tf transformer
1.0.0
هذا هو تنفيذ TensorFlow 2.x لنموذج المحولات (الاهتمام هو كل ما تحتاجه) للترجمة الآلية العصبية (NMT).
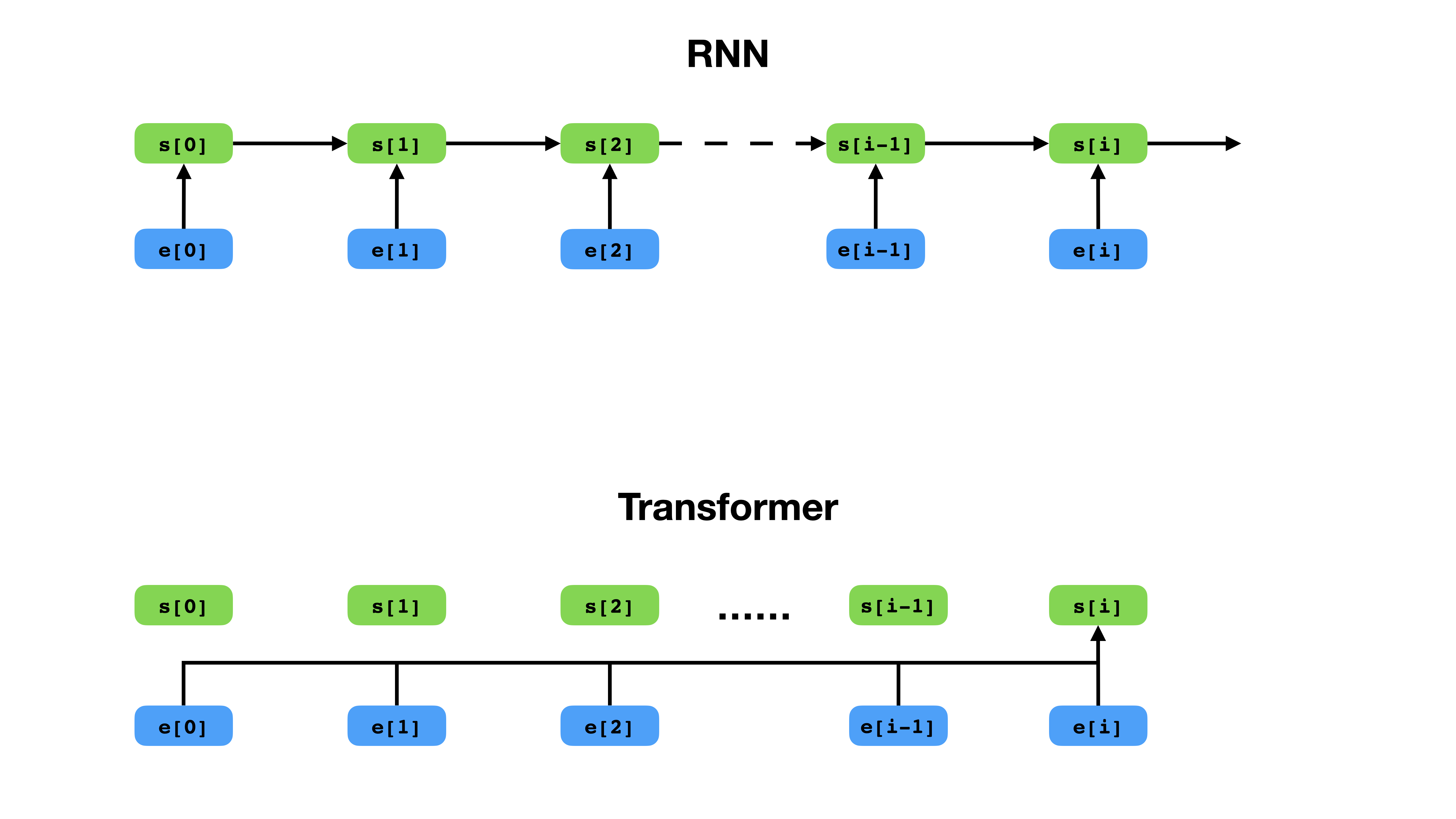
يتمتع Transformer طريقة أكثر مرونة لتمثيل السياق مقارنة مع RNN.
Transformer هو بنية الشبكة العصبية العميقة لنمذجة التسلسل ، وهي مهمة تقدير احتمال وجود الرموز في تسلسل بناءً على سياقها النصي. في حين أن الشبكات العصبية المتكررة تنهار تضمينات التاريخ بأكمله لرموز السياق في متجه واحد ، فإن المحول لديه إمكانية الوصول إلى ناقل التضمين لكل رمز على حدة ، بغض النظر عن مدى امتداد السياق. هذا يجعلها مناسبة تمامًا لنمذجة علاقات الاعتماد على المدى الطويل ، وهو أمر مفتاح الاختراقات الحديثة في طرق تعلم تمثيل النص مثل BERT و GPT-2.
