FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
该项目是通过将Hifi-Gan Vocoder与FastSpeech2相结合的韩国多演讲者TTS实现的。
该项目旨在开发“可见的个性化AI扬声器”项目的TT 。它被您想要的周围人的声音所取代,而不是“ Siri”,“ Bixby”和“ Ari”的声音。 (例如配偶,儿子,女儿,父母等)
为了应付立即生产AI扬声器,而不是Tacotron2和WaveGlow的出色性能,而是非自动效率的Mostspeech2和基于GAN的Vocoder模型Hifi-GAN采用了质量和生产速度。
基于与DLLAB中实现的韩国数据集KSS相对应的FastSpeech2源代码。
所使用的代码中的添加内容如下。
扬声器嵌入实施(韩国多演讲者FastSpeech2)
data_preprocessing.py-end-end-to-end数据预处理实现,包含以下所有项目
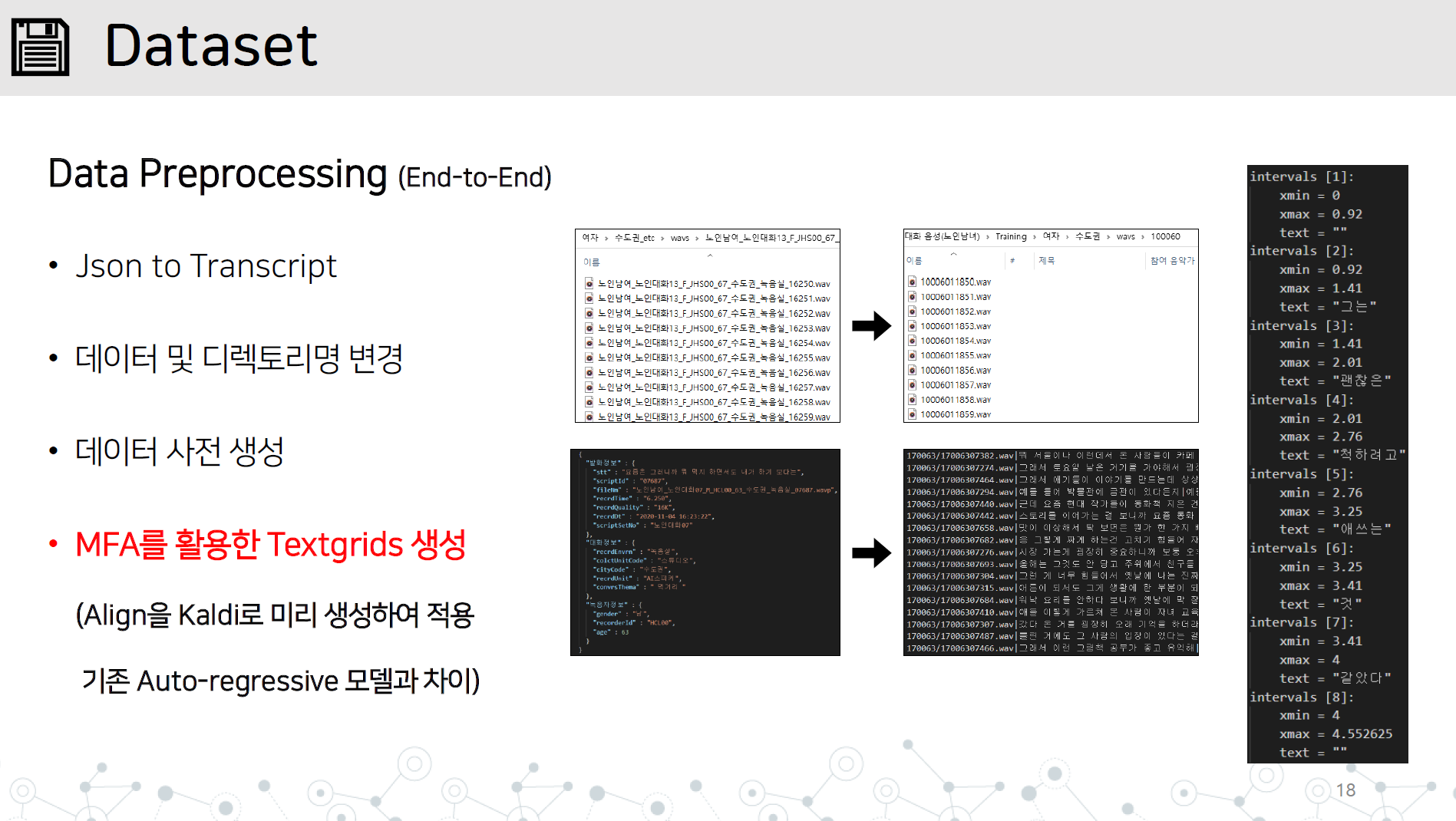
对长句子不稳定综合的反应

导入G2PK源代码,仅应用数字和英语
如图所示,将WAV目录和JSON或成绩单文件保存在数据集/数据名称中。
