tf transformer
1.0.0
Это реализация TensorFlow 2.x модели трансформатора (внимание - это все, что вам нужно) для перевода нейронной машины (NMT).
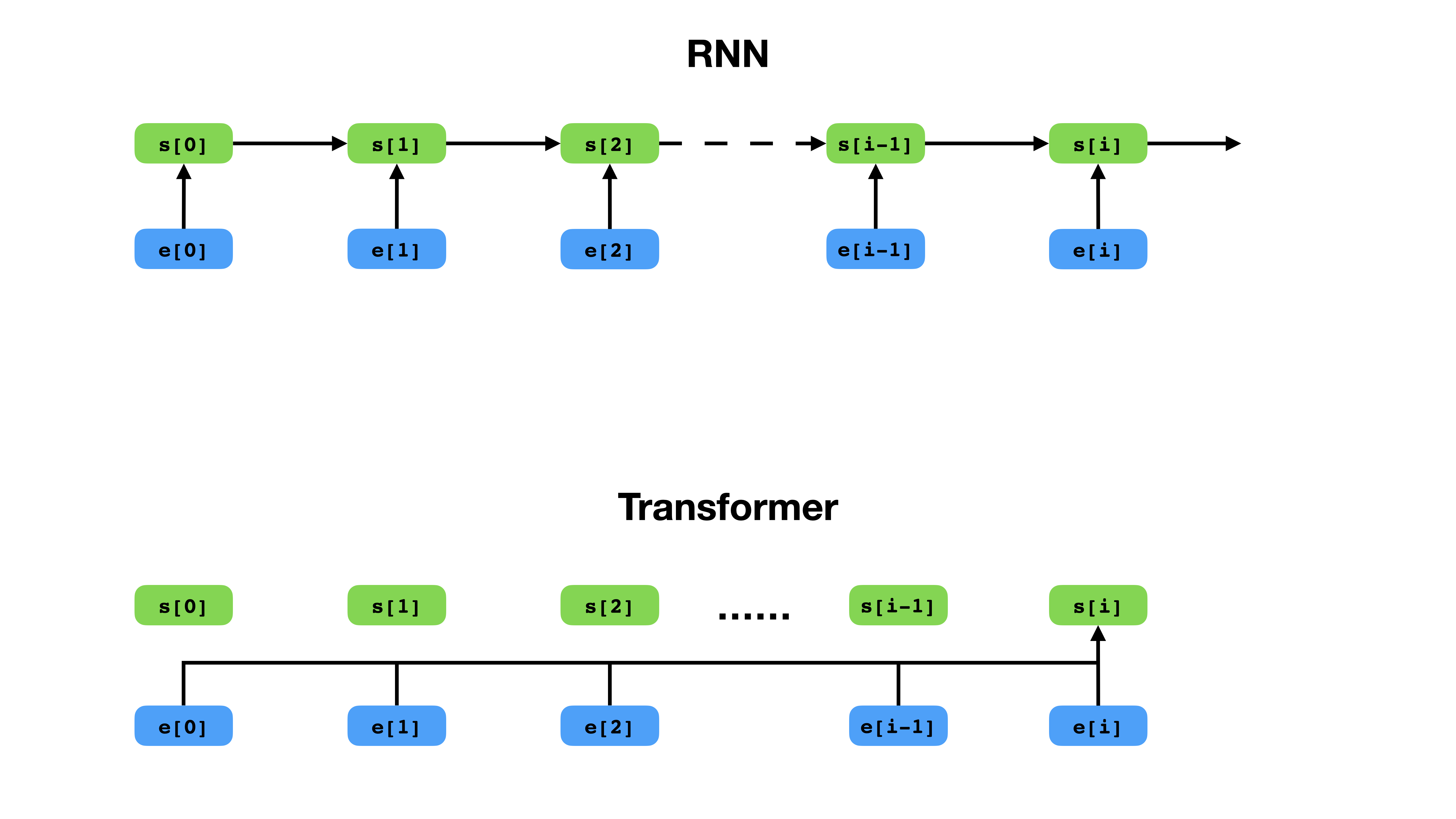
Трансформатор имеет более гибкий способ представления контекста по сравнению с RNN.
Transformer является глубокой архитектурой нейронной сети для моделирования последовательностей, которая является задачей оценки вероятности токенов в последовательности, основанной на их текстовом контексте. В то время как повторяющиеся нейронные сети переполняют встраивание всей истории контекста токенов в один вектор, трансформатор имеет доступ к вектору встраивания каждого отдельного токена, независимо от того, насколько далеко охватывает контекст. Это делает его хорошо подходящим для моделирования отношений с зависимостью на расстоянии, что является ключом к недавним прорывам в методах обучения представлению текста, таких как BERT и GPT-2.
