tf transformer
1.0.0
Il s'agit d'une implémentation TensorFlow 2.x du modèle de transformateur (l'attention est tout ce dont vous avez besoin) pour la traduction machine neurale (NMT).
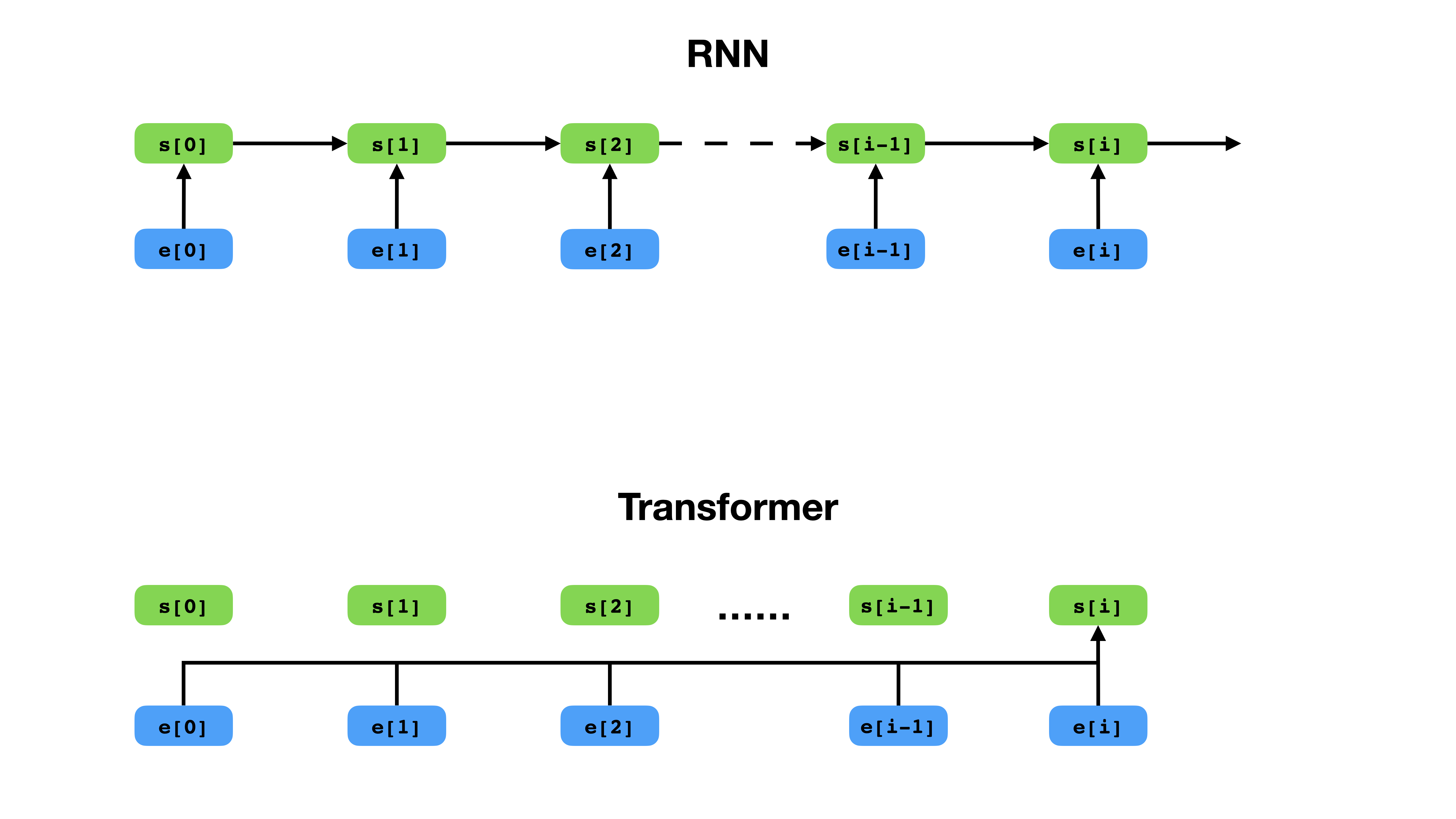
Le transformateur a une façon plus flexible de représenter le contexte par rapport à RNN.
Le transformateur est une architecture de réseau neuronale profonde pour la modélisation de séquences, qui est la tâche d'estimer la probabilité de jetons dans une séquence basée sur leur contexte textuel. Alors que les réseaux de neurones récurrents effondrent les intérêts de toute l'histoire des jetons de contexte dans un seul vecteur, Transformer a accès au vecteur d'incorporation de chaque jeton individuel, peu importe jusqu'où le contexte s'étend. Cela le rend bien adapté à la modélisation des relations de dépendance à longue distance, ce qui est essentiel aux récentes percées dans les méthodes d'apprentissage de la représentation de texte telles que Bert et GPT-2.