学习Kaldi的蒙特拉尔强迫艾林格通过学习音频数据来学习Textgrid 。
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
保存HIFI-GAN学到的发电机在Vocoder/Prepained_models目录中学习期间进行评估。
设置Hparam.py的批处理大小,HIFI-GAN生成器并开始学习的路径。
python train.py
如果您正在学习,则可以通过添加Restore_Step来学习。
python train.py --restore_step [step]
如果您对多演讲者进行预训练,则存储扬声器_INFO.JSON自动在预训练期间生成
将speeder_info.json放在目录的顶部
与在火车上进行研究一样,运行Python
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
该管道是与服务相对应的TTS学习和创建的流动管道。
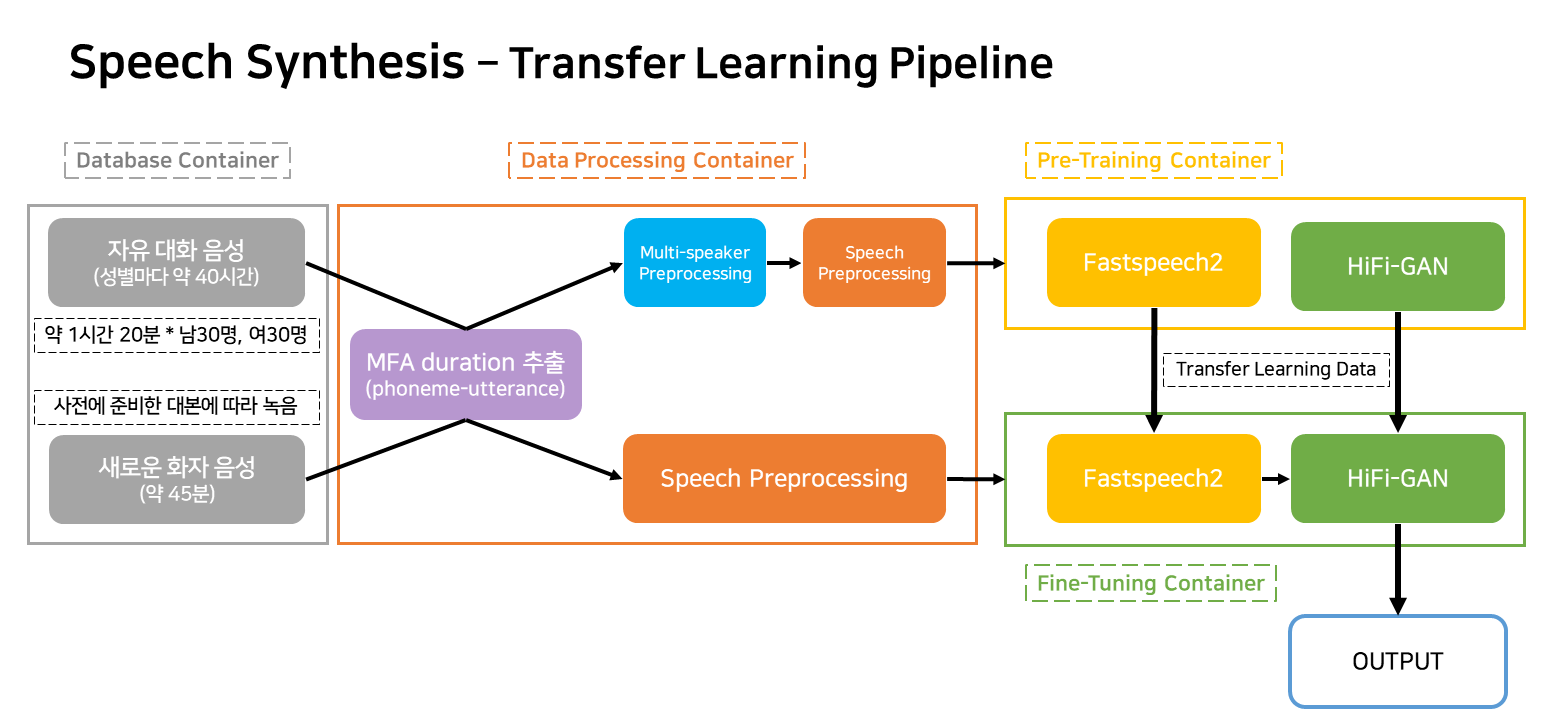
容器在很大程度上被归类为四个。
在实际的服务情况下,只有三个容器可以工作。