في صميم المحول آلية الاهتمام الذاتي ، حيث يكون الهدف هو حساب تمثيل سياق لكل رمز في تسلسل من خلال السماح لهم "بالانتباه" لبعضهم البعض. بالنظر إلى تمثيل المتجه الأولي e[i] بالنسبة لجميع المواقف i ، فإنه يطبق أولاً التوقعات الخطية للحصول على المتجهات q[i] ، k[i] ، v[i] ، حيث تلعب k و v دور المفتاح والقيمة لقاعدة المعرفة حول محتوى التسلسل ، والتي يجب الاستعلام عنها بواسطة q[i] لتحديد أي شيء يشبه token token i . نتائج الاستعلام هي ببساطة درجات التشابه بين q[i] و k (عادةً منتجات نقطة) ، والتي تستخدم كأوزان لحساب متوسط مرجح لـ v كتمثيل جديد لـ e[i] . لاحظ أن q و k و v مستمدة من نفس التسلسل ، مما يعني أن التسلسل يستفسر بشكل فعال عن نفسه (ومن هنا الاسم الاهتمام الذاتي).
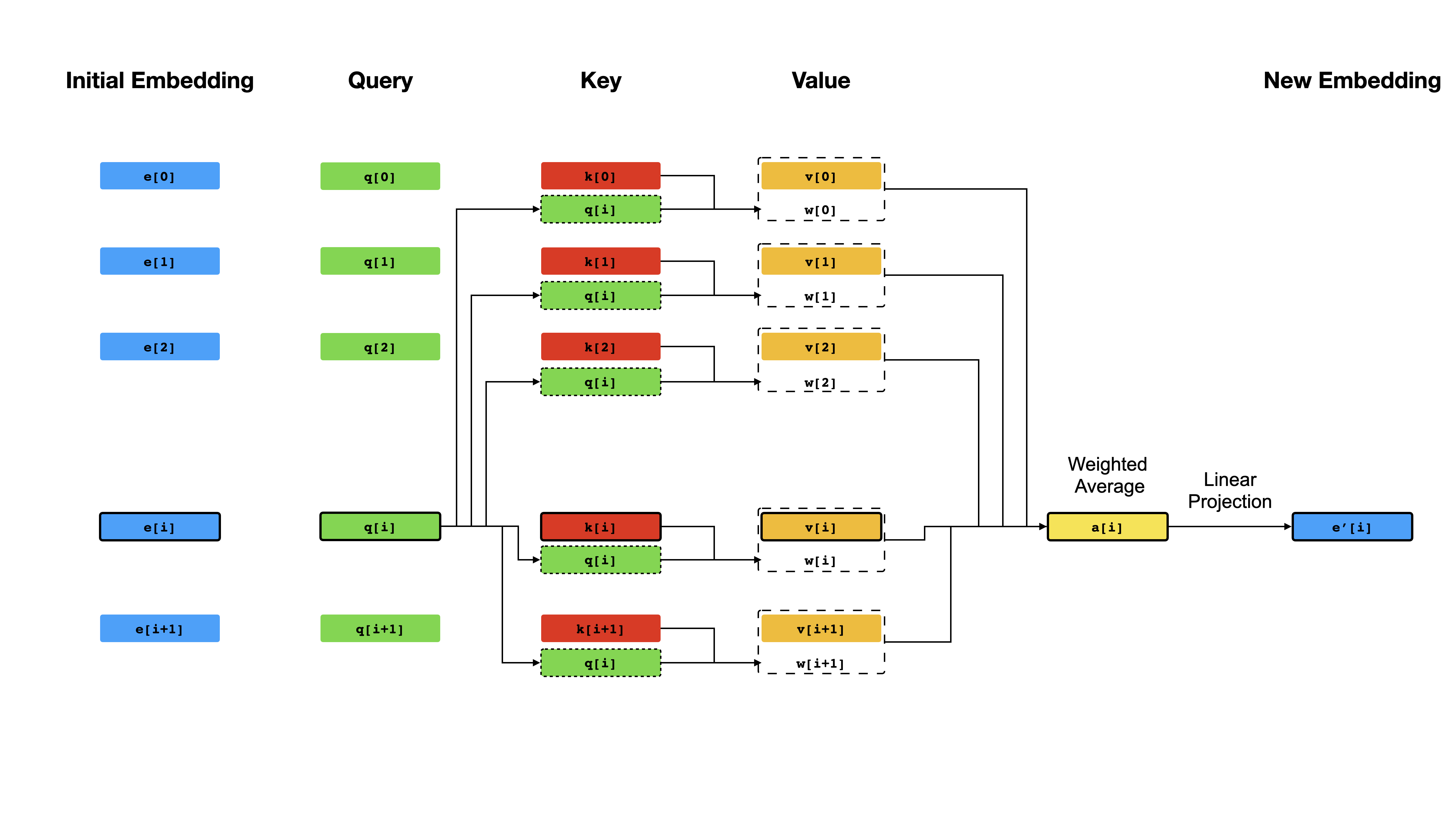
آلية الاهتمام الذاتي.