Au cœur du transformateur se trouve le mécanisme d'auto-agencement , où l'objectif est de calculer une représentation contextualisée de chaque jeton dans une séquence en les laissant «faire attention» les uns aux autres. Compte tenu des représentations de vecteurs initiales e[i] pour toutes les positions i , il applique d'abord les projections linéaires pour obtenir des vecteurs q[i] , k[i] , v[i] , où k 's et v jouent le rôle de la clé et de la valeur d'une base de connaissances sur le contenu de séquence, qui doit être interrogé par q[i] pour déterminer quels jens sont les plus similaires au toxicomane de l'index i Le résultat de la requête est simplement les scores de similitude entre q[i] et k (généralement des produits de points), qui sont utilisés comme poids pour calculer une moyenne pondérée des v comme nouvelle représentation de e[i] . Notez que q , k et v sont dérivés de la même séquence, ce qui signifie que la séquence s'interroge effectivement (d'où le nom d'auto-attention).
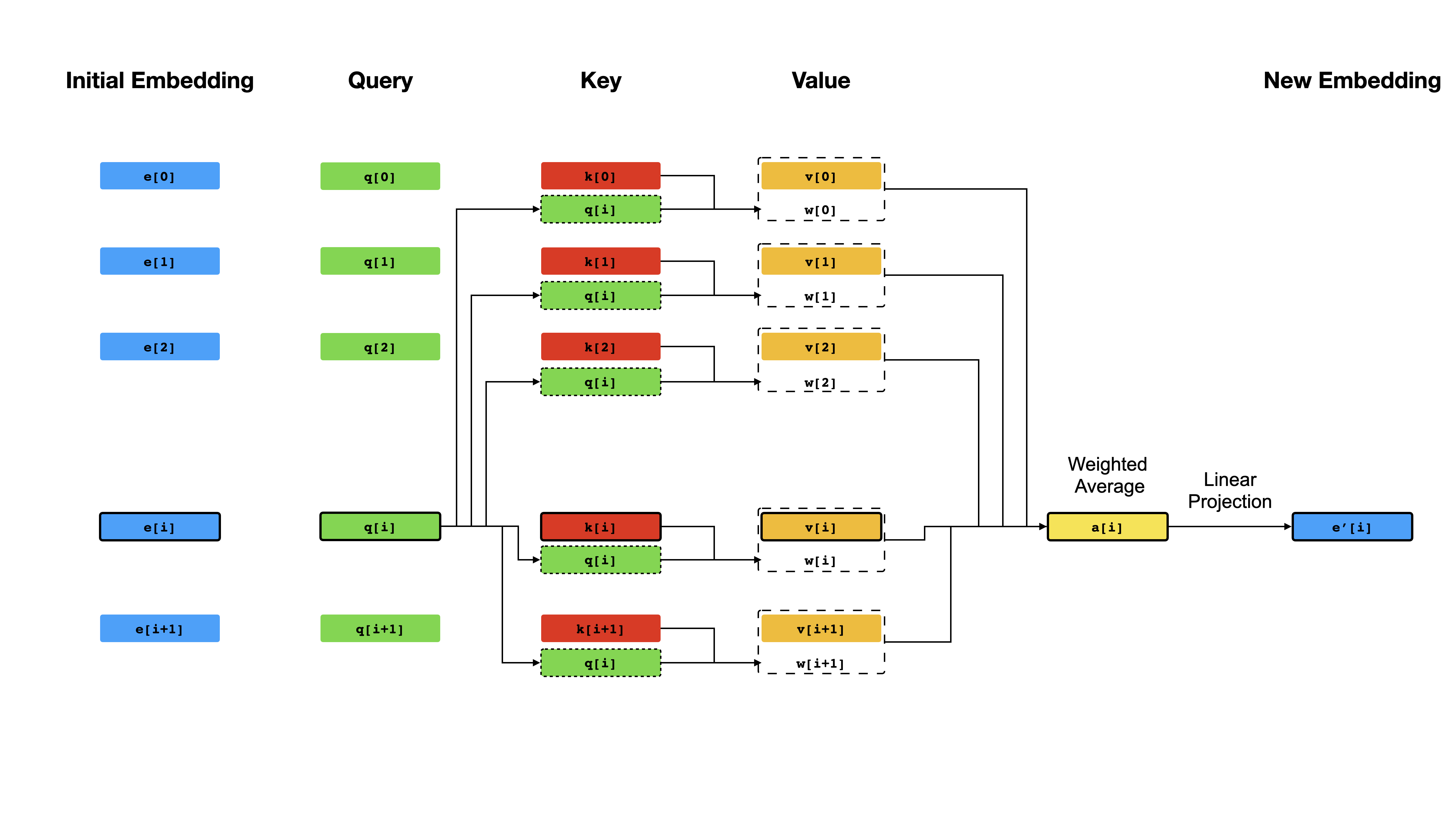
Mécanisme d'auto-agencement.
