FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
このプロジェクトは、Hifi-Gan VocoderとFastSpeech2を組み合わせることにより、韓国のマルチスピーカーTTSに実装されます。
このプロジェクトは、「目に見えるパーソナライズされたAIスピーカー」プロジェクトのTTSを開発することを目的としています。 「Siri」、「Bixby」、「Ari」の声ではなく、あなたの周りの人々の声に置き換えられます。 (例:配偶者、息子、娘、両親など)
AIスピーカーの即時生産に対処するために、Tacotron2とWaveglowの優れたパフォーマンスの代わりに、非自己網目上のMostSpeech2およびGanベースのボコーダーモデルHifi-Ganが品質と生産速度の両方を採用しました。
dllabに実装されている韓国のデータセットKSSに対応するFastSpeech2ソースコードに基づいています。
使用されるコードに追加されたコンテンツは次のとおりです。
スピーカーの埋め込み実装(韓国のマルチスピーカーFastSpeech2)
data_preprocessing.py-エンドのデータ以下のすべての項目を含む前処理前処理実装
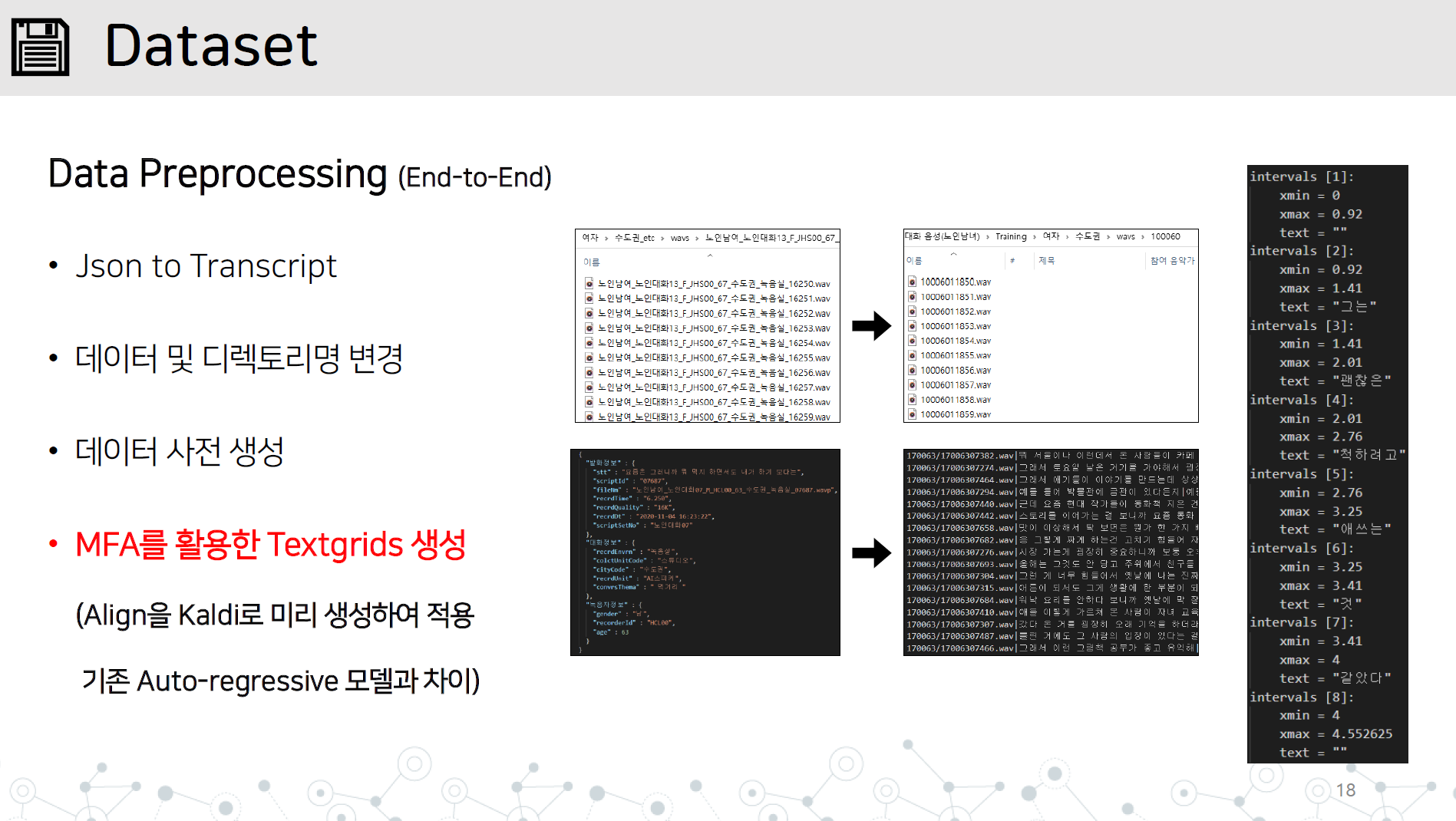
長い文の不安定な統合に対する応答

G2PKソースコードをインポートし、数字と英語のみを適用する