В основе трансформатора лежит механизм самоуправления , где цель состоит в том, чтобы вычислить контекстуализированное представление каждого токена в последовательности, позволяя им «обращать внимание» друг другу. Учитывая первоначальные векторные представления e[i] для всех позиций i , сначала применяется линейные проекции для получения векторов q[i] , k[i] , v[i] , где k 'S и v играют роль ключа и ценность базы знаний о содержании последовательности, которые должны запрашивать q[i] чтобы определить, какие токены наиболее похожи на ток -адрес, который должен запрашивать Q [i], чтобы определить, какие токены являются наиболее похожими на то жерок в i . Результатом запроса является просто оценки сходства между q[i] и k '(обычно точечными продуктами), которые используются в качестве веса для вычисления средневзвешенного v -n в качестве нового представления e[i] . Обратите внимание, что q , k и v получены из одной и той же последовательности, что означает, что последовательность эффективно запрашивает себя (отсюда и название самопринятое).
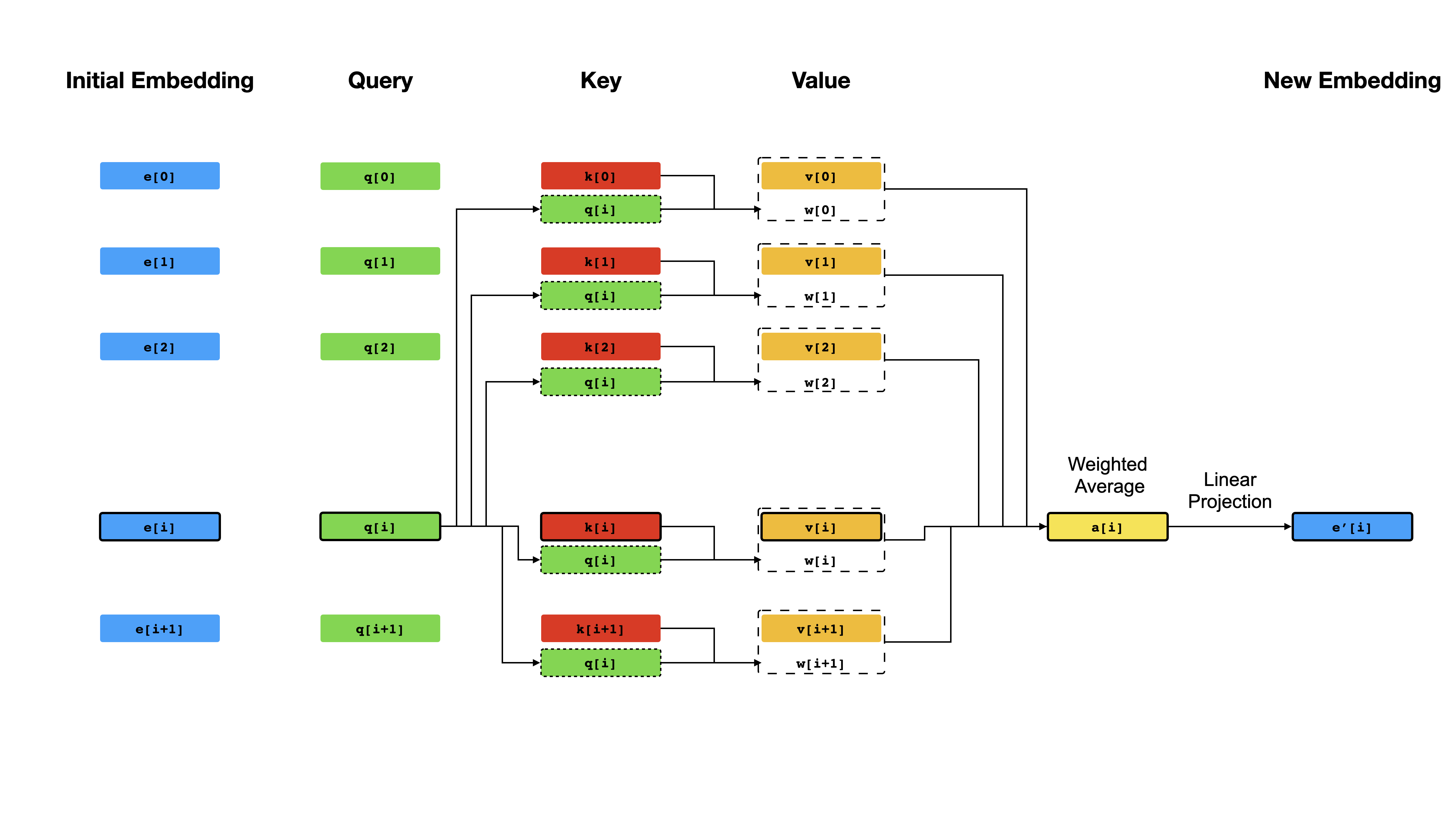
Самосматривающий механизм.