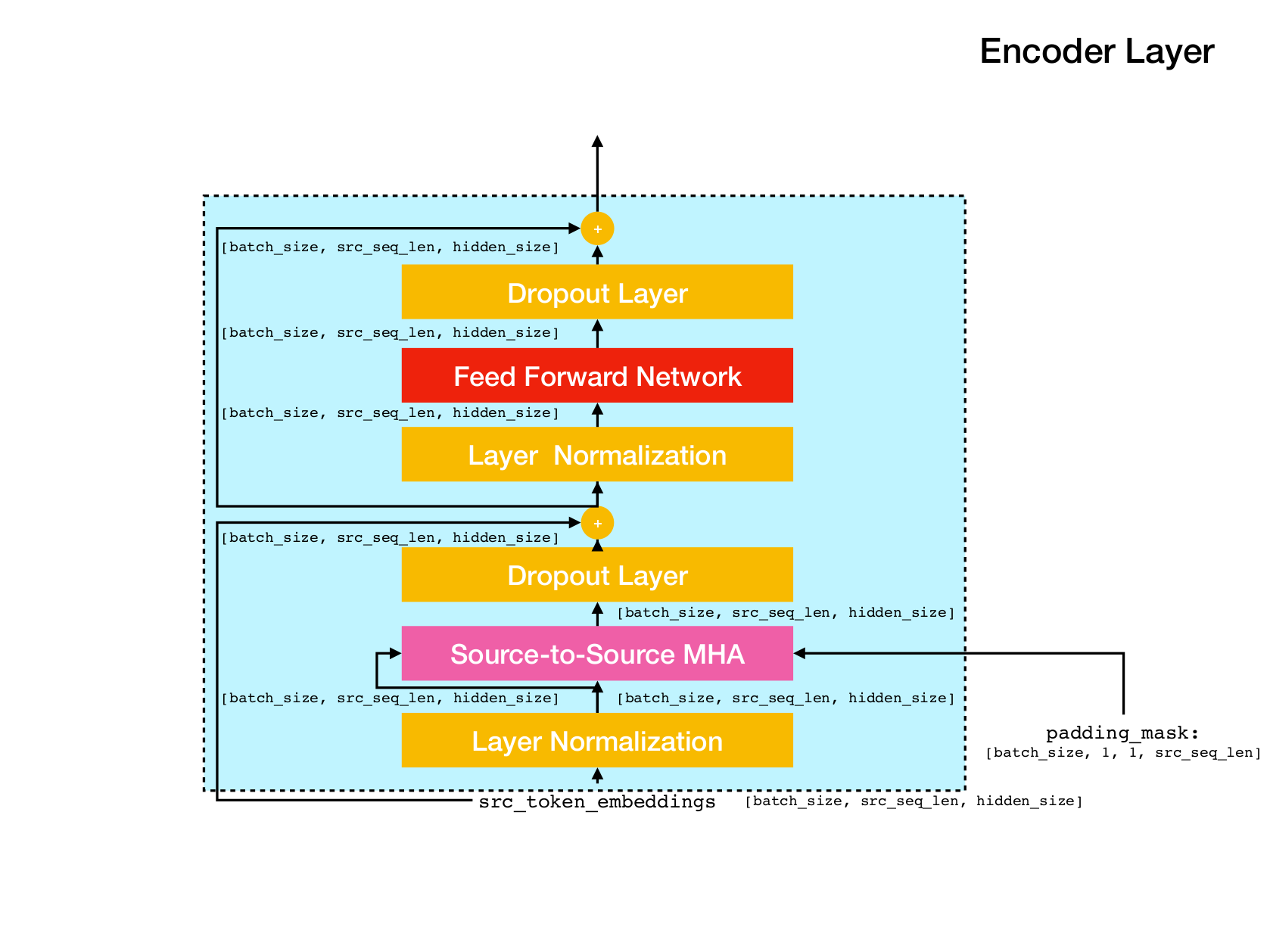
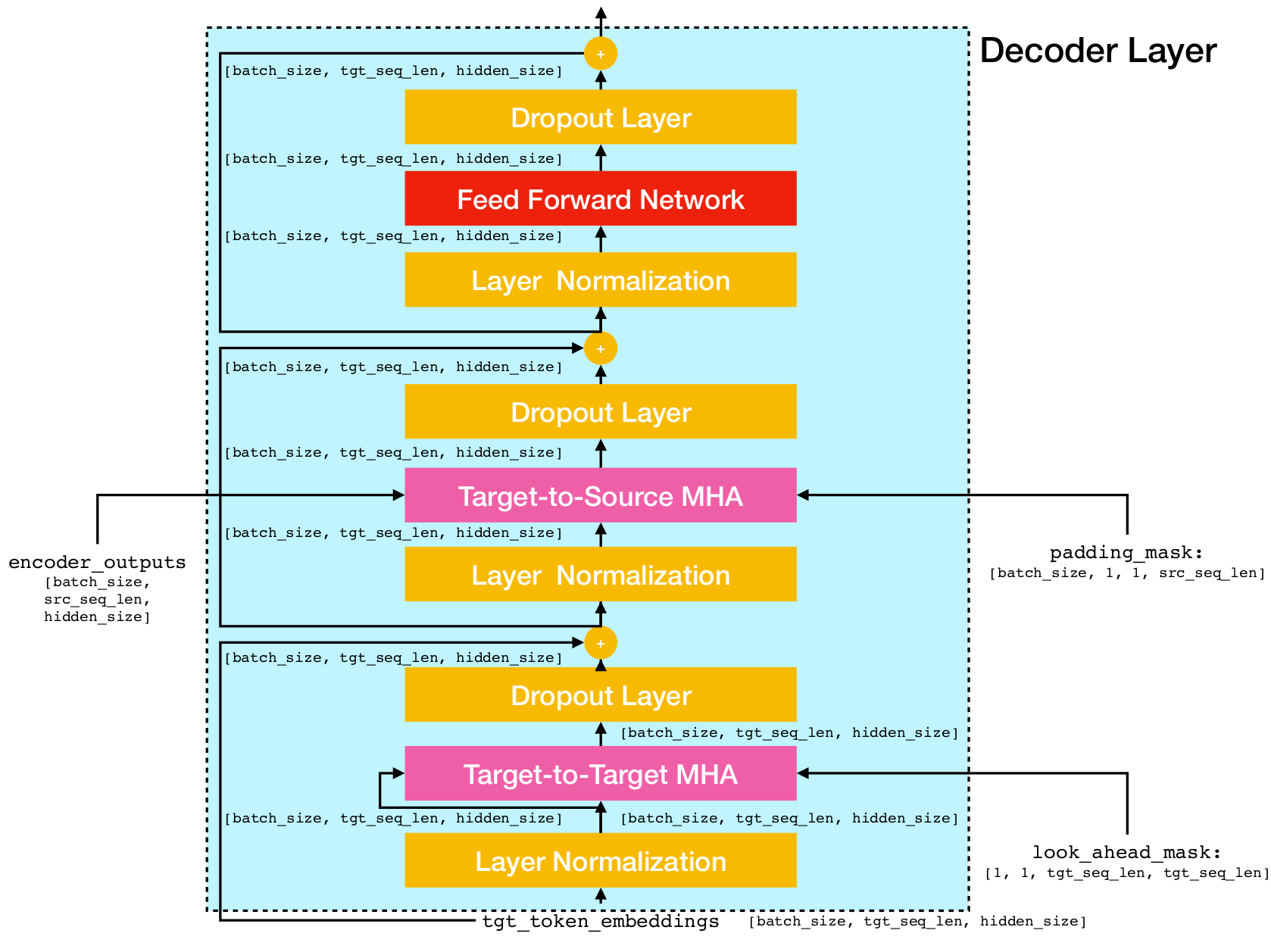