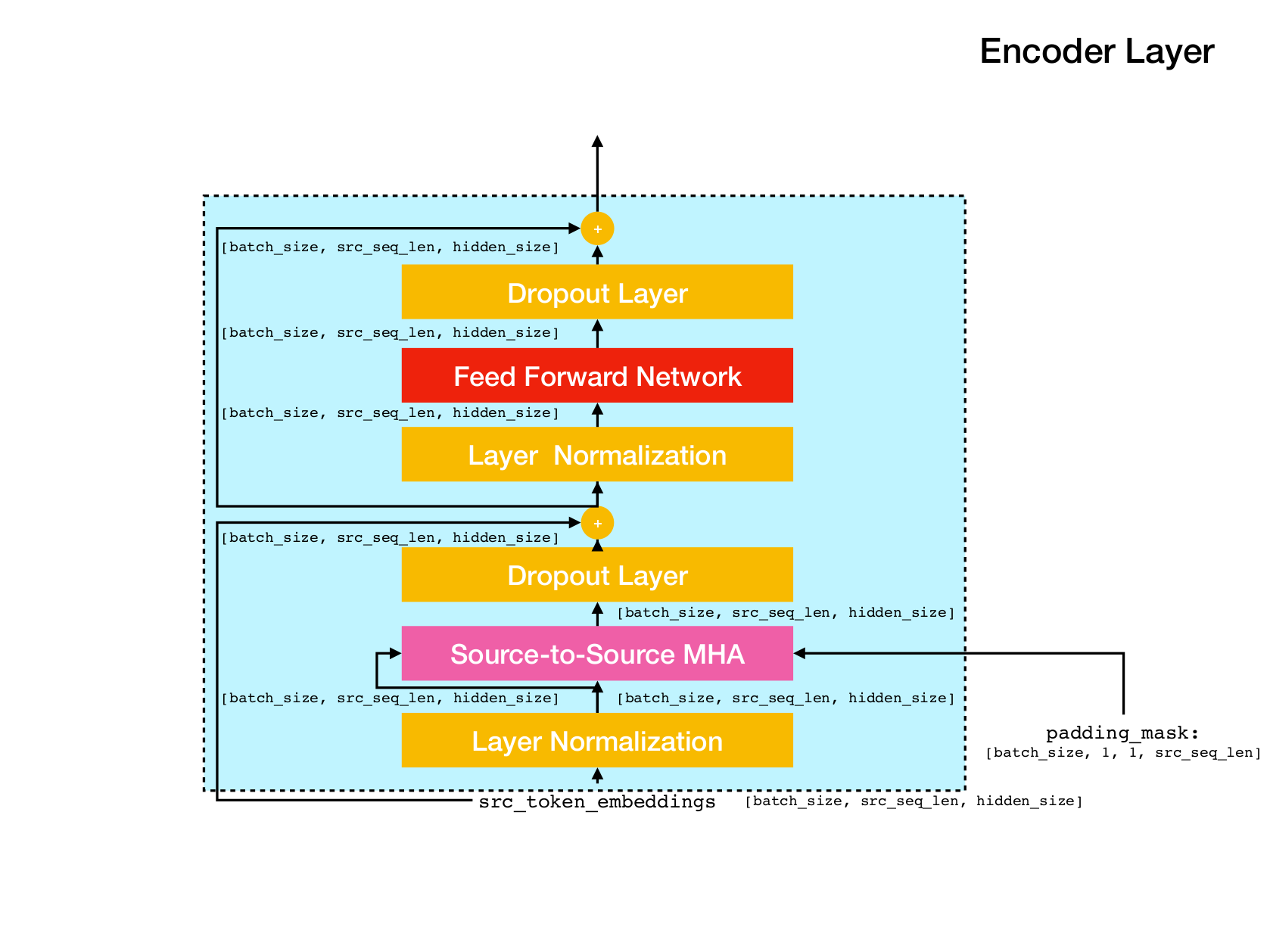
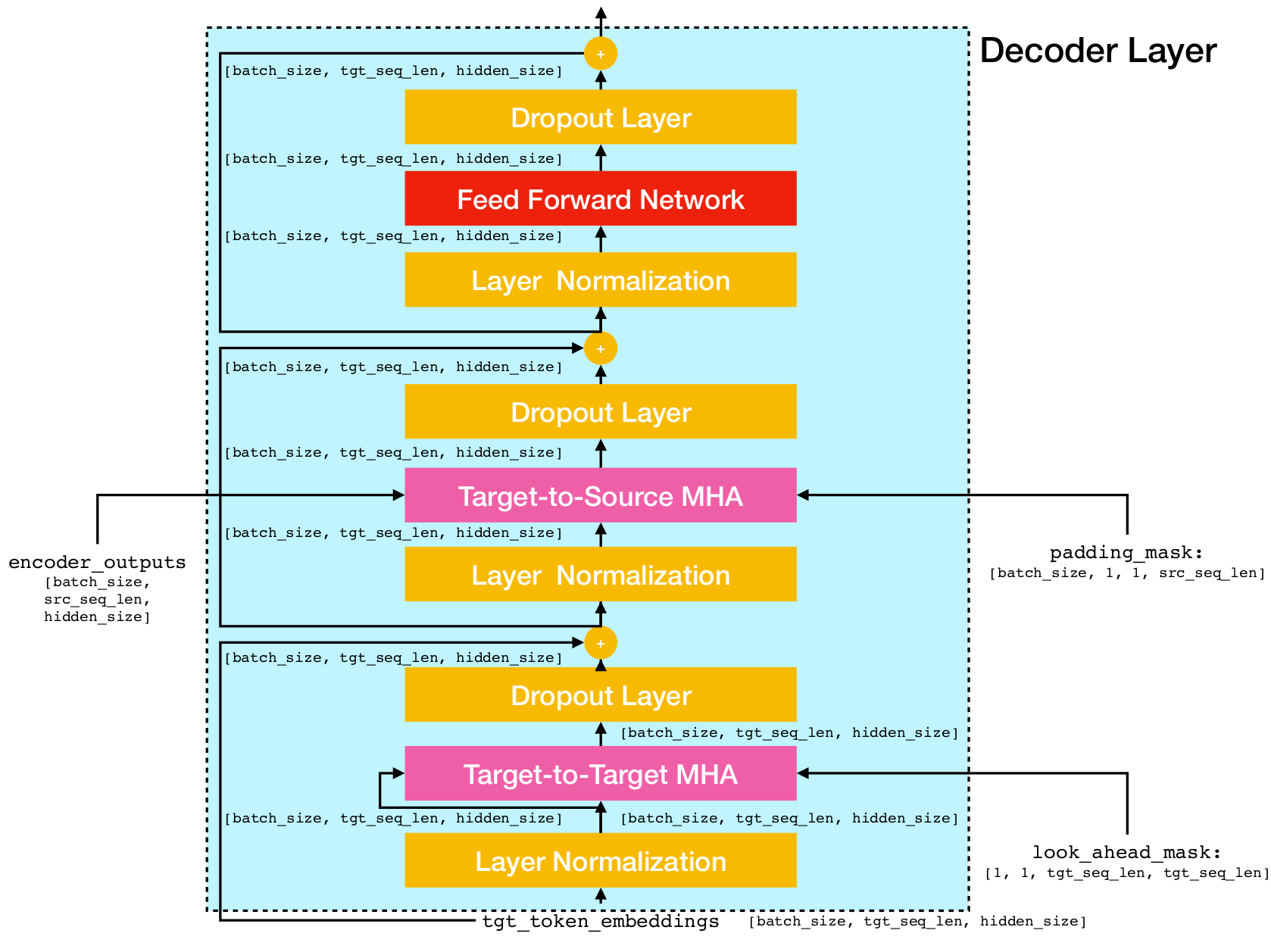
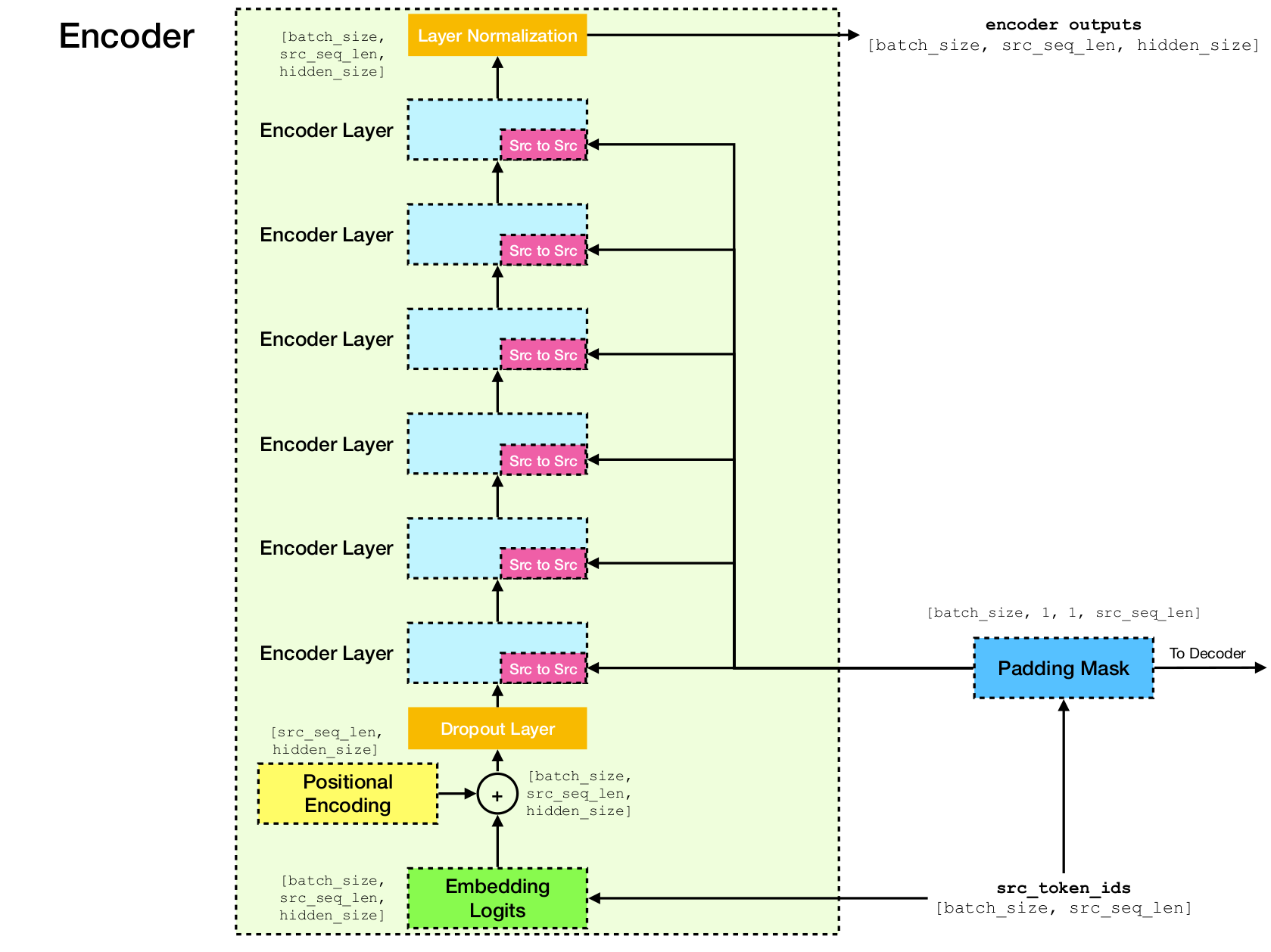
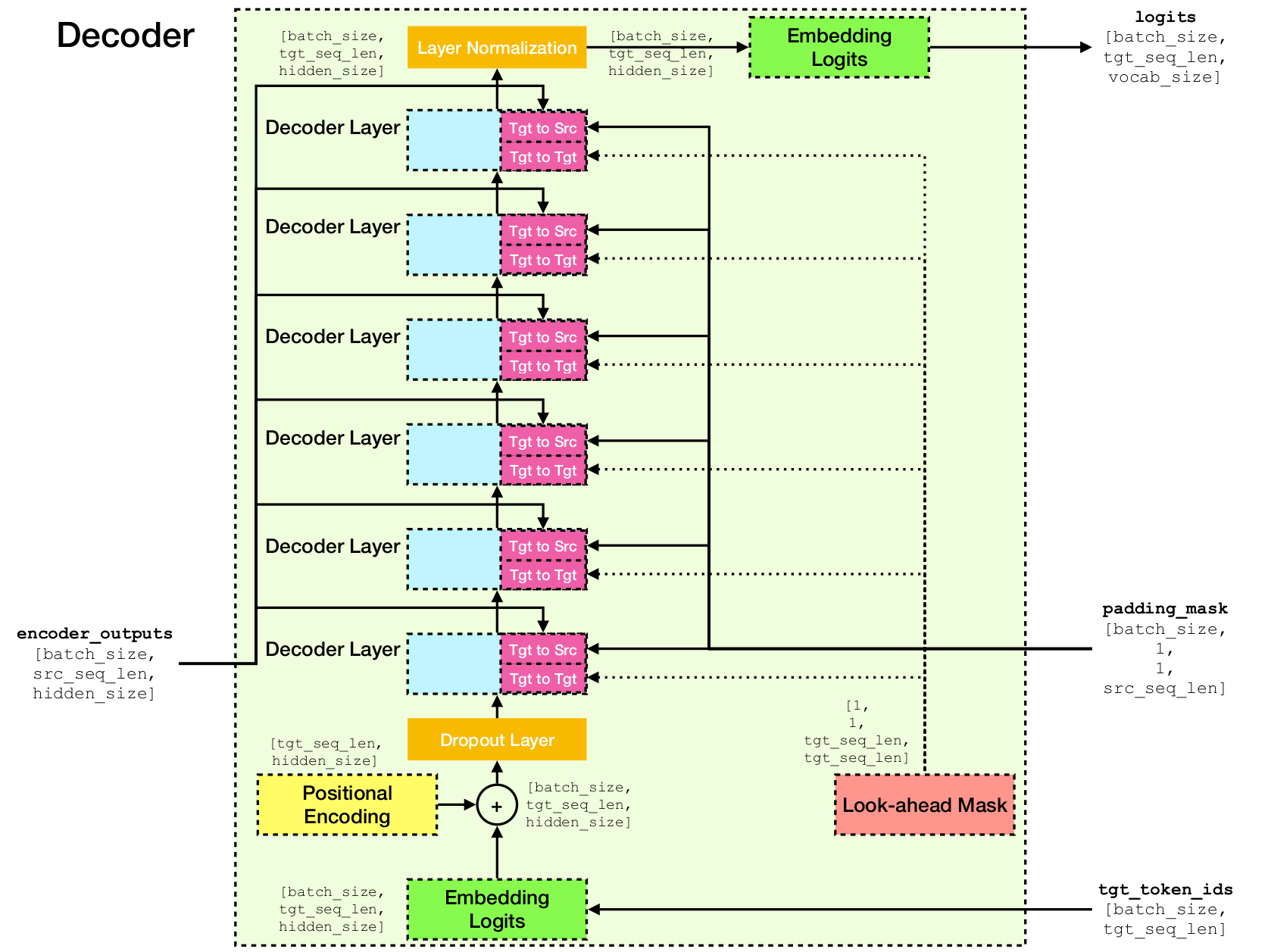
بنية شبكة المحولات.
يعتمد هذا التنفيذ على TensorFlow 2.x و Python3. بالإضافة إلى ذلك ، مطلوب NLTK لحساب درجة Bleu للتقييم.
يمكنك استنساخ هذا المستودع من خلال التشغيل
git clone [email protected]:chao-ji/tf-transformer.gitثم استنساخ وتحديث الجهاز الفرعي عن طريق التشغيل
cd tf-transformer
git submodule update --init --recursiveيجب أن تكون مجموعة التدريب في شكل قائمة بالملفات النصية في لغة المصدر ، مقترنة بقائمة من الملفات النصية في اللغة المستهدفة ، حيث تحتوي الخطوط (على الجمل) في ملفات نصية المصدر على مراسلات واحدة إلى واحد إلى خطوط في ملفات اللغة المستهدفة
source_file_1.txt target_file_1.txt
source_file_2.txt target_file_2.txt
...