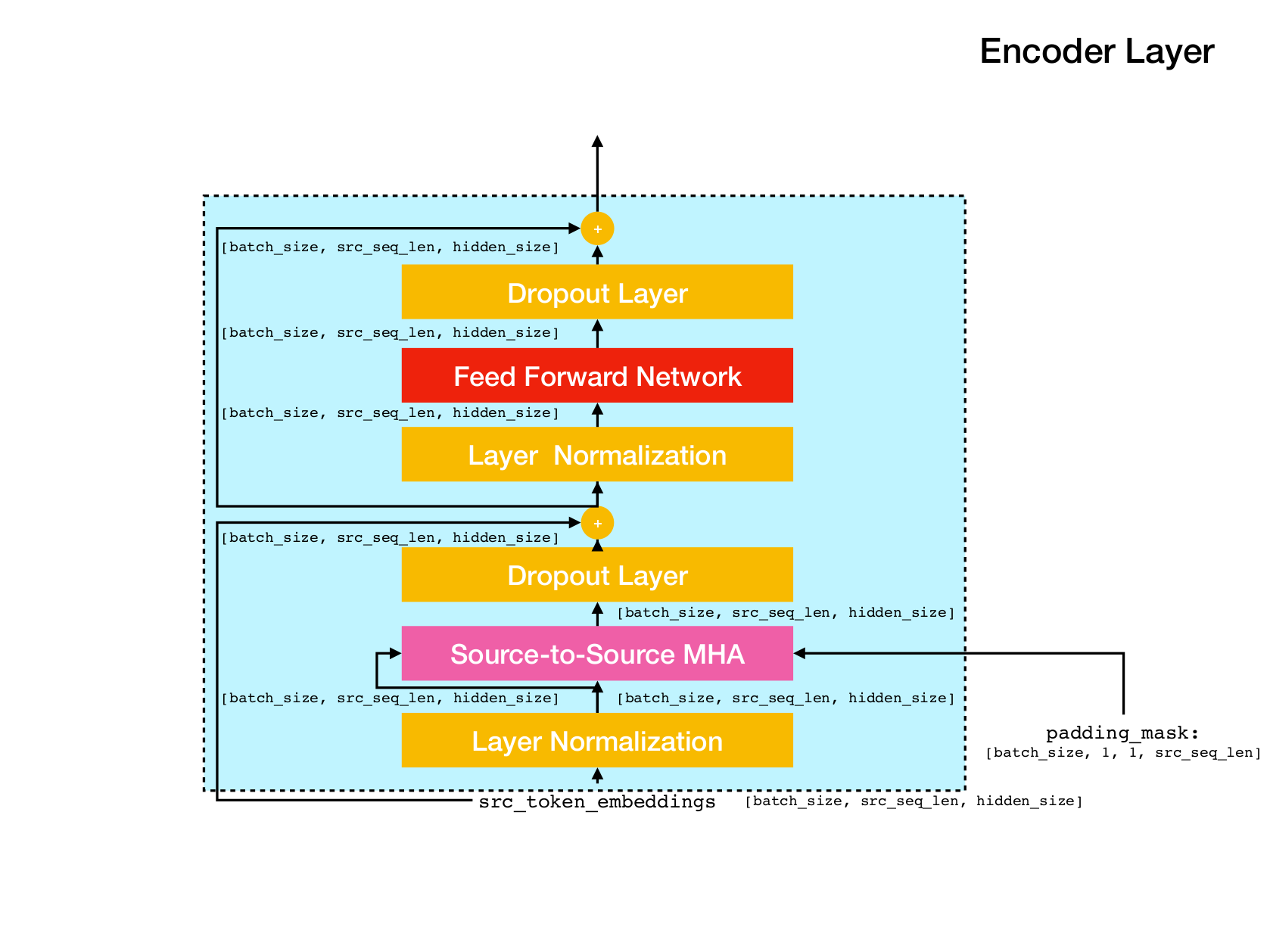
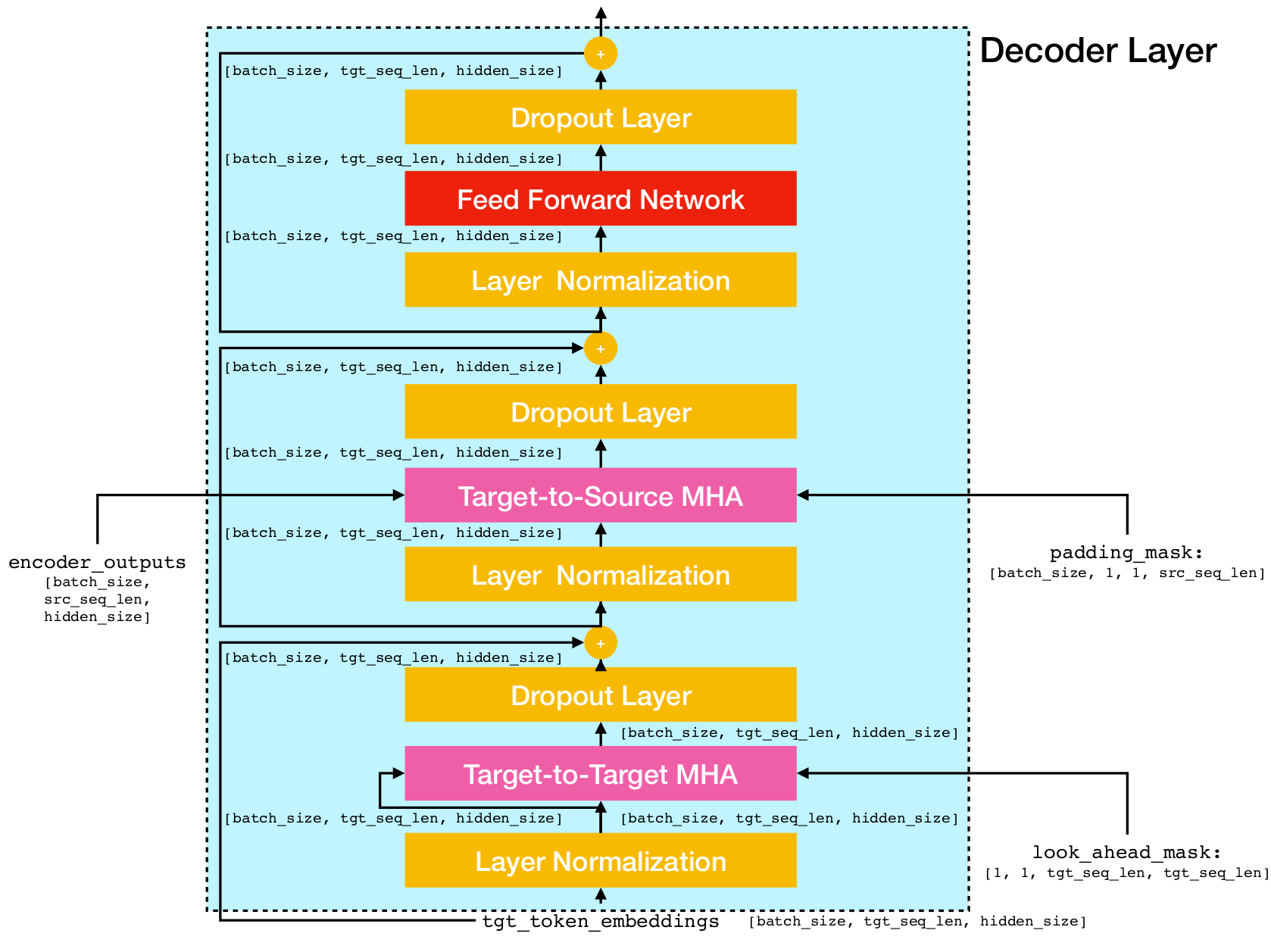