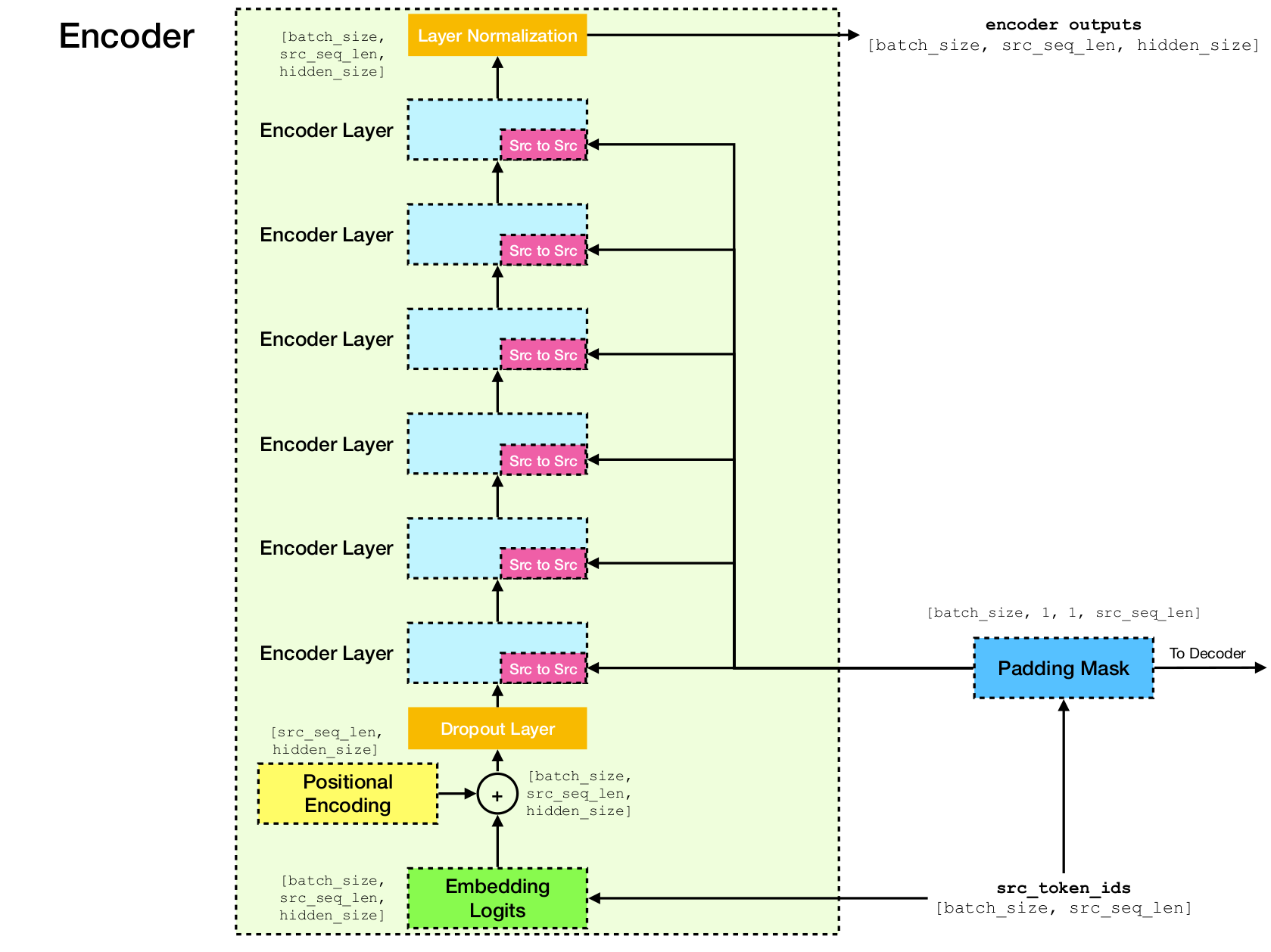
