FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
FastSpeech2에 HiFi-GAN Vocoder를 결합하여, 한국어 Multi-Speaker TTS로 구현한 프로젝트 입니다.
본 프로젝트는 ‘보이는 개인화 AI 스피커’ 프로젝트의 TTS 개발을 목표합니다. 기존에 식상한 '시리', '빅스비', '아리'의 목소리가 아닌 사용자가 원하는 주변 사람의 목소리로 대체합니다. (ex. 배우자, 아들, 딸, 부모님 등)
AI 스피커라는 즉각적인 생성에 대응하기 위해 기존에 뛰어난 성능의 Tacotron2와 Waveglow 대신 Non-Autoregressive Acoustic Model FastSpeech2과 GAN 기반 Vocoder Model HiFi-GAN을 채택하여 퀄리티와 생성 속도 모두 고려합니다.
DLLAB에서 구현한 한국어 데이터셋 KSS에 대응하는 FastSpeech2 소스 코드를 기반으로 구현되었습니다.
활용한 코드에서 추가된 내용은 다음과 같습니다.
Speaker Embedding 구현 (Korean Multi-Speaker FastSpeech2)
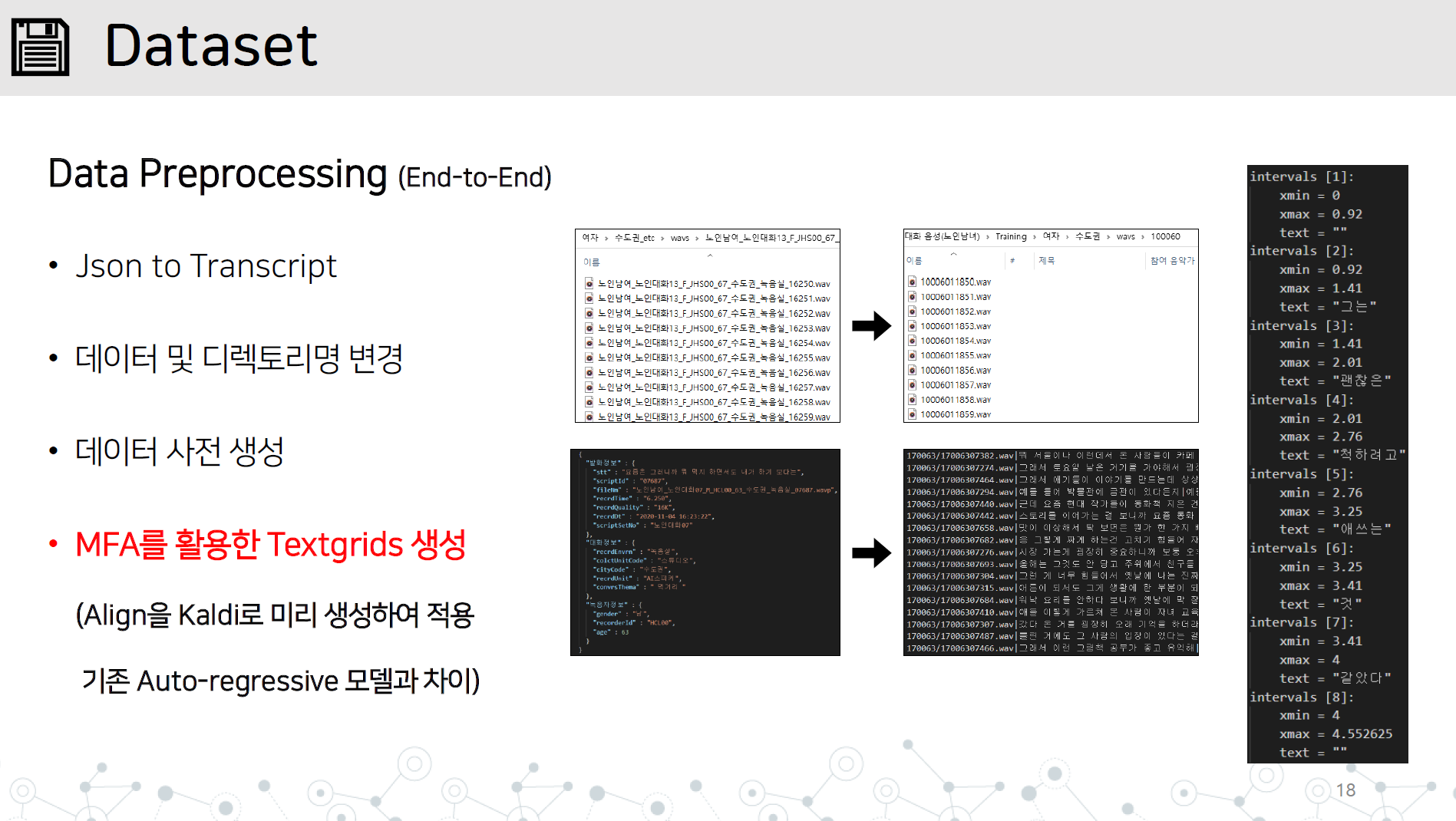
data_preprocessing.py - 아래 항목을 모두 포함하는 end-to-end 데이터 전처리 구현
긴 문장에 대한 불안정한 합성 시 대응

G2pk 소스 코드를 불러와 숫자, 영어만 변환하도록 적용
그림과 같이 wav 디렉토리와 json 또는 transcript 파일을 dataset/데이터명 디렉토리에 저장합니다.