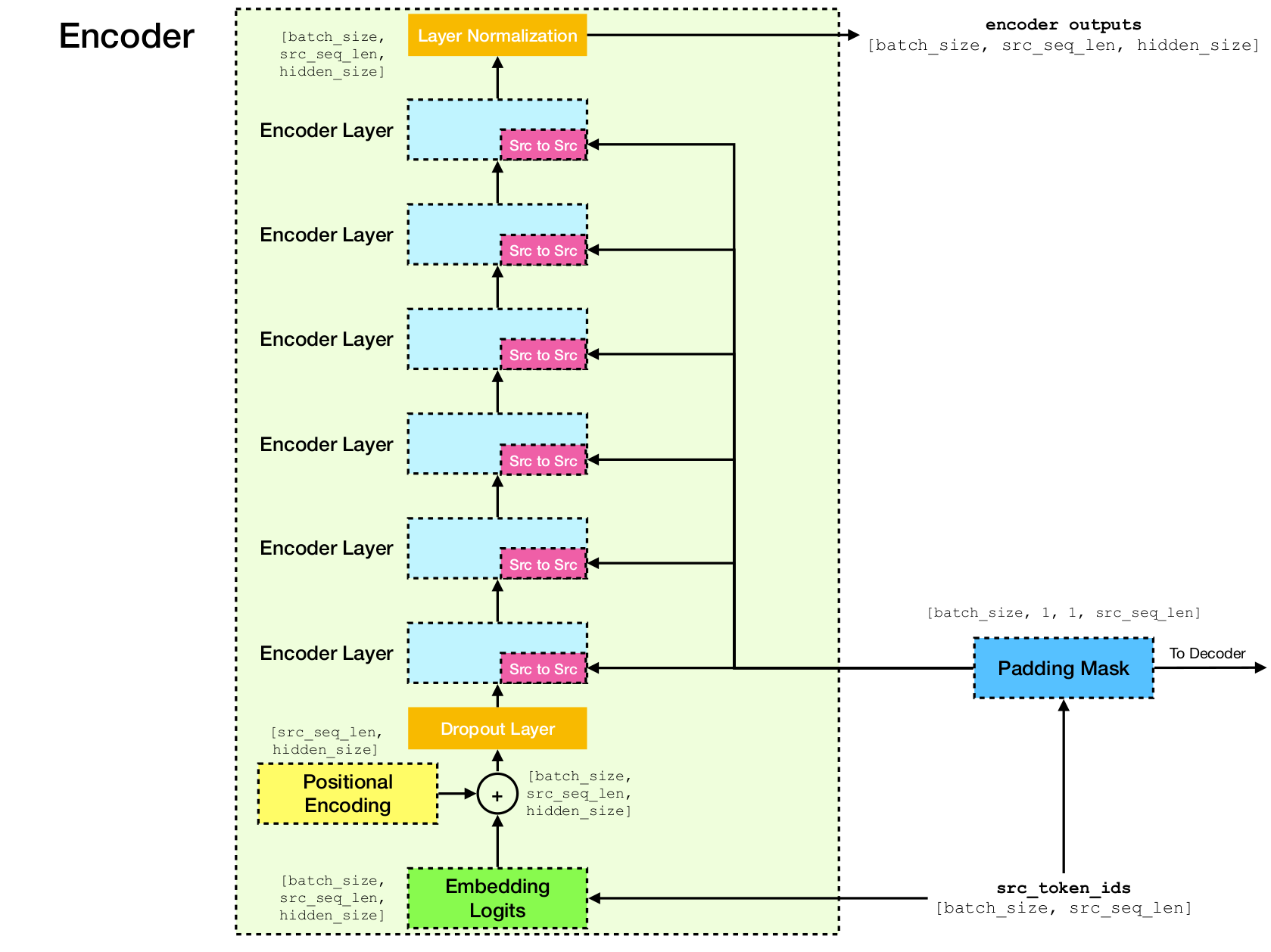
