FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
Ce projet est mis en œuvre dans des TTS multi-pardeurs coréens en combinant HIFI-GoNODER avec FastSpeech2.
Ce projet vise à développer le TTS du projet «Visible personnalisé AI Speaker» . Il est remplacé par les voix des gens autour de vous, plutôt que par les voix de «Siri», «Bixby» et «Ari». (Ex. Conjoint, fils, fille, parents, etc.)
Afin de faire face à la production immédiate des haut-parleurs d'IA, au lieu d'excellentes performances de Tacotron2 et de lubrification des vagues, le modèle de vocoder Mostoregressitif Mostoregressitif et le modèle de vocodeur GAN, HIFI-GAN, a adopté la qualité et la vitesse de production.
Basé sur le code source FastSpeech2 qui correspond à l'ensemble de données coréen KSS implémenté dans DLLAB.
Le contenu ajouté dans le code utilisé est le suivant.
Implémentation de l'intégration des conférenciers (FastSpeech Multi-Speaker coréen)
Data_preprocessing.py-end-end-end data prétraitement implémentation contenant tous les éléments ci-dessous
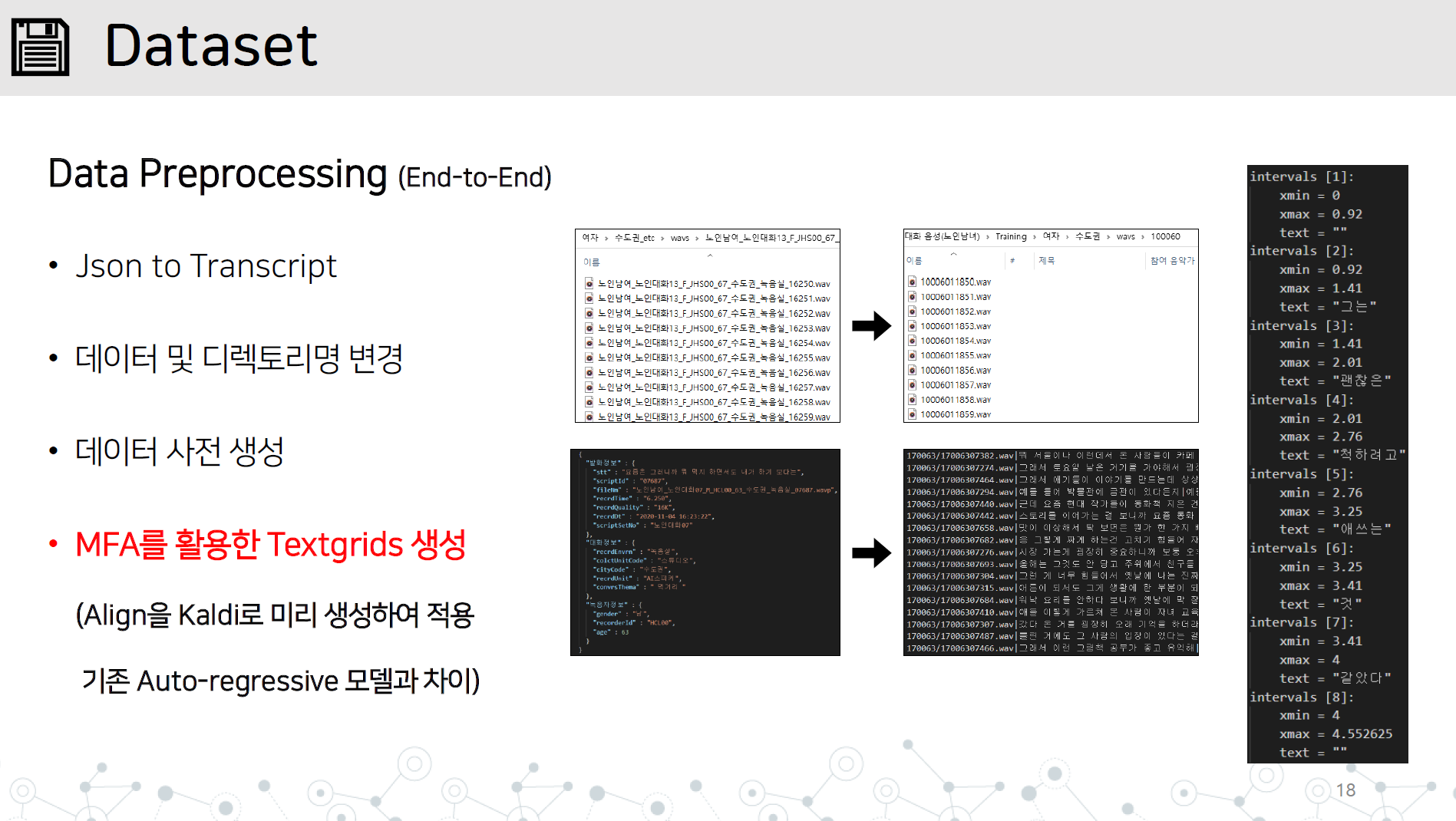
Réponse à la synthèse instable de phrases longues

Importation du code source G2PK et appliquant uniquement les nombres et l'anglais
Enregistrez le répertoire WAV et le fichier JSON ou Transcript dans le répertoire de jeu de données / nom de données comme indiqué.
