FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
โครงการนี้ดำเนินการใน TTS หลายลำโพงเกาหลีโดยการรวม Hifi-Gan Vocoder เข้ากับ FastSpeech2
โครงการนี้มีวัตถุประสงค์ เพื่อพัฒนา TTS ของโครงการ 'ลำโพง AI ที่เป็นส่วนตัวที่มองเห็นได้' มันถูกแทนที่ด้วยเสียงของผู้คนรอบตัวที่คุณต้องการมากกว่าเสียงของ 'Siri', 'Bixby' และ 'Ari' (เช่นคู่สมรสลูกชายลูกสาวพ่อแม่ ฯลฯ )
เพื่อที่จะรับมือกับการผลิตลำโพง AI ทันทีแทนที่จะเป็นประสิทธิภาพที่ยอดเยี่ยมของ Tacotron2 และ Waveglow, Hifi-Gan ที่ ไม่ได้ใช้งานจริง และไม่ได้รับการฝึกฝน
ขึ้นอยู่กับซอร์สโค้ด FastSpeech2 ที่สอดคล้องกับชุดข้อมูล KSS ของเกาหลีที่ใช้ใน DLLAB
เนื้อหาที่เพิ่มเข้ามาในรหัสที่ใช้มีดังนี้
การใช้งาน Embedding Speaker (เกาหลีหลายลำโพง FastSpeech2)
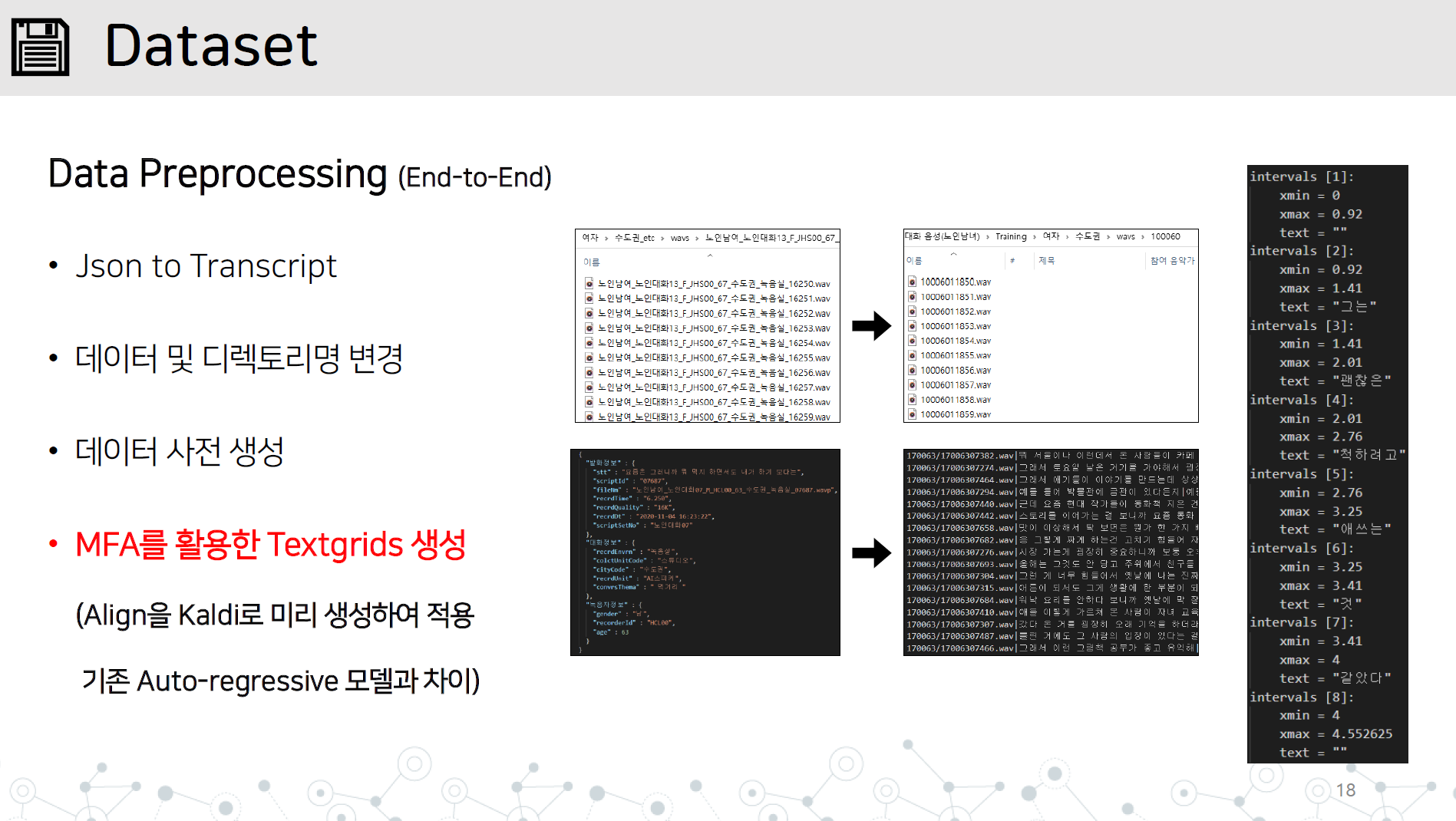
data_preprocessing.py-end-to-end การปรับสภาพการปรับสภาพข้อมูลที่มีรายการทั้งหมดด้านล่าง
การตอบสนองต่อการสังเคราะห์ประโยคยาวที่ไม่เสถียร

การนำเข้าซอร์สโค้ด G2PK และใช้ตัวเลขและภาษาอังกฤษเท่านั้น
บันทึกไดเร็กทอรี WAV และ JSON หรือไฟล์การถอดเสียงในไดเรกทอรีชุดข้อมูล/ชื่อข้อมูลดังที่แสดง