図のように、データセット/データ名ディレクトリにWAVディレクトリとJSONまたは転写ファイルを保存します。
カルディのモントラルの強制的なアリンジャーを学び、オーディオデータを学習してテキストグリッドを学習します。
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
Vocoder/Presed_modelsディレクトリでの学習中に評価のためにHifi-Ganが学んだ発電機を保存します。
hparam.pyのバッチサイズ、hifi-ganジェネレーターのパスをセットアップし、学習を開始します。
python train.py
勉強している場合は、Restore_Stepを追加することで学ぶことができます。
python train.py --restore_step [step]
マルチスピーカーのプレトレインを実行すると、トレイン前の学習中にストレージスピーカー_info.jsonが自動的に生成されます
Speaker_info.jsonをディレクトリの上部に置きます
電車で学習を行うのと同じようにPythonを実行する
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
このパイプラインは、サービスに対応するTTS学習と作成のためのフローパイプラインです。
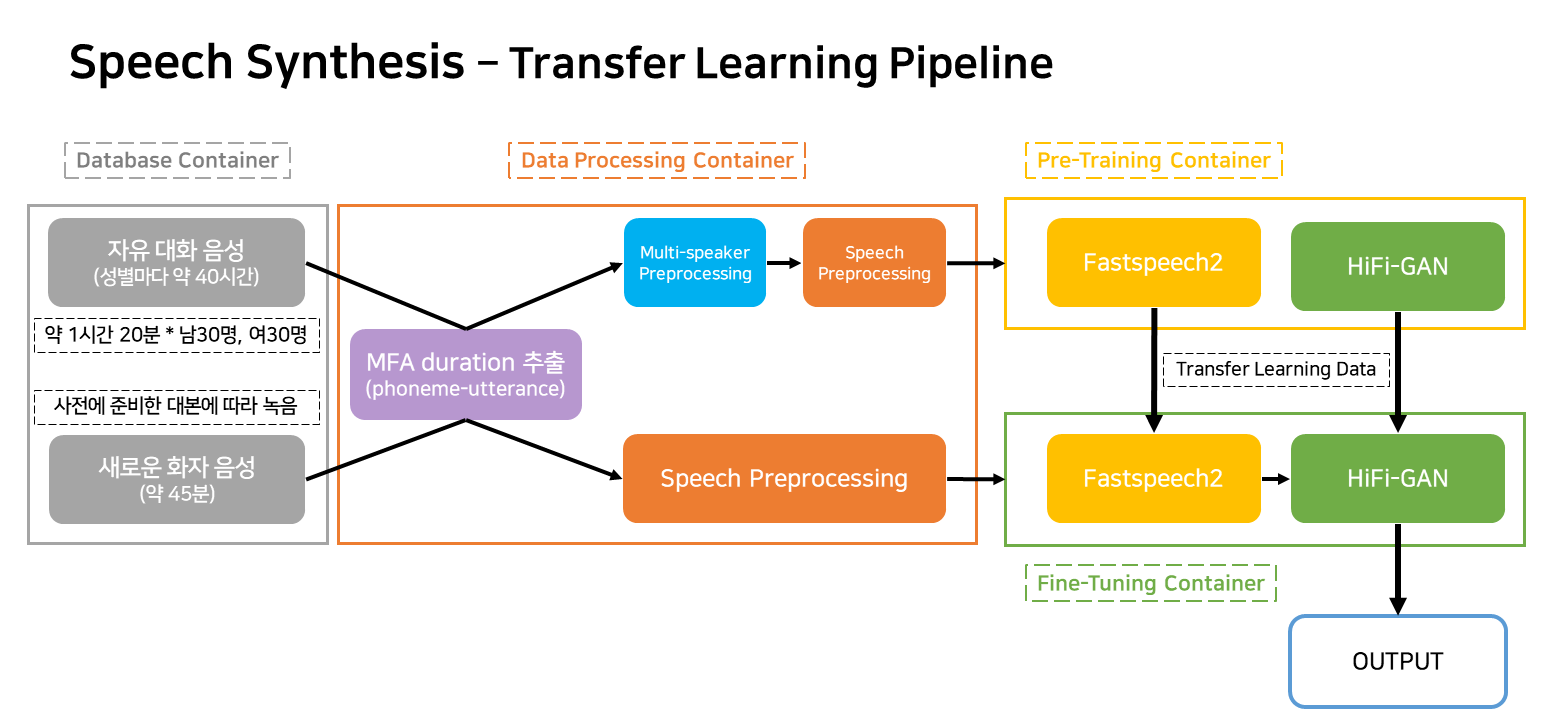
コンテナは、主に4つに分類されます。
実際のサービス状況では、3つのコンテナのみが機能します。