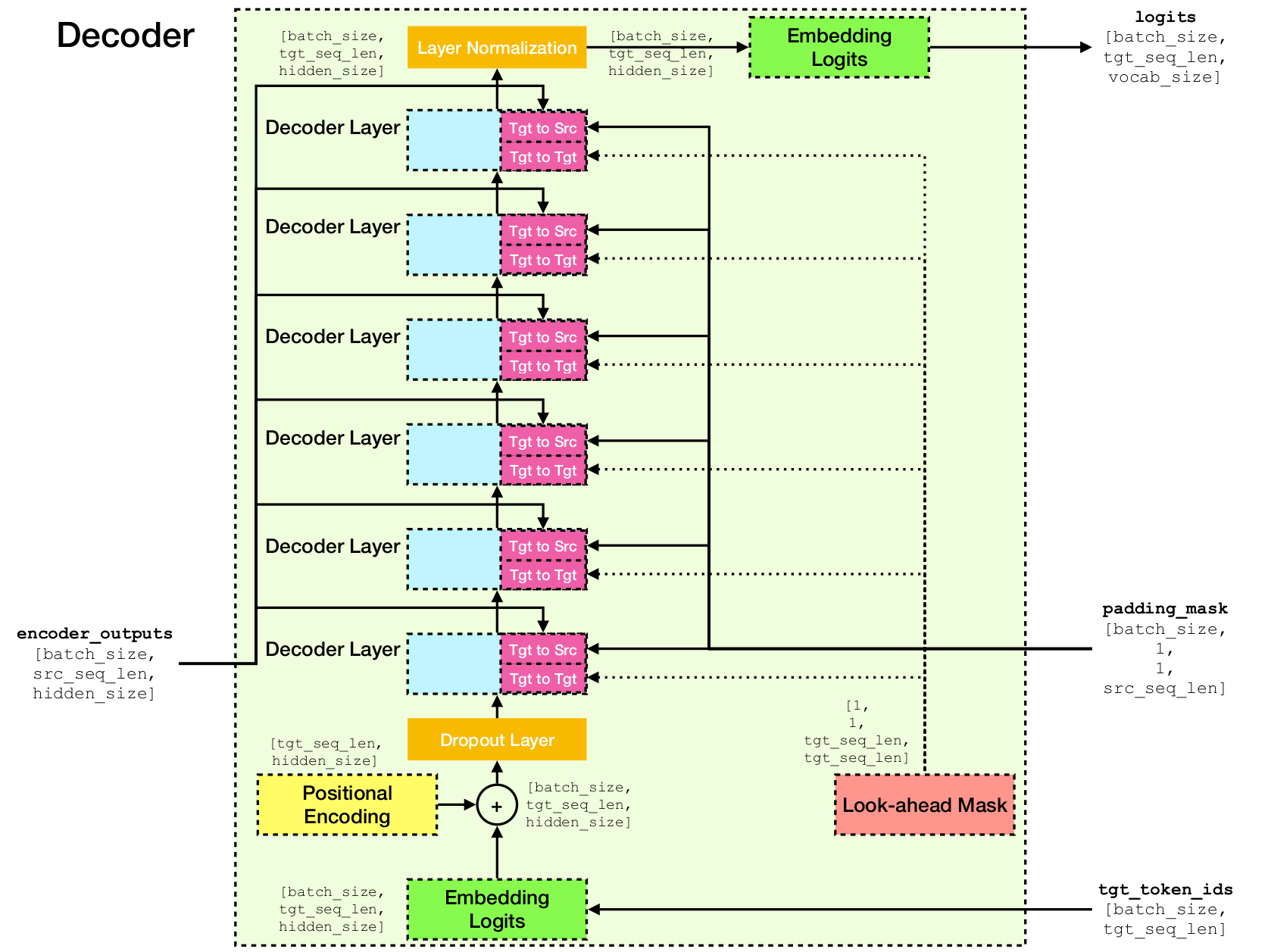
Architecture du réseau transformateur.
