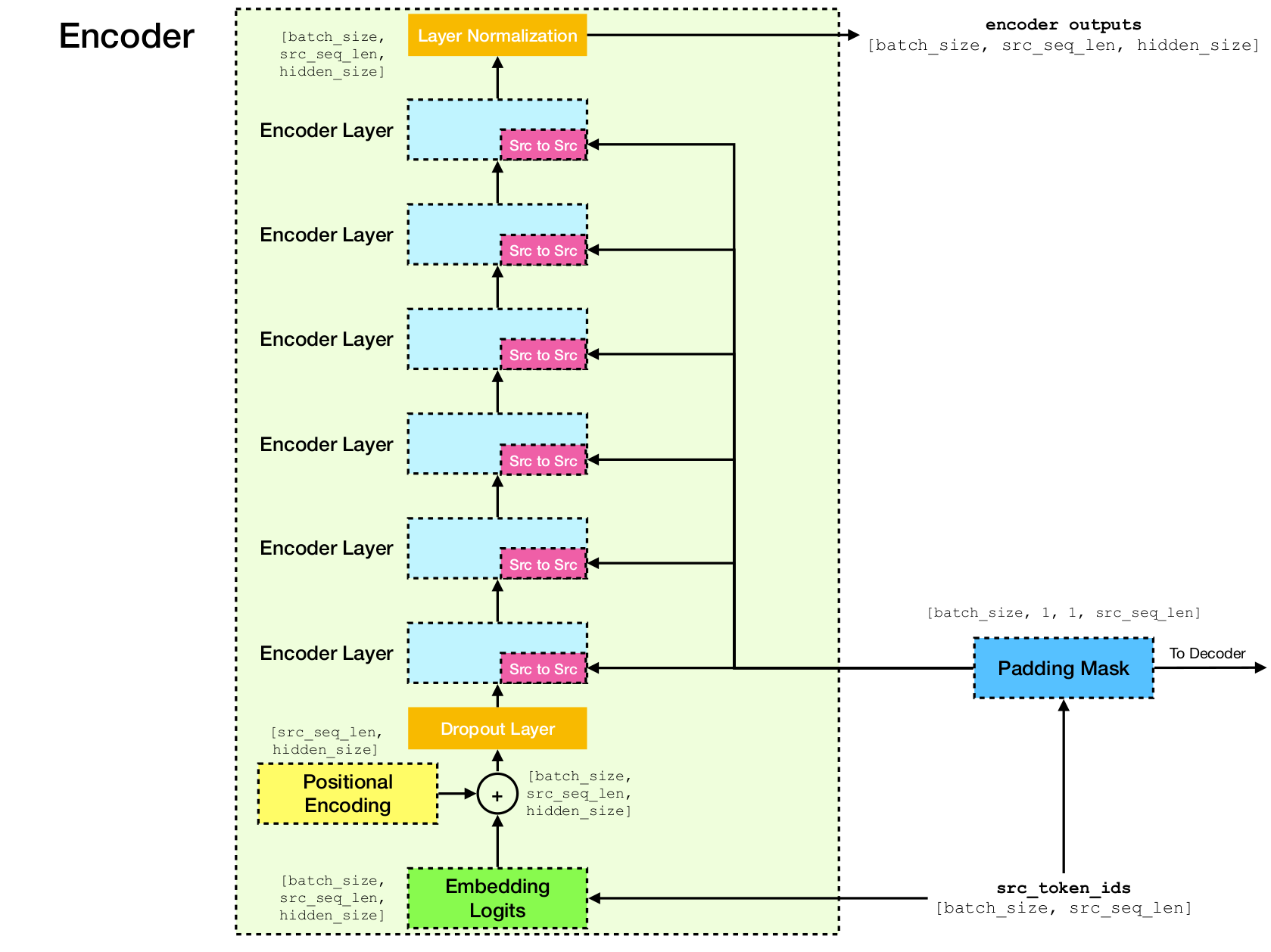
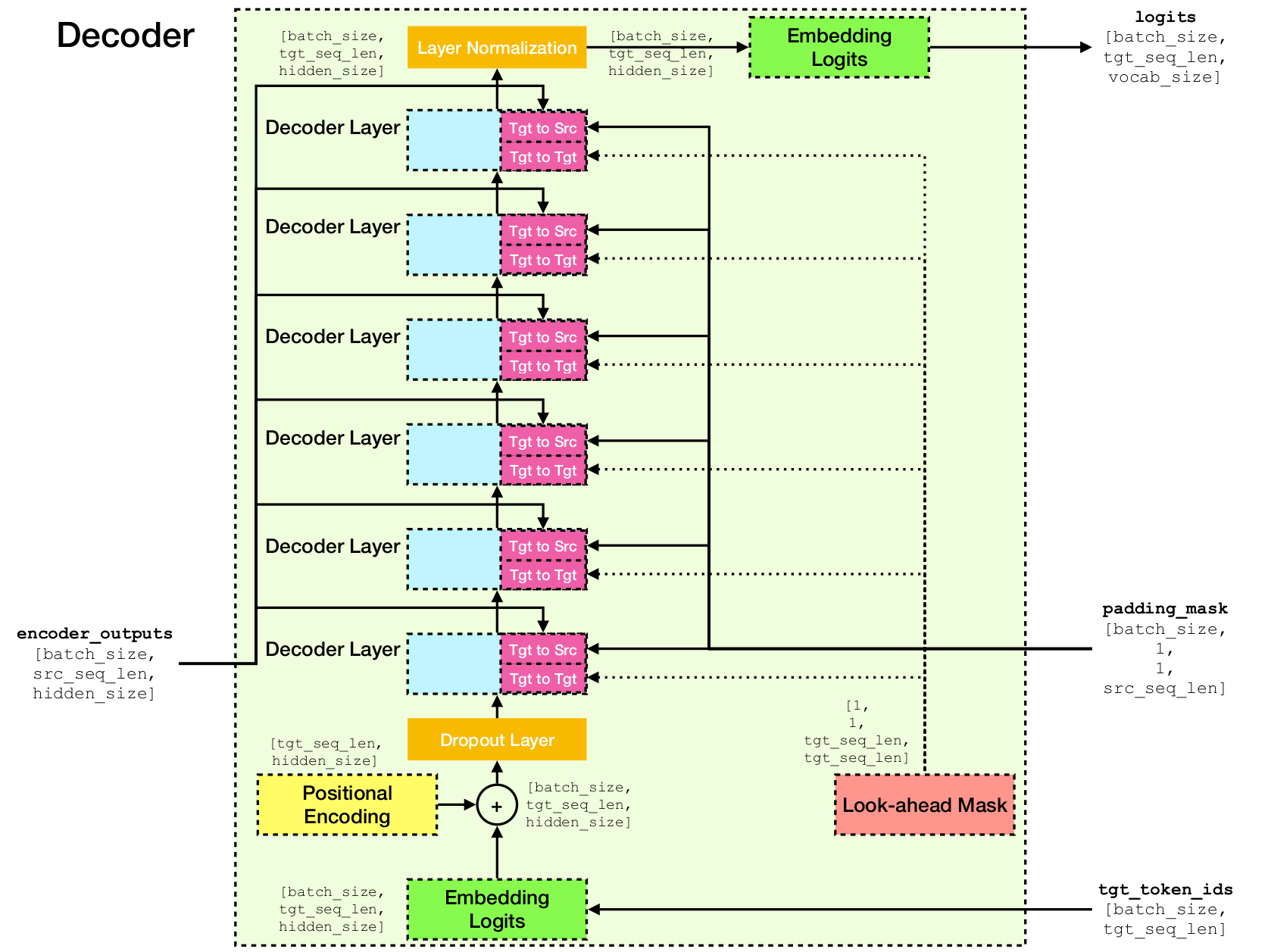
Transformator -Netzwerkarchitektur.
Diese Implementierung basiert auf TensorFlow 2.x und Python3. Darüber hinaus ist NLTK erforderlich, um die BLEU -Bewertung zur Bewertung zu berechnen.
Sie können dieses Repository durch Ausführen klonen
git clone [email protected]:chao-ji/tf-transformer.gitDann klonen und aktualisieren Sie das Submodul, indem Sie ausführen
cd tf-transformer
git submodule update --init --recursiveDas Trainingskorpus sollte in Form einer Liste von Textdateien in der Quellsprache sein, gepaart mit einer Liste von Textdateien in der Zielsprache, wobei die Zeilen (dh Sätze) in Quellsprachentextdateien eins zu eins entsprechend den Zeilen in Zielsprache Textdateien haben
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
Zuerst müssen Sie Rohtextdateien durch Ausführen in TFRECORD -Dateien konvertieren
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab Hinweis: Dieser Prozess beinhaltet das "Lernen" eines Vokabulars von Subword -Token aus dem Trainingskorpus, das in Dateien vocab.subtokens und vocab.alphabet gespeichert wird. Der Wortschatz wird später verwendet, um die Rohtext -Zeichenfolge in Subword -Token -IDs zu codieren oder sie wieder in die RAW -Textzeichenfolge zu dekodieren.
