FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
Este proyecto se implementa en TTS múltiples coreanos TTS combinando Hifi-Gan Vocoder con FastSpeech2.
Este proyecto tiene como objetivo desarrollar el TTS del proyecto 'Player de IA personalizado visible' . Es reemplazado por las voces de las personas que lo rodean desean, en lugar de las voces de 'Siri', 'Bixby' y 'Ari'. (Ex. Cónyuge, hijo, hija, padres, etc.)
Con el fin de hacer frente a la producción inmediata de altavoces de IA, en lugar de un excelente rendimiento de Tacotron2 y Wavlow, el modelo de vocoder de Vocoder no autorregresivo y no autorregresivo y el modelo de vocoder basado en GaN adoptaron la calidad y la velocidad de producción lo consideran.
Basado en el código fuente de FastSpeech2 que corresponde al KSS de conjunto de datos coreano implementado en DLLAB.
El contenido agregado en el código utilizado es el siguiente.
Implementación de incrustación de oradores (FastSpeech2 de múltiples altavoces coreano)
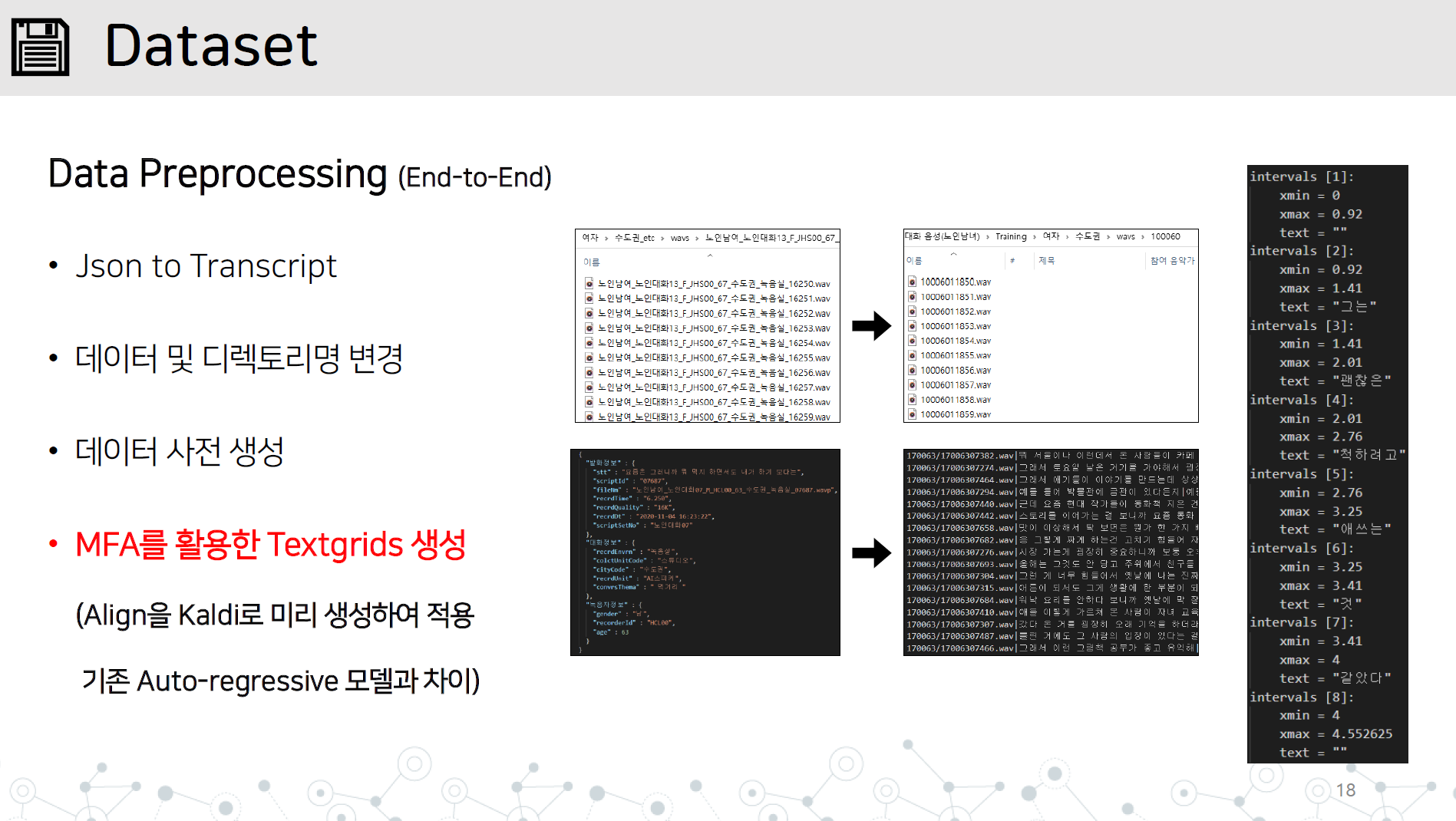
Data_processing.py-end-to-end data implementación de pretratamiento que contiene todos los elementos a continuación
Respuesta a la síntesis inestable de oraciones largas

Importar código fuente G2PK y aplicar solo números e inglés
Guarde el directorio WAV y el archivo JSON o de transcripción en el directorio de nombre de datos/datos de datos como se muestra.