source_file_n.txt target_file_n.txt
تحتاج أولاً إلى تحويل الملفات النصية الخام إلى ملفات tfrecord عن طريق التشغيل
python commons/create_tfrecord_machine_translation.py
--source_filenames=source_file_1.txt,source_file_2.txt,...,source_file_2.txt
--target_filenames=target_file_1.txt,target_file_2.txt,...,target_file_2.txt
--output_dir=/path/to/tfrecord/directory
--vocab_name=vocab ملاحظة: تتضمن هذه العملية "تعلم" مفردات لرموز الكلمات الفرعية من مجموعة التدريب ، والتي يتم حفظها في الملفات vocab.subtokens و vocab.alphabet . سيتم استخدام المفردات لاحقًا لترميز سلسلة النص الخام إلى معرفات رمزية من الكلمات الفرعية ، أو فك تشفيرها مرة أخرى إلى سلسلة النص الخام.
للحصول على معلومات مفصلة للاستخدام ، قم بتشغيل
python commons/create_tfrecord_machine_translation.py --helpلعينة البيانات ، ارجع إلى data_sources.txt
لتدريب نموذج ، قم بالتشغيل
python run_trainer.py
--data_dir=/path/to/tfrecord/directory
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints data_dir هو الدليل الذي يقوم بتخزين ملفات tfrecord ، vocab_path هو المسار إلى الاسم الأساسي لملفات المفردات vocab.subtokens و vocab.alphabet (أي مسار إلى vocab ) التي تم إنشاؤها عن طريق تشغيل create_tfrecord_machine_translation.py ، و model_dir هي التي سيتم حفظها في نقطة التحقيق التي يتم تحصيلها (أو يتم تحميلها من النقطة السابقة.
للحصول على معلومات مفصلة للاستخدام ، قم بتشغيل
python run_trainer.py --helpيتضمن التقييم ترجمة تسلسل المصدر إلى التسلسل المستهدف ، وحساب درجة BLEU بين التسلسل المستهدف المتوقع والولايات المتحدة.
لتقييم نموذج ما قبل المسبق ، قم بالتشغيل
python run_evaluator.py
--source_text_filename=/path/to/source/text/file
--target_text_filename=/path/to/target/text/file
--vocab_path=/path/to/vocab/files
--model_dir=/path/to/directory/storing/checkpoints source_text_filename و target_text_filename هي مسارات للملفات النصية التي تحتفظ بتسلسل المصدر والهدف ، على التوالي.
لاحظ أن خطوط سطر الأوامر target_text_filename اختياري - إذا تم تركها ، فسيتم تشغيل المقيِّم في وضع الاستدلال ، حيث سيتم كتابة الترجمات فقط إلى ملف الإخراج.
لمزيد من معلومات الاستخدام التفصيلية ، قم بتشغيل
python run_evaluator.py --help لاحظ أن آلية الانتباه تحسب أوجه التشابه في الرمز المميز الذي يمكن تصوره لفهم كيفية توزيع الاهتمام على الرموز المميزة المختلفة. عندما تقوم بتشغيل python run_evaluator.py سيتم حفظ مصفوفات الوزن الانتباه لتقديم attention_xxxx.npy ، الذي يخزن إدخالات الإدخالات التالية:
src : صفيف numpy من الشكل [batch_size, src_seq_len] ، حيث يكون كل صف عبارة عن تسلسل من معرفات الرمز المميز الذي ينتهي بـ 1 ( EOS_ID ) ومبادئ للأصفار.tgt : صفيف numpy من الشكل [batch_size, tgt_seq_len] ، حيث يكون كل صف تسلسلًا من معرفات الرمز المميز الذي ينتهي بـ 1 ( EOS_ID ) ومبادئ للأصفار.src_src_attention : صفيف Numpy من الشكل [batch_size, num_heads, src_seq_len, src_seq_len]tgt_src_attention : صفيف numpy من الشكل [batch_size, num_heads, tgt_seq_len, src_seq_len]tgt_tgt_attention : صفيف الشكل numpy [batch_size, num_heads, tgt_seq_len, tgt_seq_len]يمكن عرض أوزان الانتباه عن طريق التشغيل:
python run_visualizer.py
--attention_file=/path/to/attention_xxxx.npy
--head=attention_head
--index=seq_index
--vocab_path=/path/to/vocab/files حيث يكون head عددًا صحيحًا في [0, num_heads - 1] index هو عدد صحيح في [0, batch_size - 1] .
الموضحة أدناه هي ثلاث جمل باللغة الإنجليزية (لغة المصدر) وترجماتها باللغة الألمانية (اللغة المستهدفة).
جمل الإدخال في المصدر langauge
1. It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.
2. Google's free service instantly translates words, phrases, and web pages between English and over 100 other languages.
3. What you said is completely absurd.
الجمل المترجمة باللغة المستهدفة
1. In diesem Sinne haben die meisten amerikanischen Regierungen seit 2009 neue Gesetze verabschiedet, die die Registrierung oder das Abstimmungsverfahren schwieriger machen.
2. Der kostenlose Service von Google übersetzt Wörter, Phrasen und Webseiten zwischen Englisch und über 100 anderen Sprachen.