Cette implémentation est basée sur TensorFlow 2.x et Python3. De plus, NLTK est nécessaire pour calculer le score BLEU pour l'évaluation.
Vous pouvez cloner ce référentiel en exécutant
git clone [email protected]:chao-ji/tf-transformer.gitPuis clonez et mettez à jour le sous-module en fonctionnant
cd tf-transformer
git submodule update --init --recursiveLe corpus de formation doit être sous la forme d'une liste de fichiers texte dans la langue source, associés à une liste de fichiers texte dans le langage cible, où les lignes (ie phrases) dans les fichiers texte de la langue source ont une correspondance individuelle avec
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
Vous devez d'abord convertir les fichiers texte bruts en fichiers tfrecord en exécutant
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab Remarque: Ce processus consiste à «apprendre» un vocabulaire de jetons de sous-mots du corpus de formation, qui est enregistré dans les fichiers vocab.subtokens et vocab.alphabet . Le vocabulaire sera utilisé plus tard pour coder la chaîne de texte brute en ID de jeton de sous-mots, ou les décodera à la chaîne de texte brute.
Pour des informations d'utilisation détaillées, exécutez
python commons/create_tfrecord_machine_translation.py --helpPour les exemples de données, reportez-vous à data_sources.txt
Pour entraîner un modèle, courez
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir est le répertoire stockant les fichiers tfrecord, vocab_path est le chemin vers le nom de base model_dir vocabulaire Files vocab.subtokens et vocab.alphabet (ie Path to vocab ) généré par exécution de create_tfrecord_machine_translation.py point de contrôle).
Pour des informations d'utilisation détaillées, exécutez
python run_trainer.py --helpL'évaluation consiste à traduire une séquence source dans la séquence cible et à calculer le score BLEU entre la séquence cible prédite et le sol.
Pour évaluer un modèle pré-entraîné, exécutez
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename et target_text_filename sont les chemins des fichiers texte détenant des séquences source et cible, respectivement.
Remarque L'argument de la ligne de commande target_text_filename est facultatif - s'il est exclu, l'évaluateur s'exécutera en mode d'inférence , où seules les traductions seront écrites dans le fichier de sortie.
Pour des informations d'utilisation plus détaillées, exécutez
python run_evaluator.py --help Notez que le mécanisme d'attention calcule des similitudes de jeton à token qui peuvent être visualisées pour comprendre comment l'attention est distribuée sur différents jetons. Lorsque vous exécutez python run_evaluator.py les matrices de poids d'attention seront enregistrées pour fichier attention_xxxx.npy , qui stocke un dict des entrées suivantes:
src : tableau de forme Numpy [batch_size, src_seq_len] , où chaque ligne est une séquence d'ID de jeton qui se termine par 1 ( EOS_ID ) et rembourrée avec des zéros.tgt : tableau de forme Numpy [batch_size, tgt_seq_len] , où chaque ligne est une séquence d'ID de jeton qui se termine avec 1 ( EOS_ID ) et rembourrée avec des zéros.src_src_attention : Array Numpy de forme [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : Array Numpy de forme [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : Array Numpy de forme [batch_size, num_heads, tgt_seq_len, tgt_seq_len]Les poids d'attention peuvent être affichés en fonctionnant:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files où head est un entier dans [0, num_heads - 1] et index est un entier dans [0, batch_size - 1] .
Vous trouverez ci-dessous trois phrases en anglais (langue source) et leurs traductions en allemand (langue cible).