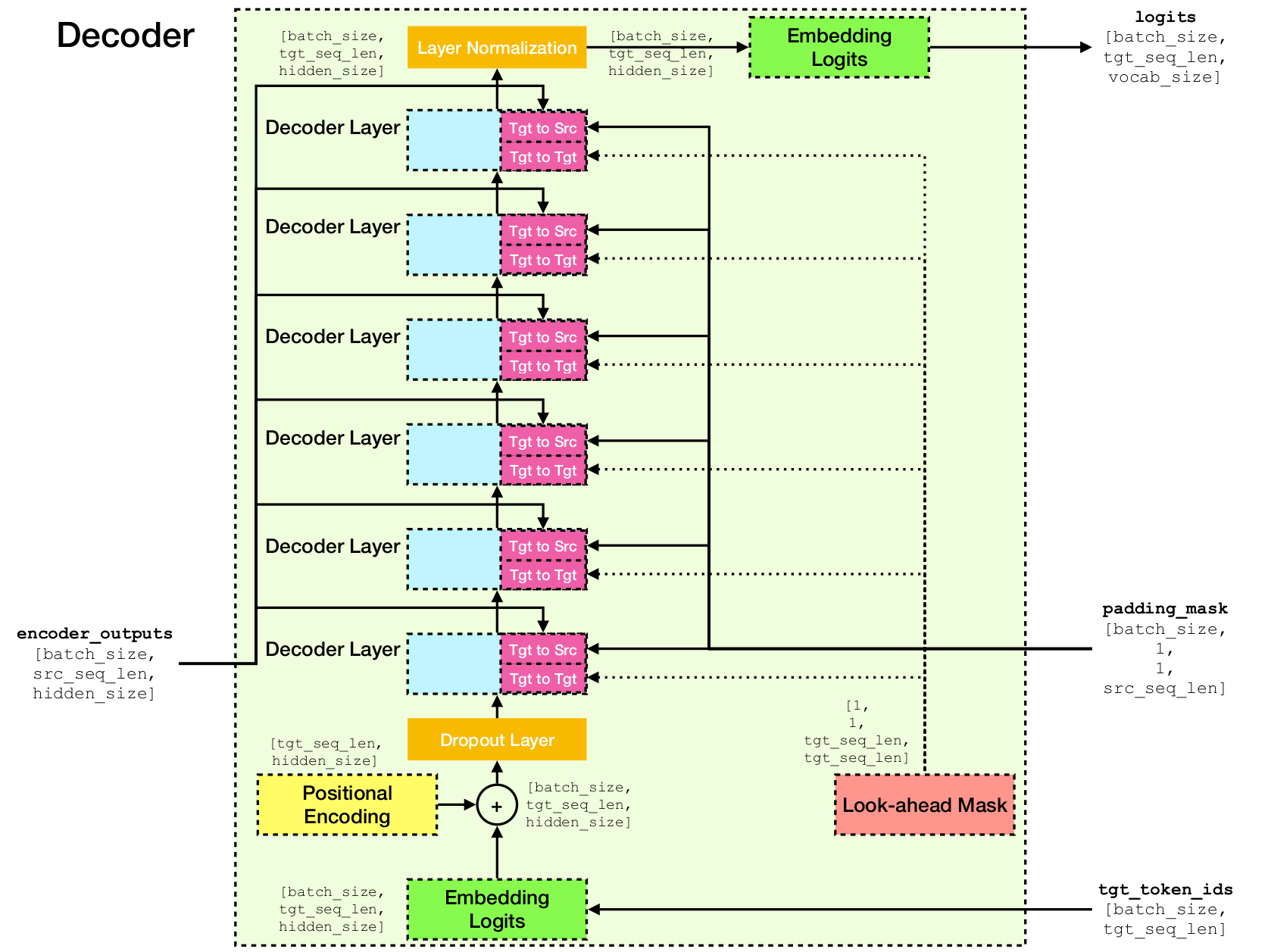
Архитектура сети трансформатора.