3. Was Sie gesagt haben, ist völlig absurd.
يحسب نموذج المحول ثلاثة أنواع من الاهتمام:
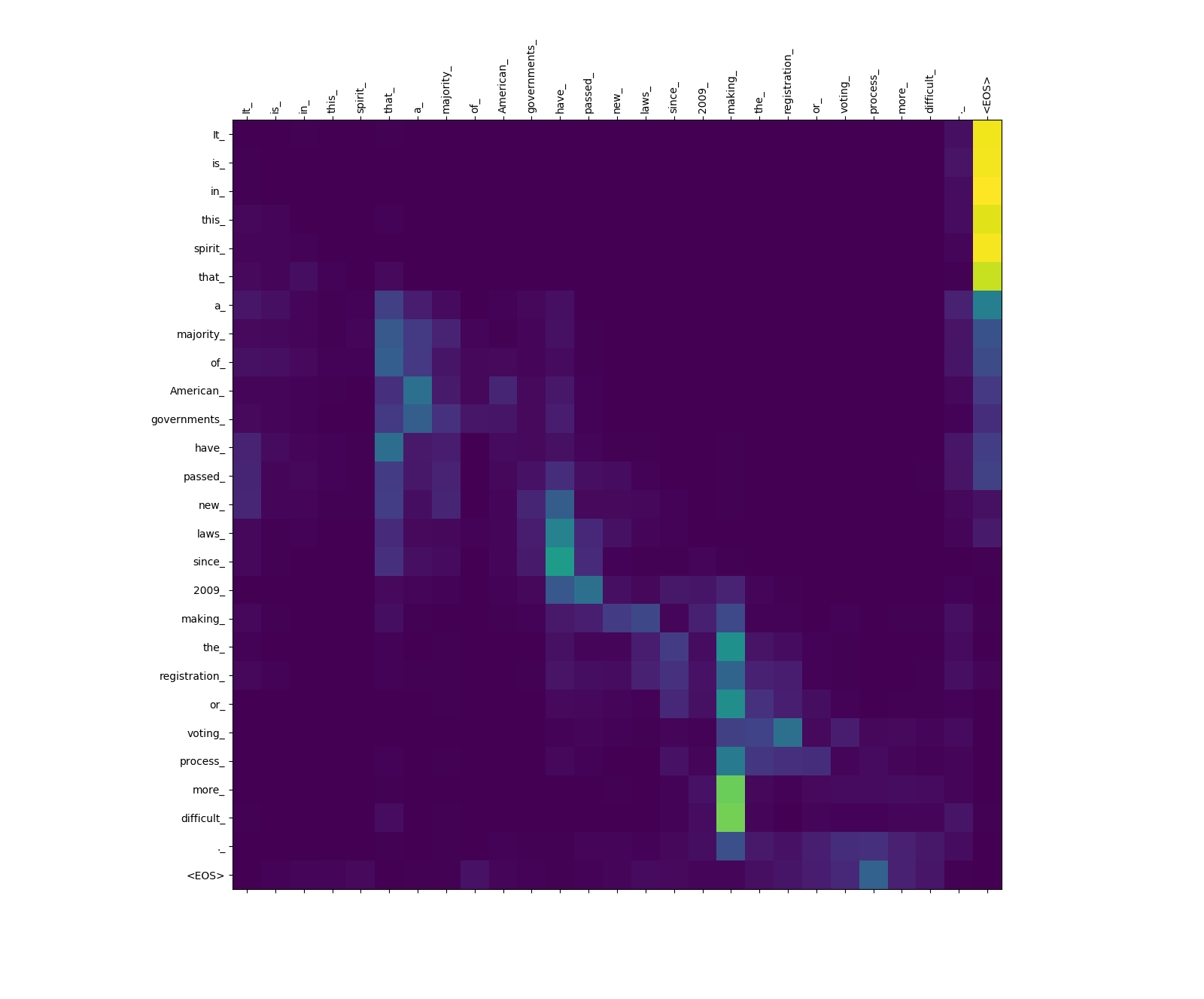
أوزان الاهتمام مصدر إلى مصدر.
لاحظ وزن الانتباه من more_ و difficult_ إلى making_ - فهي "على مراقبة" لـ "الفعل" "عند محاولة إكمال العبارة" تجعل ... أكثر صعوبة ".