Für detaillierte Nutzungsinformationen führen Sie aus
python commons/create_tfrecord_machine_translation.py --helpFür Beispieldaten finden Sie in Data_Sources.txt
Um ein Modell zu trainieren, laufen Sie
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir ist das Verzeichnis vocab.subtokens das die TFRECORD -Dateien speichert model_dir vocab_path ist der Weg vocab.alphabet vocab der create_tfrecord_machine_translation.py . ein vorheriger Kontrollpunkt).
Für detaillierte Nutzungsinformationen führen Sie aus
python run_trainer.py --helpDie Bewertung umfasst die Übersetzung einer Quellsequenz in die Zielsequenz und die Berechnung des BLEU -Scores zwischen der vorhergesagten und bodenstruth -Zielsequenz.
Um ein vorgezogenes Modell zu bewerten, laufen Sie
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename und target_text_filename sind die Pfade zu den Textdateien, die Quell- bzw. Zielsequenzen enthalten.
Beachten Sie, dass das Befehlszeilenargument target_text_filename optional ist - wenn ausgelassen wird, wird der Evaluator im Inferenzmodus ausgeführt, wobei nur die Übersetzungen in die Ausgabedatei geschrieben werden.
Für detailliertere Nutzungsinformationen führen Sie aus
python run_evaluator.py --help Beachten Sie, dass der Aufmerksamkeitsmechanismus Token-to-Too-Ähnlichkeiten berechnet, die sichtbar gemacht werden können, um zu verstehen, wie die Aufmerksamkeit über verschiedene Token verteilt wird. Wenn Sie python run_evaluator.py ausführen, werden die Aufmerksamkeitsgewichtsmatrizen auf Datei auf Datei gespeichert. attention_xxxx.npy , das einen Diktat der folgenden Einträge speichert:
src : Numpy -Array von Form [batch_size, src_seq_len] , wobei jede Zeile eine Abfolge von Token -IDs ist, die mit 1 ( EOS_ID ) endet und mit Nullen gepolstert werden.tgt : Numpy -Array von Form [batch_size, tgt_seq_len] , wobei jede Zeile eine Abfolge von Token -IDs ist, die mit 1 ( EOS_ID ) endet und mit Nullen gepolstert werden.src_src_attention : numpy array von form [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : Numpy Array of Shape [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : Numpy Array of Shape [batch_size, num_heads, tgt_seq_len, tgt_seq_len]Die Aufmerksamkeitsgewichte können durch Laufen angezeigt werden:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files wobei head eine Ganzzahl in [0, num_heads - 1] und index ist eine Ganzzahl in [0, batch_size - 1] .
Nachfolgend sind drei Sätze in englischer Sprache (Quellsprache) und ihre Übersetzungen in Deutsch (Zielsprache) aufgeführt.