Phrases d'entrée dans Source Langauge
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
Phrases traduites en langue cible
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
Le modèle de transformateur calcule trois types d'attentions:
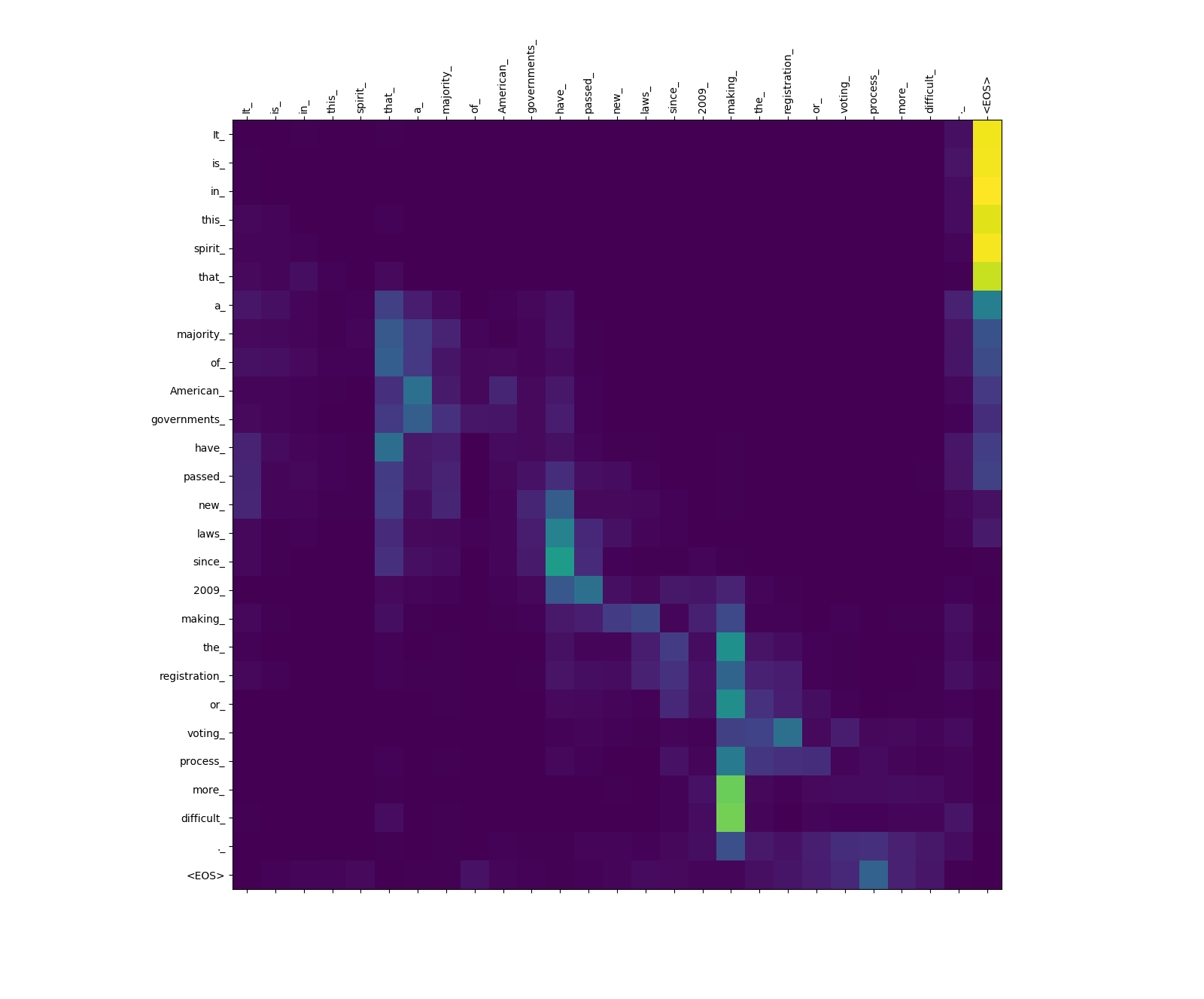
Poids d'attention de source à source.
Remarquez le poids d'attention de more_ et difficult_ à making_ - ils sont "à l'affût" pour le verbe "faire" lorsque vous essayez de terminer la phrase "faire ... plus difficile".
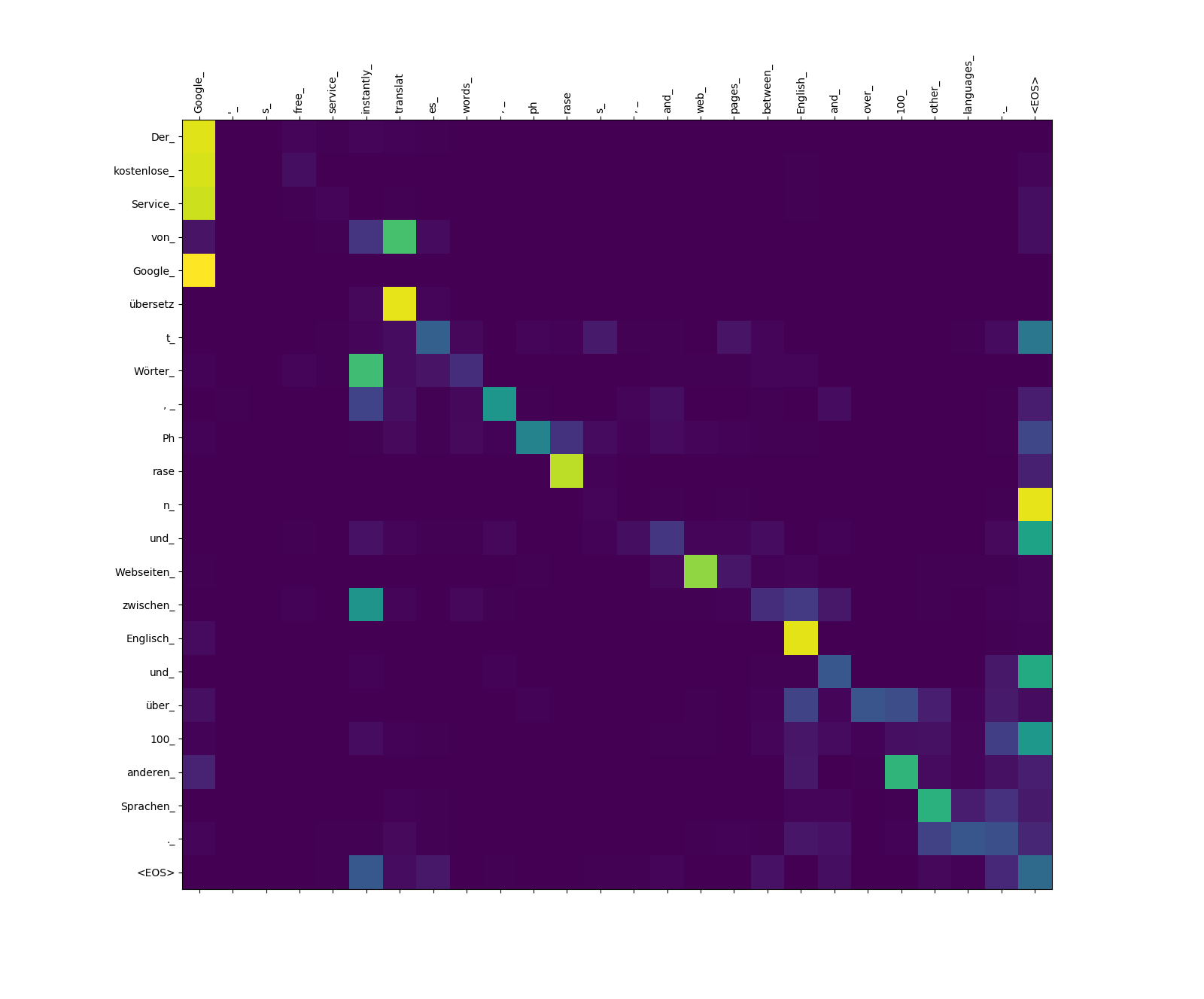
