FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
Proyek ini diimplementasikan dalam TTS multi-speaker Korea dengan menggabungkan vocoder hifi dengan fastspeech2.
Proyek ini bertujuan untuk mengembangkan TTS proyek 'speaker AI yang dipersonalisasi' . Ini digantikan oleh suara orang -orang di sekitar yang Anda inginkan, bukan suara 'Siri', 'Bixby' dan 'Ari'. (Kel. Pasangan, putra, putri, orang tua, dll.)
Untuk mengatasi produksi speaker AI langsung, alih-alih kinerja TACOTRON2 dan Waveglow yang sangat baik, Mostspeech2 dan model Vocoder berbasis GAN yang tidak diadopsi baik mengadopsi kualitas dan kecepatan produksi mempertimbangkannya.
Berdasarkan Kode Sumber FastSpeech2 yang sesuai dengan Dataset Korea KSS yang diimplementasikan di DLLAB.
Konten yang ditambahkan dalam kode yang digunakan adalah sebagai berikut.
Implementasi Embedding Speaker (FastSpeech2 multi-speaker Korea)
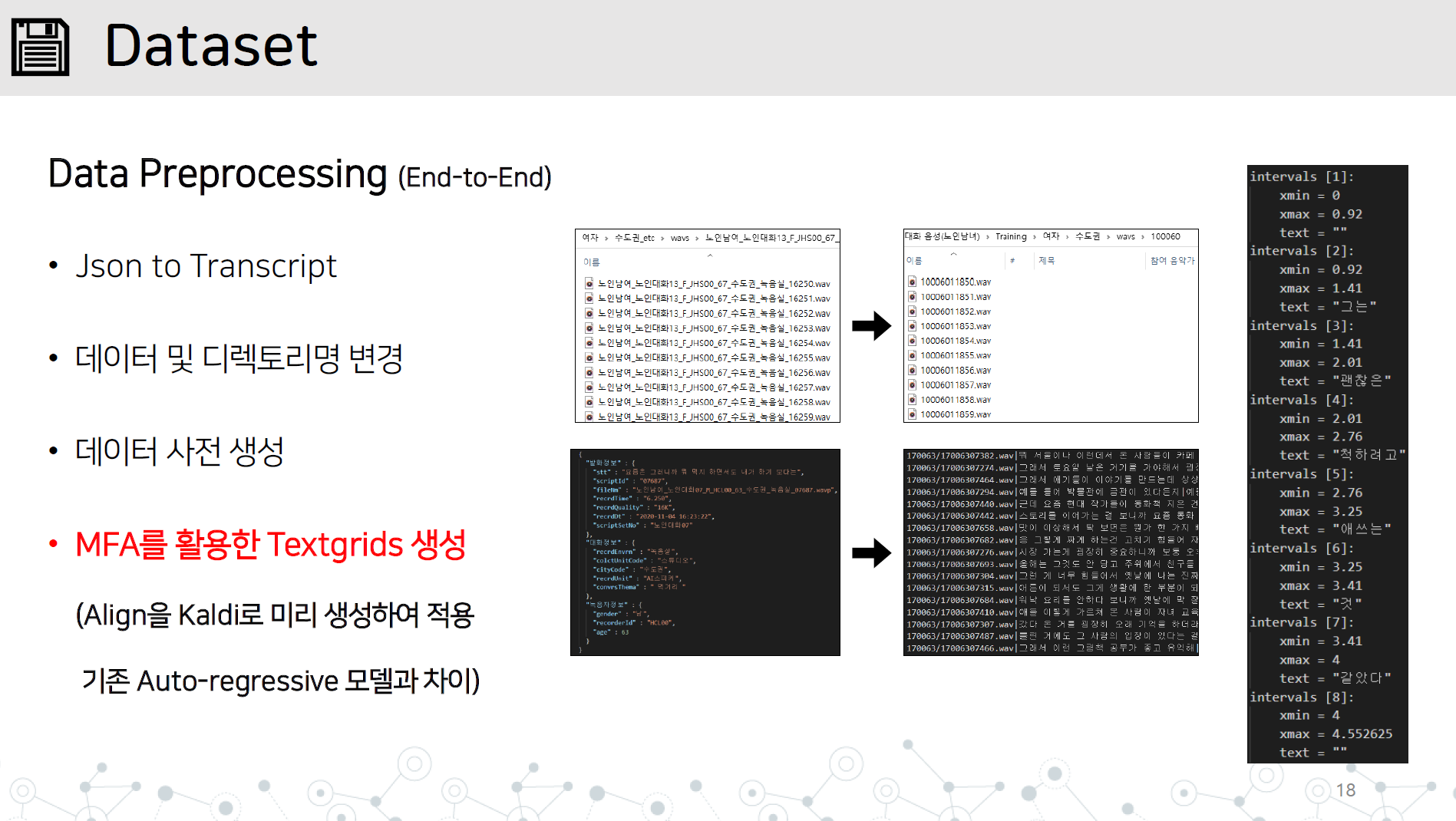
Data_preprocessing.py-end-end-end-data implementasi pretreatment yang berisi semua item di bawah ini
Respons terhadap sintesis kalimat panjang yang tidak stabil

Mengimpor kode sumber G2PK dan hanya menerapkan angka dan bahasa Inggris
Simpan direktori WAV dan file JSON atau transkrip di Dataset/Data Name Directory seperti yang ditunjukkan.