Kaldi로 구현된 Montral Forced Alinger를 오디오 데이터에 학습하여 Textgrid를 얻습니다.
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
학습 중 평가를 위해 HiFi-GAN으로 학습한 generator를 vocoder/pretrained_models 디렉토리에 저장합니다.
hparam.py의 batch size, HiFi-GAN generator의 path를 설정하고 학습을 시작합니다.
python train.py
재학습을 하게 될 경우, restore_step을 추가하여 재학습이 가능합니다.
python train.py --restore_step [step]
Multi-Speaker에 대한 Pre-train을 수행할 경우, Pre-train 학습 시 자동으로 생성된 speaker_info.json 저장
디렉토리 최상단에 speaker_info.json을 넣고 ckpt/데이터이름 디렉토리에 pth.tar 체크포인트 복사
Train에서 재학습을 수행하는 것과 동일하게 파이썬 실행
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
본 파이프라인은 서비스에 해당되는 TTS 학습 및 생성에 대한 flow 파이프라인 입니다.
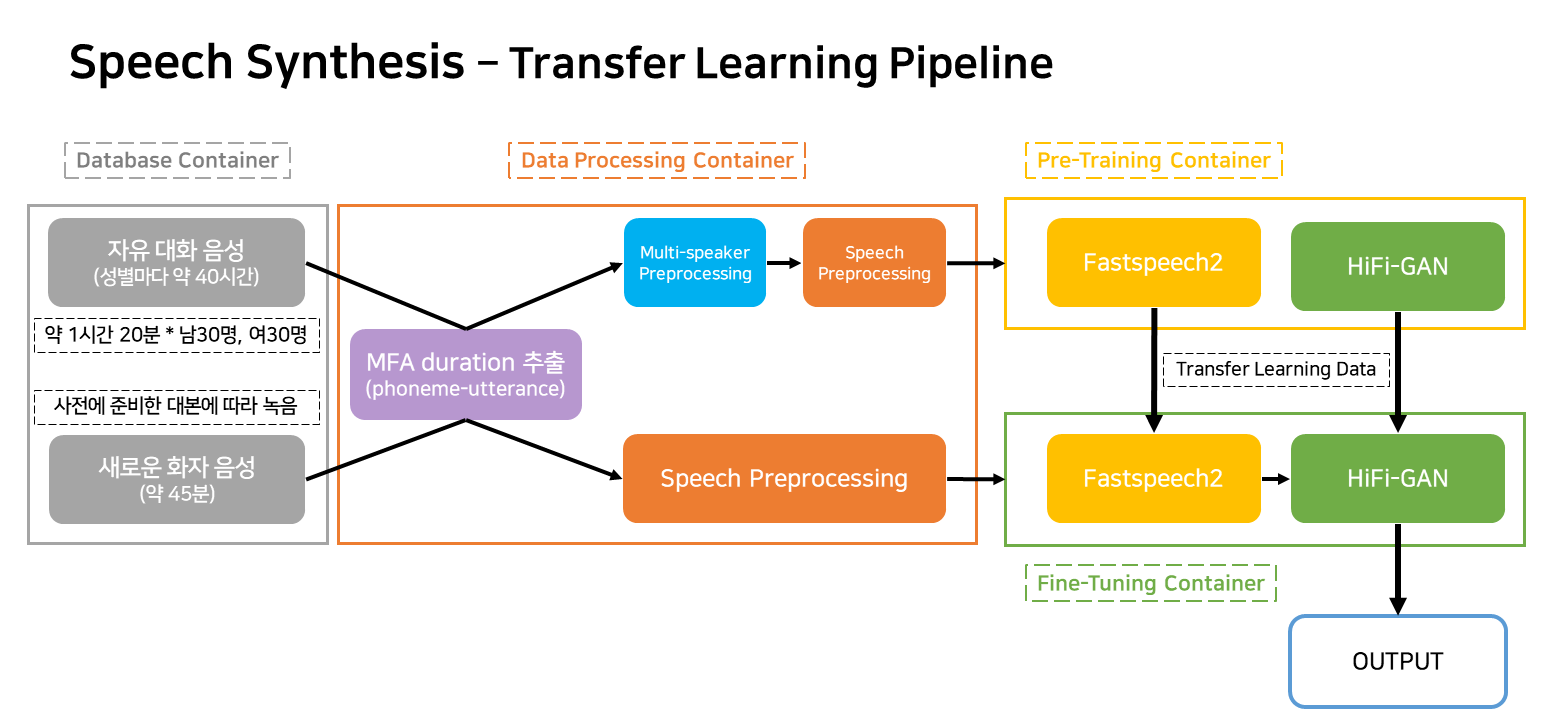
컨테이너는 크게 4개로 분류됩니다.
실제 서비스 상황엔 Pre-trianing 컨테이너 외 3개 컨테이너만 작동하게 됩니다.