Sätze in der Quelle Langauge eingeben
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
Übersetzte Sätze in der Zielsprache
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
Das Transformatormodell berechnet drei Arten von Aufmerksamkeiten:
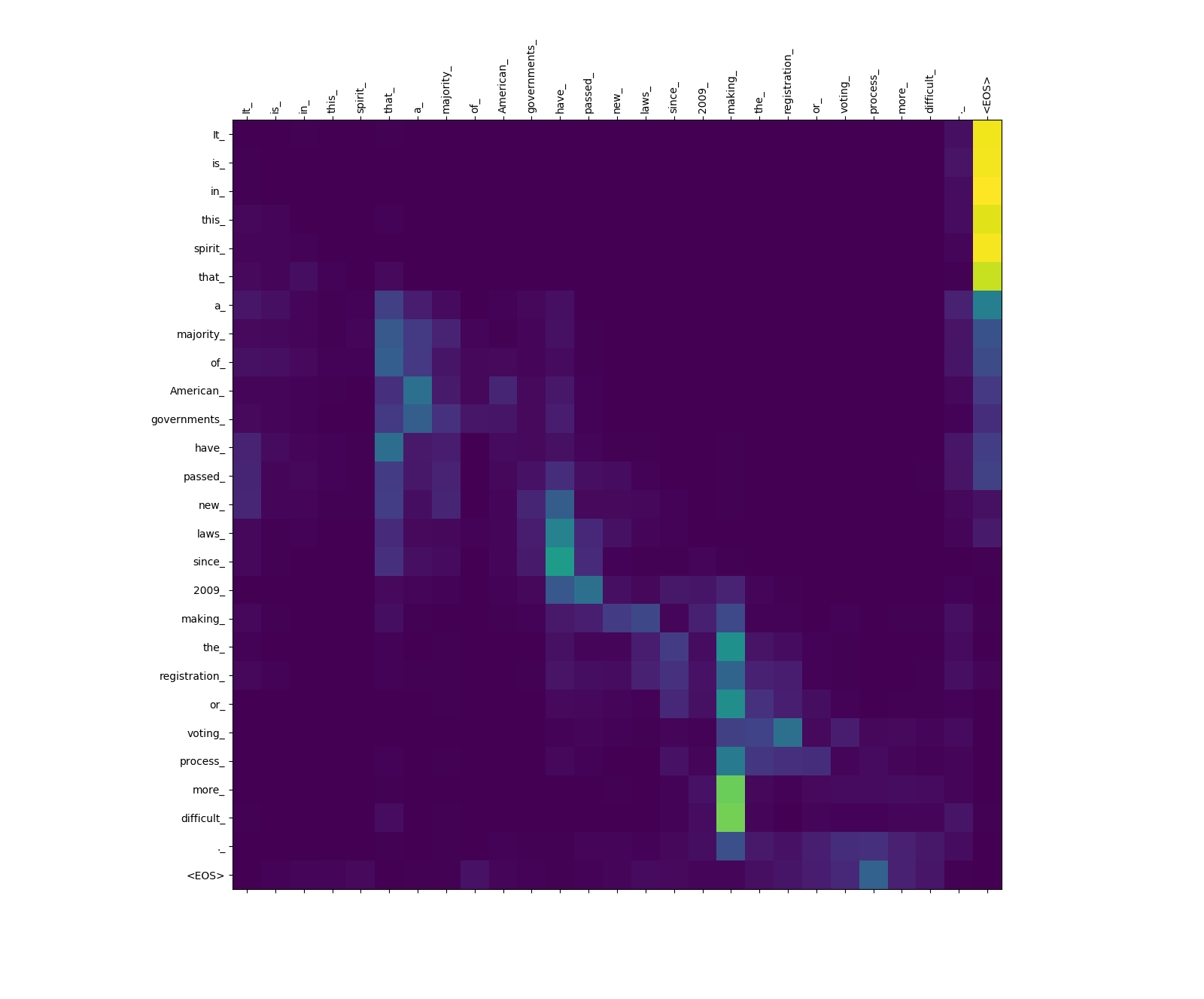
Aufmerksamkeitsgewichte der Quelle zu Source.
Beachten Sie das Aufmerksamkeitsgewicht von more_ und difficult_ bis zum making_ - Sie sind "auf der Aussicht" für das Verb "make", wenn Sie versuchen, den Ausdruck "Make ... Make ... schwieriger" zu vervollständigen.
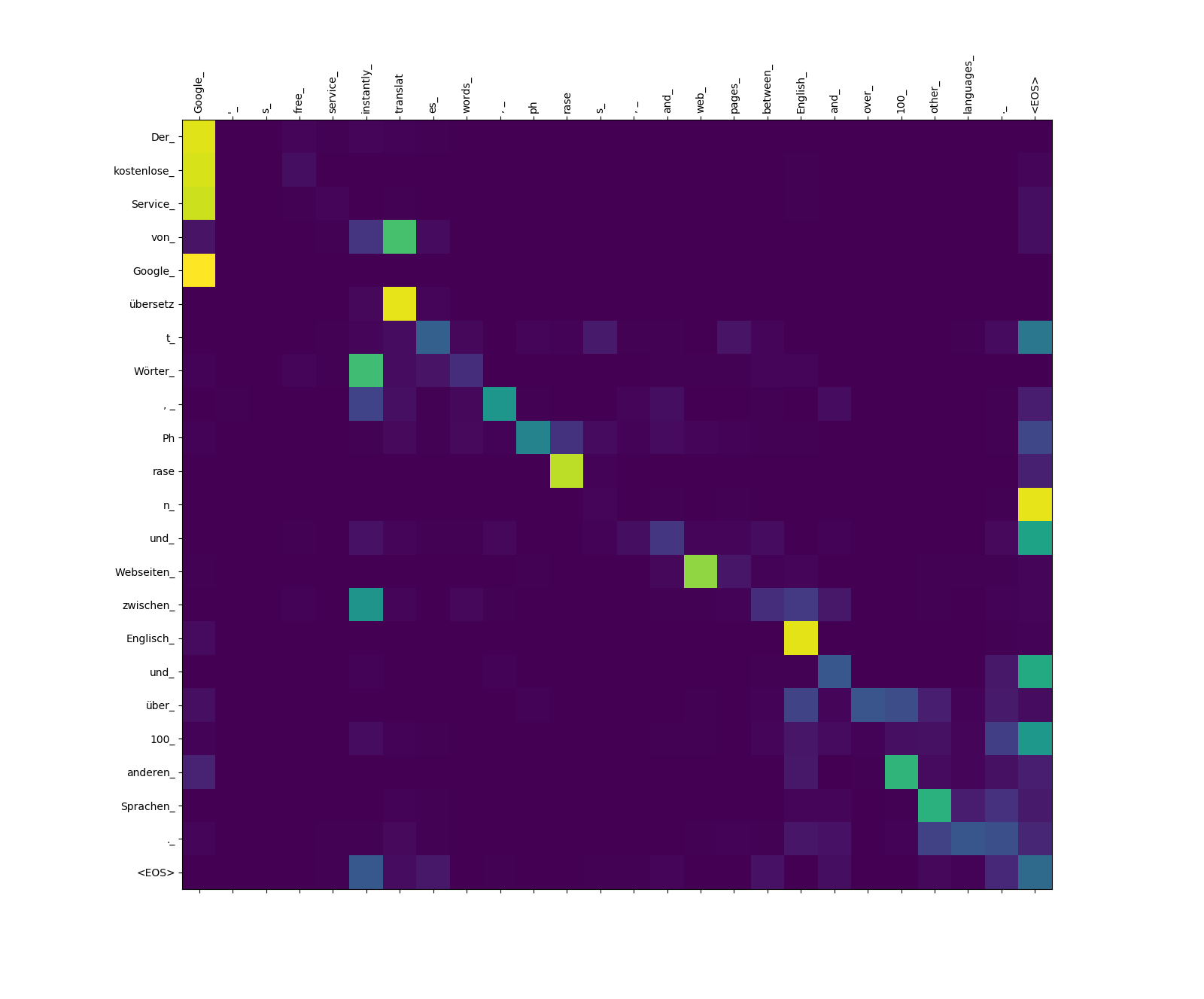
Aufmerksamkeitsgewichte von Target-to-Source.
Beachten Sie das Aufmerksamkeitsgewicht von übersetz (Ziel) in translat (Quelle) und von Webseiten (Ziel) bis web (Quelle) usw. Dies ist wahrscheinlich auf ihre Synonymität in Deutsch und Englisch zurückzuführen.
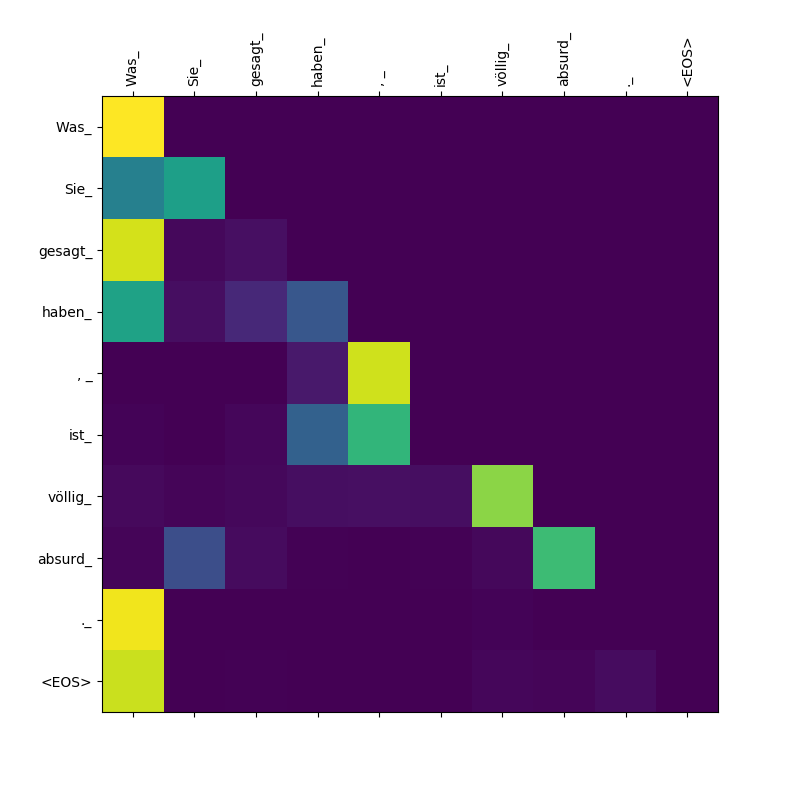
Aufmerksamkeitsgewichte von Target-to-Target.
Beachten Sie, dass die Aufmerksamkeit Sie_ von der sie geschenkt Was , Was , gesagt , haben_ - Als der Decoder diese Subtoken ausspuckt, muss sie sich über den Geltungsbereich der Klausel "bewusst" sein (was "was Sie Was Sie gesagt haben ").