เรียนรู้ Montral Forced Alinger ใน Kaldi เพื่อเรียนรู้ TextGrid โดยการเรียนรู้ข้อมูลเสียง
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
บันทึกเครื่องกำเนิดไฟฟ้าที่เรียนรู้โดย Hifi-Gan สำหรับการประเมินผลระหว่างการเรียนรู้ในไดเรกทอรี Vocoder/Pretained_Models
ตั้งค่าเส้นทางของขนาดแบทช์ของ hparam.py เครื่องกำเนิดไฟฟ้า hifi-gan และเริ่มเรียนรู้
python train.py
หากคุณกำลังศึกษาอยู่คุณสามารถเรียนรู้ได้โดยการเพิ่ม Restore_step
python train.py --restore_step [step]
หากคุณดำเนินการก่อนรถไฟสำหรับหลายลำโพง Storage Speaker_info.json ที่สร้างขึ้นโดยอัตโนมัติในระหว่างการเรียนรู้ก่อนรถไฟ
ใส่ Speaker_info.json ที่ด้านบนของไดเรกทอรี
Run Python ในลักษณะเดียวกับการศึกษาในรถไฟ
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
ไปป์ไลน์นี้เป็นไปป์ไลน์โฟลว์สำหรับการเรียนรู้และการสร้าง TTS ที่สอดคล้องกับบริการ
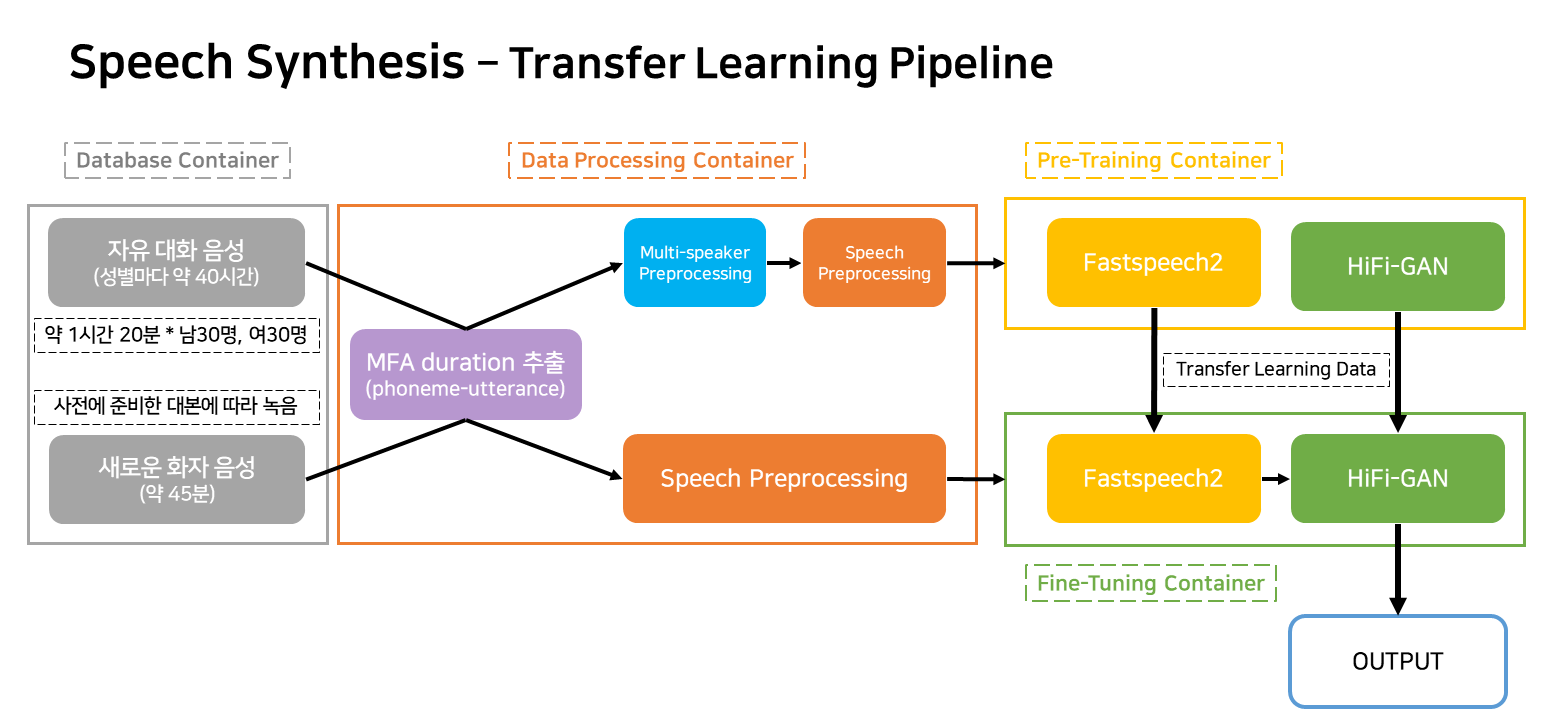
ภาชนะบรรจุส่วนใหญ่จัดเป็นสี่
ในสถานการณ์การให้บริการจริงมีเพียงสามคอนเทนเนอร์เท่านั้นที่จะทำงานได้