Poids d'attention cible à source.
Remarquez le poids d'attention de übersetz (cible) pour translat (source), et de Webseiten (cible) vers web (source), etc. Cela est probablement dû à leur synonymat en allemand et en anglais.
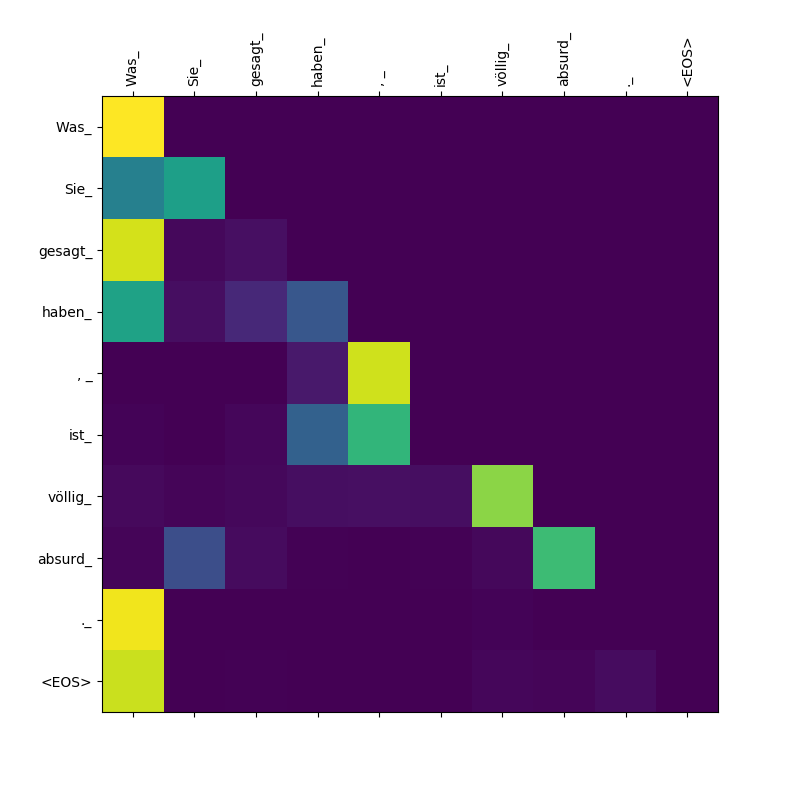
Poids d'attention cible à cibler.
Remarquez que l'attention accordée Was Was Sie_ , gesagt , haben_ - Comme le décodeur crache ces sous-tokens, il doit "être conscient" de la portée de la clause Was Sie gesagt haben (ce qui signifie "ce que vous avez dit").