Aprenda a Montal Forced Alinger en Kaldi a aprender TextGrid aprendiendo datos de audio.
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
Guarde el generador aprendido por Hifi-Gan para su evaluación durante el aprendizaje en el directorio Vocoder/Pretined_Models.
Configure la ruta del tamaño de lotes de HPARAM.PY, el generador Hifi-Gan y comience a aprender.
python train.py
Si está estudiando, puede aprender agregando restaure_step.
python train.py --restore_step [step]
Si realiza un entrenador previo para múltiples altavoces, Storage Speaker_info.json generó automáticamente durante el aprendizaje previo al tren
Pon Speaker_info.json en la parte superior del directorio
Ejecutar Python de la misma manera que realizar un estudio en el tren
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
Esta tubería es una tubería de flujo para el aprendizaje y la creación de TTS que corresponde al servicio.
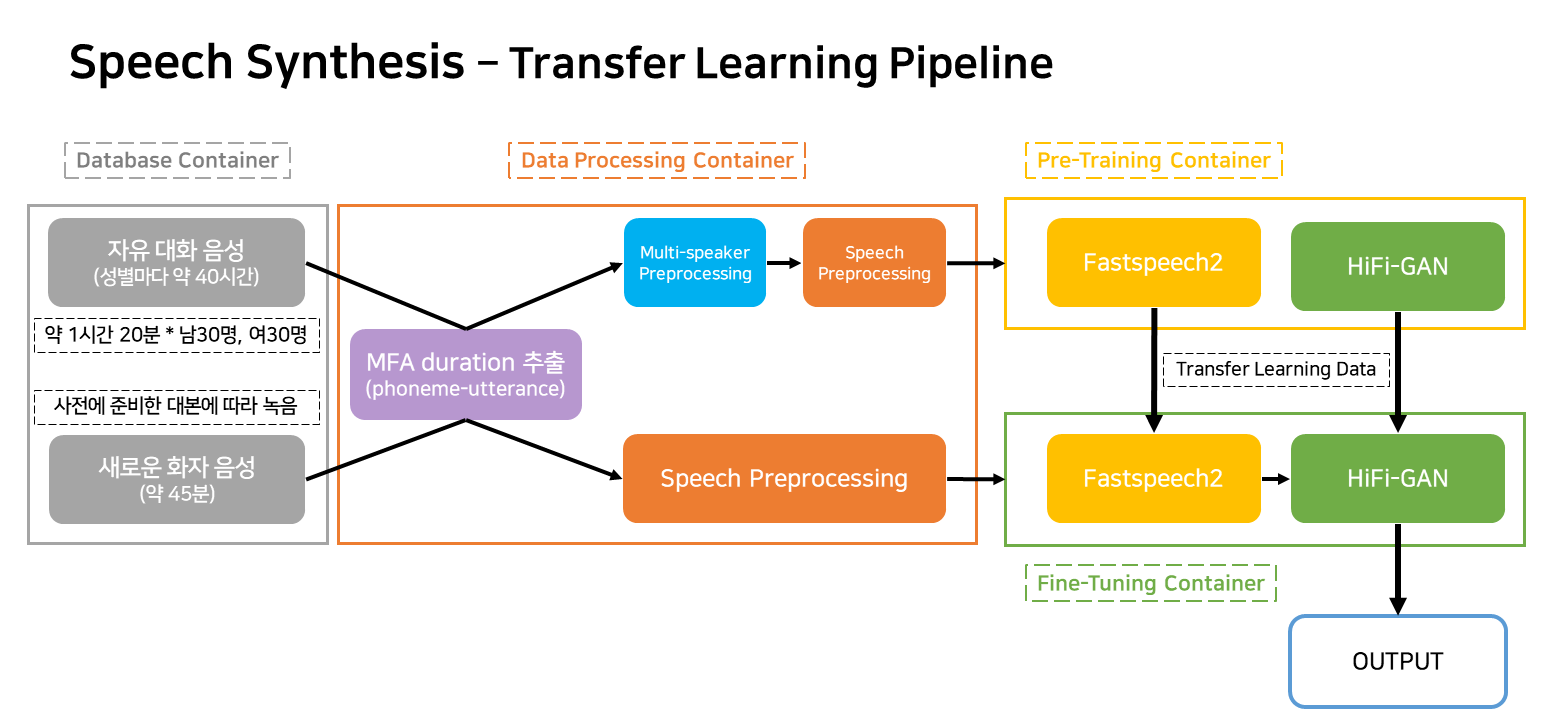
Los contenedores se clasifican en gran medida como cuatro.
En la situación del servicio real, solo tres contenedores funcionarán.