Эта реализация основана на Tensorflow 2.x и Python3. Кроме того, NLTK необходим для вычисления баллов BLEU для оценки.
Вы можете клонировать этот репозиторий, запустив
git clone [email protected]:chao-ji/tf-transformer.gitЗатем клонируйте и обновите подмодуль, запустив
cd tf-transformer
git submodule update --init --recursiveУчебный корпус должен находиться в форме списка текстовых файлов на исходном языке, в сочетании со списком текстовых файлов на целевом языке, где строки (т.е. предложения) в текстовых файлах исходного языка имеют один к одному соответствию строкам в целевых языках текстовые файлы.
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
Сначала вам нужно преобразовать необработанные текстовые файлы в файлы tfrecord, запустив
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab Примечание. Этот процесс включает в себя «изучение» словаря токенов подвесков из учебного корпуса, который сохраняется в файлах vocab.subtokens и vocab.alphabet . Словарь позже будет использоваться для кодирования необработанной текстовой строки в идентификаторы токенов подвода или декодировать их обратно в необработанную текстовую строку.
Для получения подробной информации об использовании, запустите
python commons/create_tfrecord_machine_translation.py --helpДля примера данных см. Data_sources.txt
Чтобы тренировать модель, беги
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir model_dir это каталог create_tfrecord_machine_translation.py хранящий файлы TFRECORD, vocab_path - это путь к базовому обзору словарных файлов vocab.subtokens и vocab.alphabet (т.е. Путь к vocab Контрольная точка).
Для получения подробной информации об использовании, запустите
python run_trainer.py --helpОценка включает в себя перевод исходной последовательности в целевую последовательность и вычисление показателя Bleu между предсказанной и целевой последовательности Langletruth.
Чтобы оценить предварительную модель, запустите
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename и target_text_filename - это пути к текстовым файлам, содержащим исходные и целевые последовательности соответственно.
Обратите внимание, что аргумент командной строки target_text_filename является необязательным - если оставлено, оценщик будет работать в режиме вывода , где только переводы будут записаны в выходной файл.
Для получения более подробной информации об использовании, запустите
python run_evaluator.py --help Обратите внимание, что механизм внимания вычисляет сходства токена, которые можно визуализировать, чтобы понять, как внимание распределяется по разным токенам. Когда вы запускаете python run_evaluator.py матрицы веса внимания будут сохранены для файла attention_xxxx.npy , в котором хранится дикта следующих записей:
src : numpy массив формы [batch_size, src_seq_len] , где каждая строка представляет собой последовательность идентификаторов токена, которая заканчивается 1 ( EOS_ID ) и прополнена нулями.tgt : numpy массив формы [batch_size, tgt_seq_len] , где каждая строка представляет собой последовательность идентификаторов токена, которая заканчивается 1 ( EOS_ID ) и сочетается с нулями.src_src_attention : Numpy Array Shape [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : Numpy Array формы [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : Numpy Array Shape [batch_size, num_heads, tgt_seq_len, tgt_seq_len]Веса внимания можно отобразить при запуске:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files где head является целым числом в [0, num_heads - 1] , а index является целым числом в [0, batch_size - 1] .
Ниже показаны три предложения на английском языке (исходный язык) и их переводы на немецком языке (целевой язык).