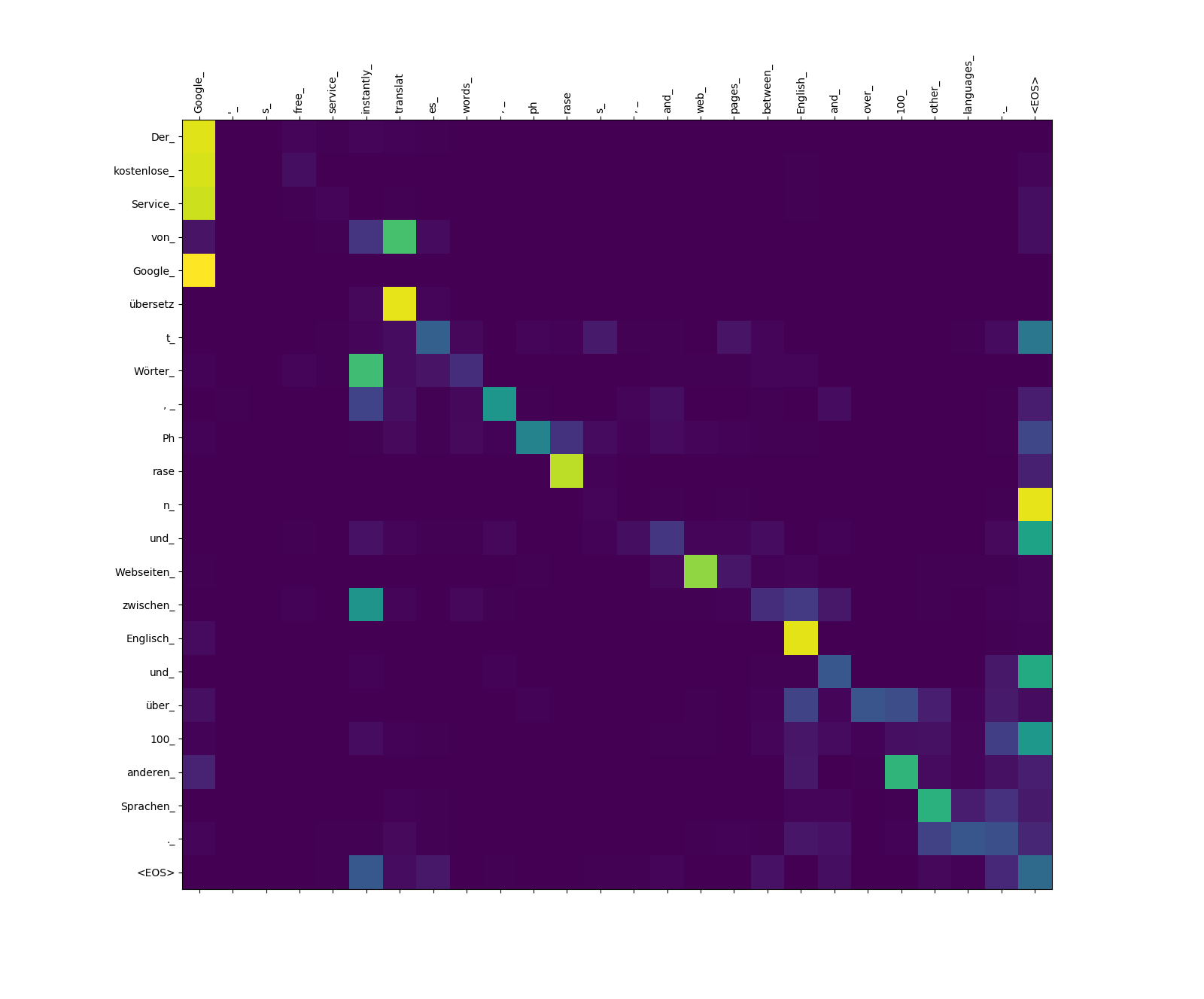
أوزان الانتباه الهدف إلى المصدر.
لاحظ وزن الانتباه من übersetz (الهدف) إلى translat (المصدر) ، ومن Webseiten (الهدف) إلى web (المصدر) ، وما إلى ذلك ربما يكون ذلك بسبب مرادفها باللغة الألمانية والإنجليزية.
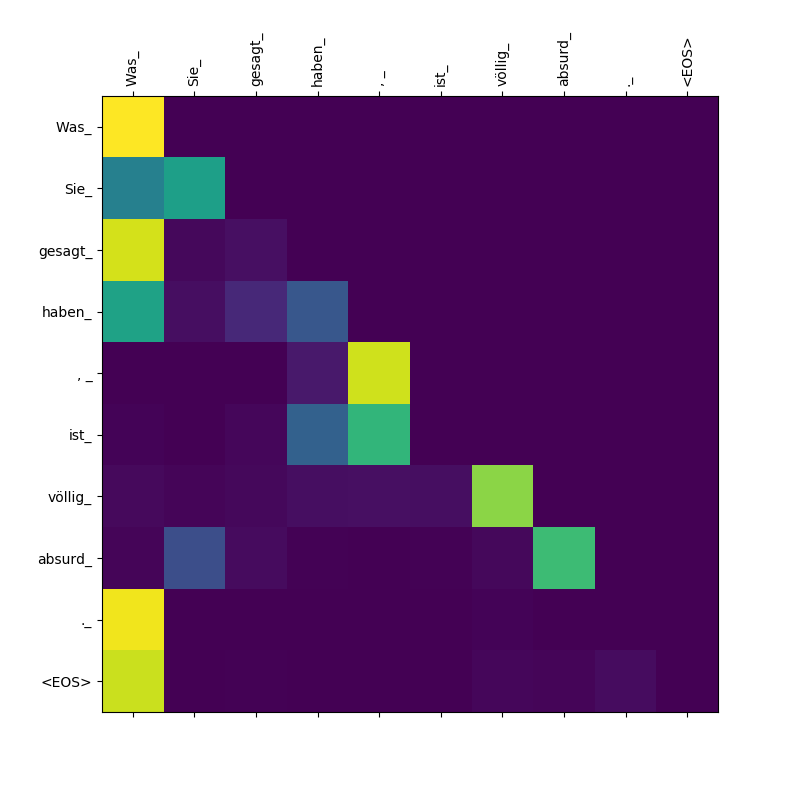
الأوزان الانتباه الهدف إلى الهدف.
لاحظ أن الاهتمام الذي تم إحياءه به Was ، Sie_ ، gesagt ، haben_ - حيث يبصق وحدة فك الترميز هذه subtokens ، يجب أن "على علم" بنطاق البند Was Sie gesagt haben Was بمعنى "ما قلته").