Apprenez Montral a forcé Alinger à Kaldi à apprendre TextGrid en apprenant les données audio.
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
Enregistrez le générateur appris par HiFI-AG pour l'évaluation lors de l'apprentissage dans le répertoire Vocoder / Preteen_Models.
Configurez le chemin de la taille du lot de Hparam.py, du générateur Hifi-Agan et commencez à apprendre.
python train.py
Si vous étudiez, vous pouvez apprendre en ajoutant Restore_step.
python train.py --restore_step [step]
Si vous effectuez un pré-train pour le multi-orage, le stockage Speaker_info.json généré automatiquement pendant l'apprentissage pré-train
Mettez Speaker_info.json en haut du répertoire
Exécutez Python de la même manière que la réalisation d'une étude dans le train
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
Ce pipeline est un pipeline de flux pour l'apprentissage et la création TTS qui correspond au service.
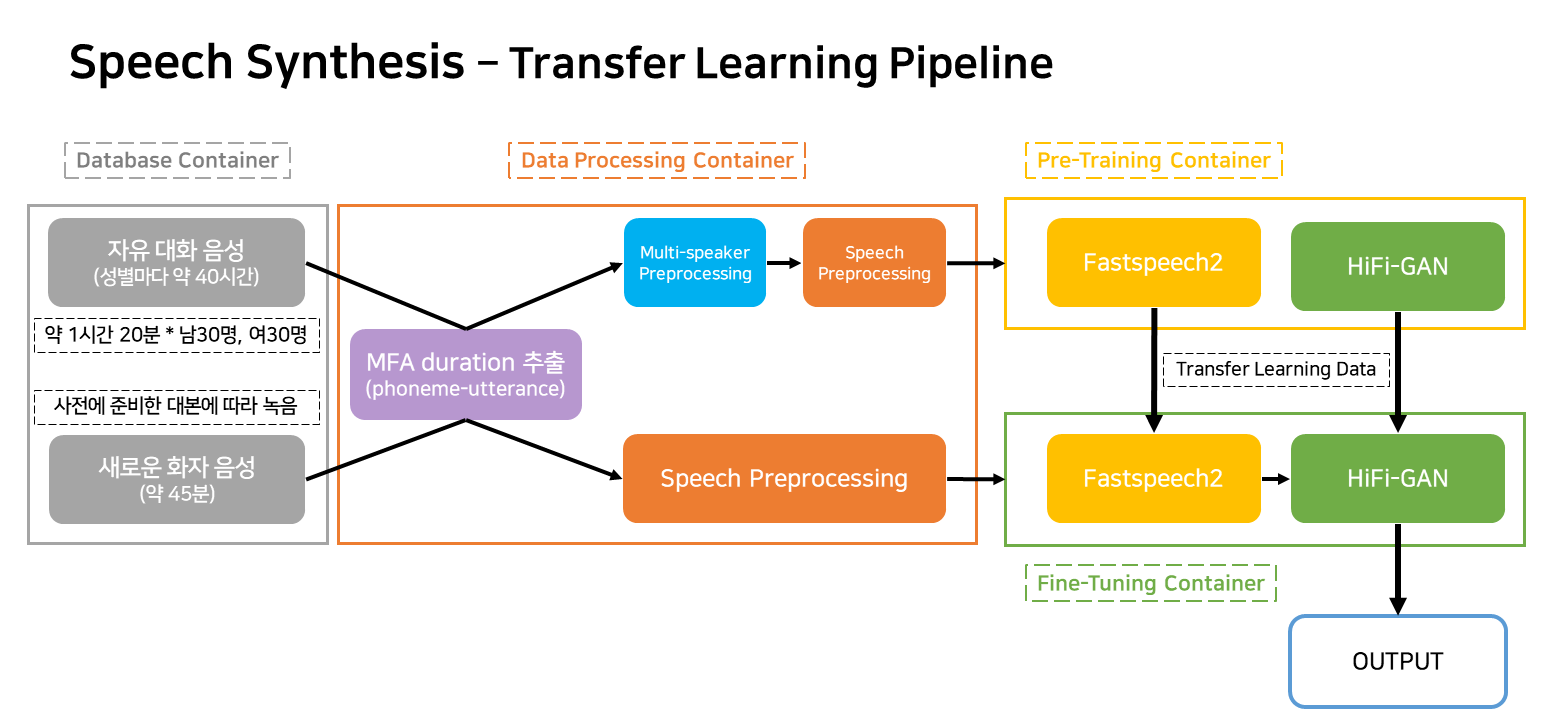
Les conteneurs sont largement classés comme quatre.
Dans la situation de service réelle, seuls trois conteneurs fonctionneront.