Входные предложения в источнике Langauge
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
Переведенные предложения на целевом языке
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
Модель трансформатора вычисляет три типа внимания:
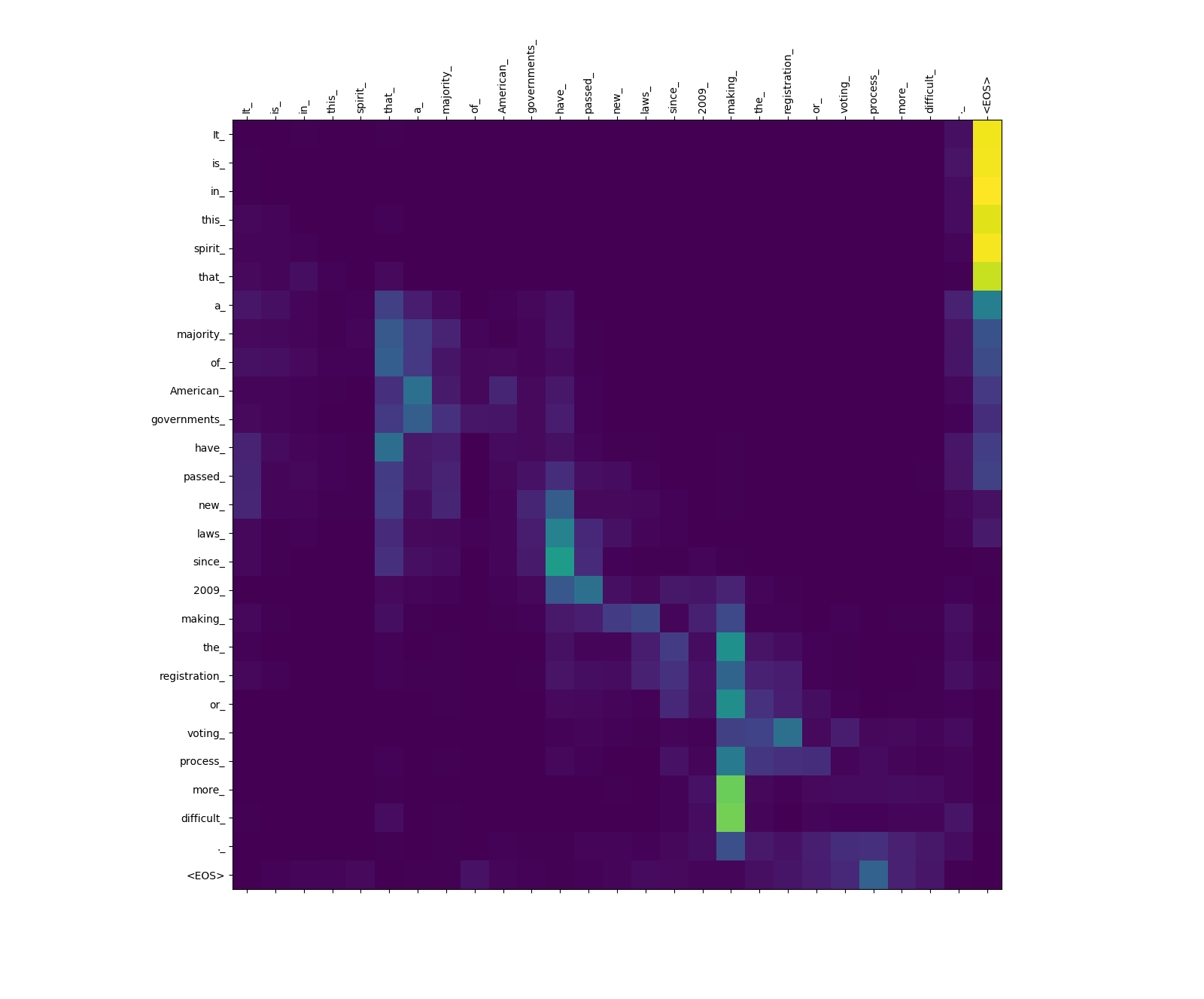
Веса внимания источника.
Обратите внимание на вес внимания от more_ и difficult_ до making_ - они «на смотровой площадке» для глагола «Сделайте» при попытке завершить фразу «Сделать ... более трудным».
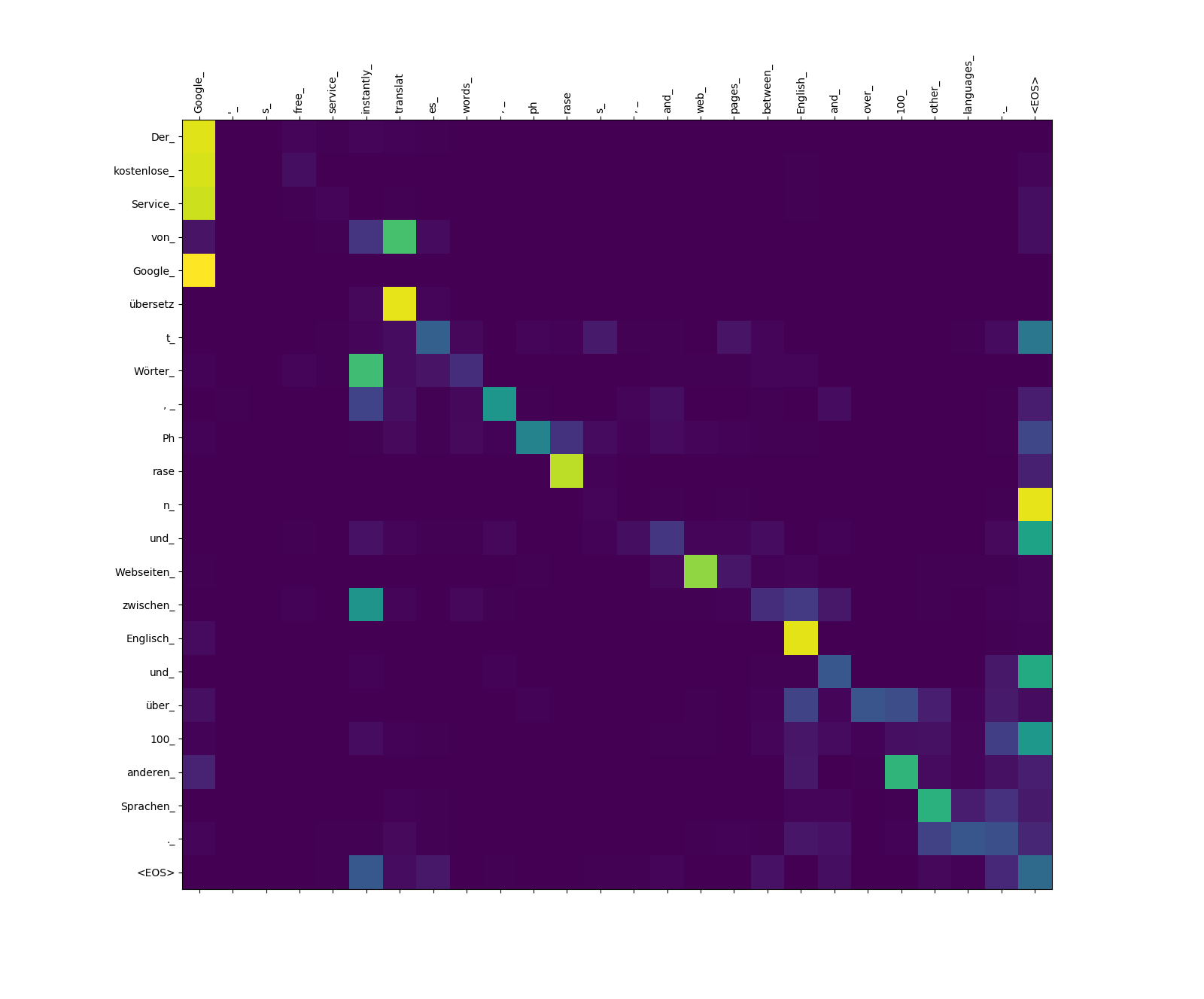