Pelajari Montral Forced Alinger di Kaldi untuk belajar TextGrid dengan mempelajari data audio.
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
Simpan generator yang dipelajari oleh HiFi-Gan untuk evaluasi selama belajar di direktori Vocoder/Pretained_Models.
Siapkan jalur ukuran batch hparam.py, generator hifi-gan dan mulailah belajar.
python train.py
Jika Anda belajar, Anda dapat belajar dengan menambahkan restore_step.
python train.py --restore_step [step]
Jika Anda melakukan pra-pelatihan untuk multi-speaker, speaker storage_info.json secara otomatis dihasilkan selama pembelajaran pra-kereta
Letakkan speaker_info.json di bagian atas direktori
Jalankan Python dengan cara yang sama seperti melakukan studi di kereta
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
Pipa ini adalah pipa aliran untuk pembelajaran dan penciptaan TTS yang sesuai dengan layanan.
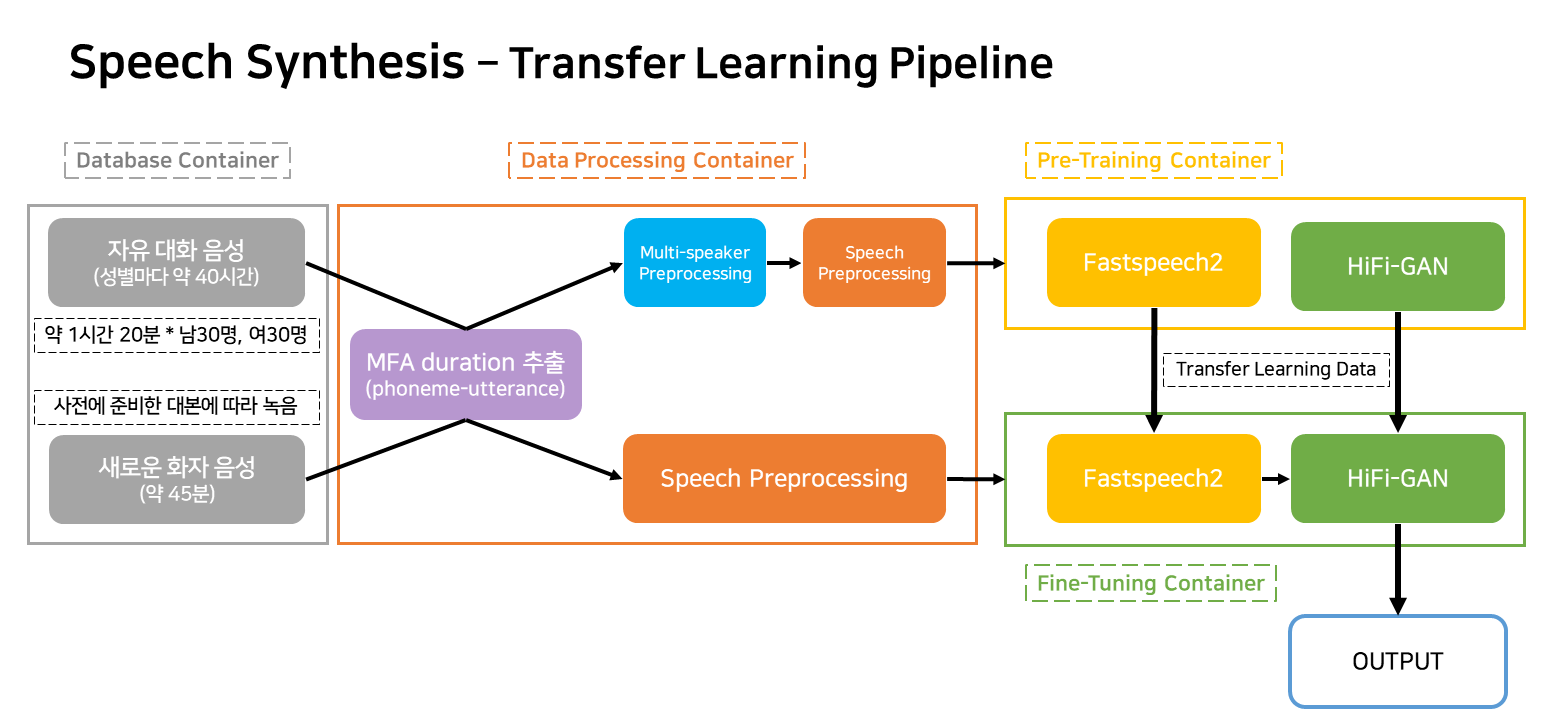
Wadah sebagian besar diklasifikasikan sebagai empat.
Dalam situasi layanan yang sebenarnya, hanya tiga kontainer yang akan bekerja.