Веса внимания к источнику.
Обратите внимание на вес внимания от übersetz (target) в translat (источник) и от Webseiten (Target) в web (источник) и т. Д. Это, вероятно, связано с их синонимией на немецком и английском языке.
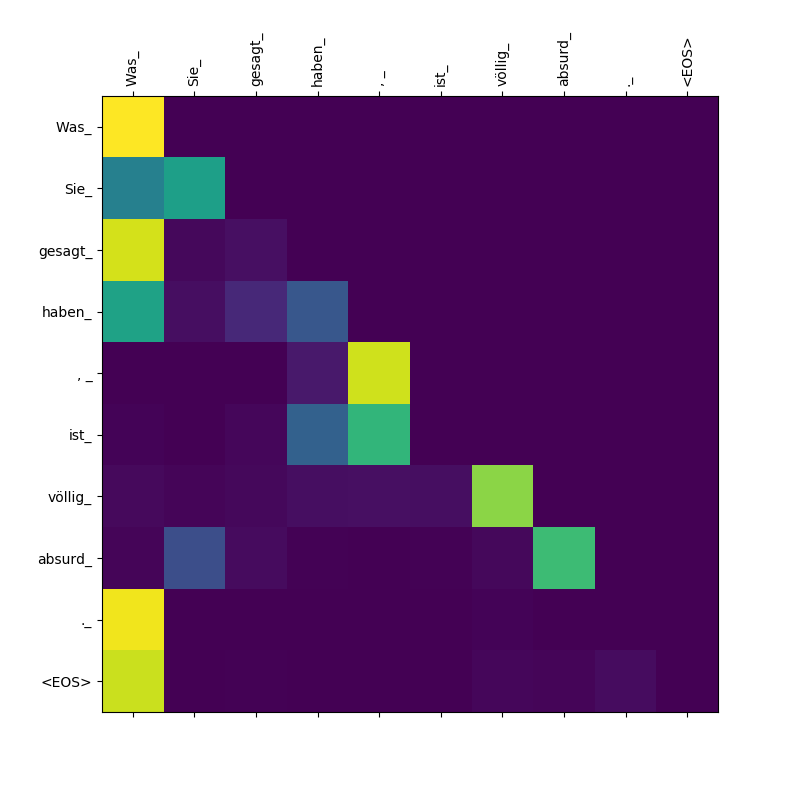
Целевые к целевому вниманию веса.
Обратите внимание, что внимание Was Was , Sie_ , gesagt , haben_ - Поскольку декодер выплевывает эти подтокины, он должен «знать» о объеме пункта Was Sie gesagt haben (что означает «то, что вы сказали»).


