FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
Dieses Projekt wird in koreanischen Multi-Sprecher-TTs durch Kombination von Hifi-Gan-Vocoder mit Fastspeech2 implementiert.
Dieses Projekt zielt darauf ab , die TTs des „sichtbaren personalisierten KI -Sprechers“ -Projekts zu entwickeln . Es wird eher durch die Stimmen der Menschen um Sie herum ersetzt und nicht durch die Stimmen von "Siri", "Bixby" und "Ari". (Bsp. Ehepartner, Sohn, Tochter, Eltern usw.)
Um mit der sofortigen Produktion von KI-Lautsprechern umzugehen, anstatt die hervorragende Leistung von Tacotron2 und Waveglow, übernahm nicht autoregressitiver Mostspeech2- und GaN-basierter Vocoder-Modell Hifi -gan sowohl Qualität als auch Produktionsgeschwindigkeit in Betracht.
Basierend auf dem FastSpeech2 -Quellcode, der dem koreanischen Datensatz KSS entspricht, der in Dlllab implementiert ist.
Der hinzugefügte Inhalt im verwendeten Code lautet wie folgt.
Implementierung der Sprecherbettung (Koreanische Multi-Sprecher-Fastspeech2)
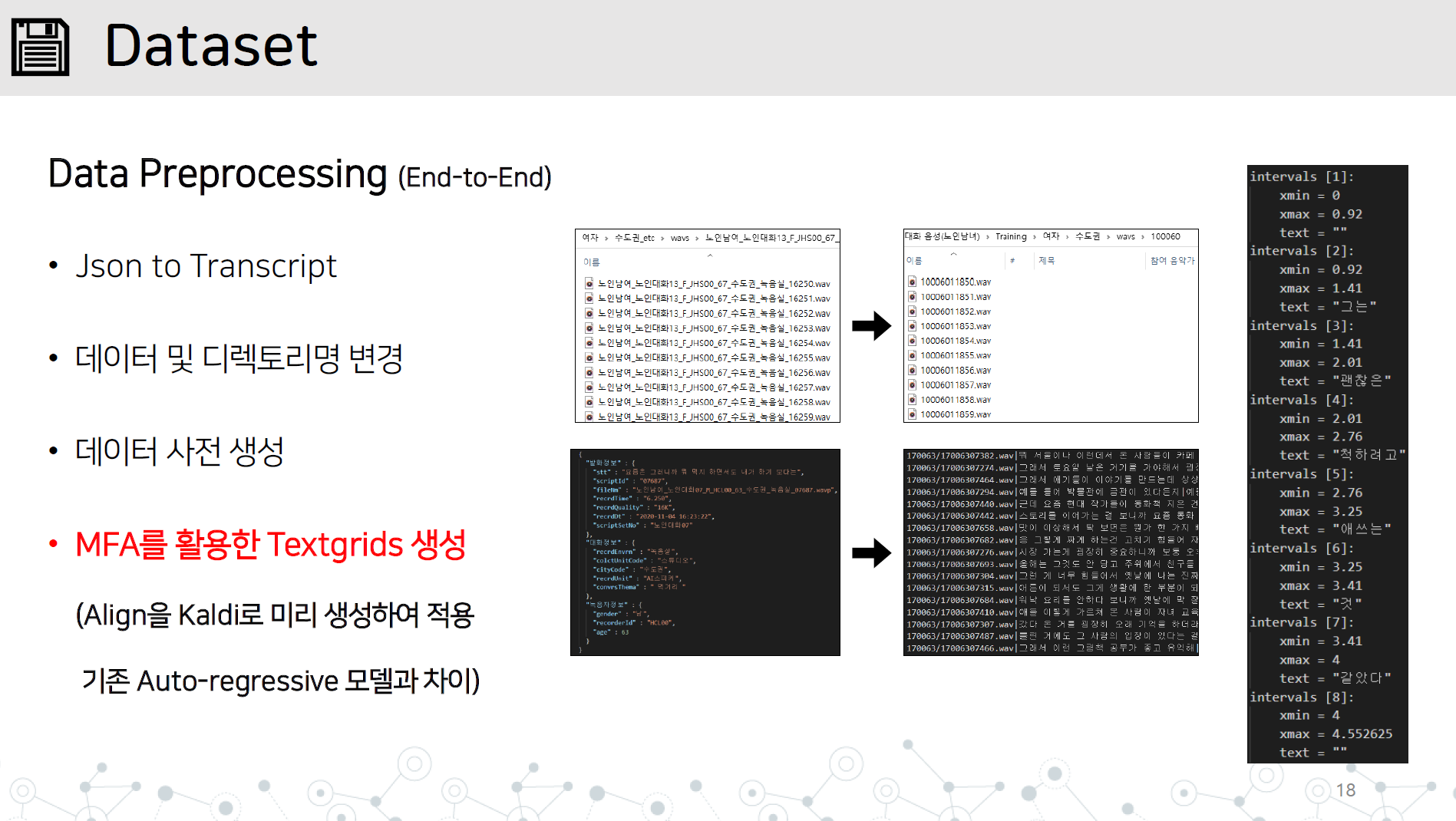
Data_Proprocessing.py-End-to-End-Datenvorbehandlungsimplementierung, die alle folgenden Elemente enthalten
Reaktion auf instabile Synthese langer Sätze

Importieren von G2PK -Quellcode und Anwendung von nur Zahlen und Englisch
Speichern Sie das WAV -Verzeichnis und die JSON- oder Transkript -Datei im Verzeichnis Datensatz/Datenname, wie gezeigt.
Lernen Sie Montral, der Alinger in Kaldi gezwungen hat, TextGrid durch Lernen von Audiodaten zu lernen.
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
Speichern Sie den von Hifi -gan gelernten Generator für die Bewertung während des Lernens im Vocoder/Pretierten_Models-Verzeichnis.
Richten Sie den Pfad von Hparam.Pys Chargengröße, Hifi-Gan-Generator ein und beginnen Sie zu lernen.
python train.py
Wenn Sie studieren, können Sie lernen, indem Sie restore_step hinzufügen.
python train.py --restore_step [step]
Wenn Sie Pre-Training für Multi-Sprecher durchführen, hat Speicherlautsprecher_info.json beim Lernen vor dem Training automatisch generiert
Setzen Sie Lautsprecher_info.json an die Spitze des Verzeichnisses
Führen Sie Python auf die gleiche Weise wie eine Studie im Zug durch
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
Diese Pipeline ist eine Flow -Pipeline für das TTS -Lernen und die Erstellung, die dem Dienst entspricht.
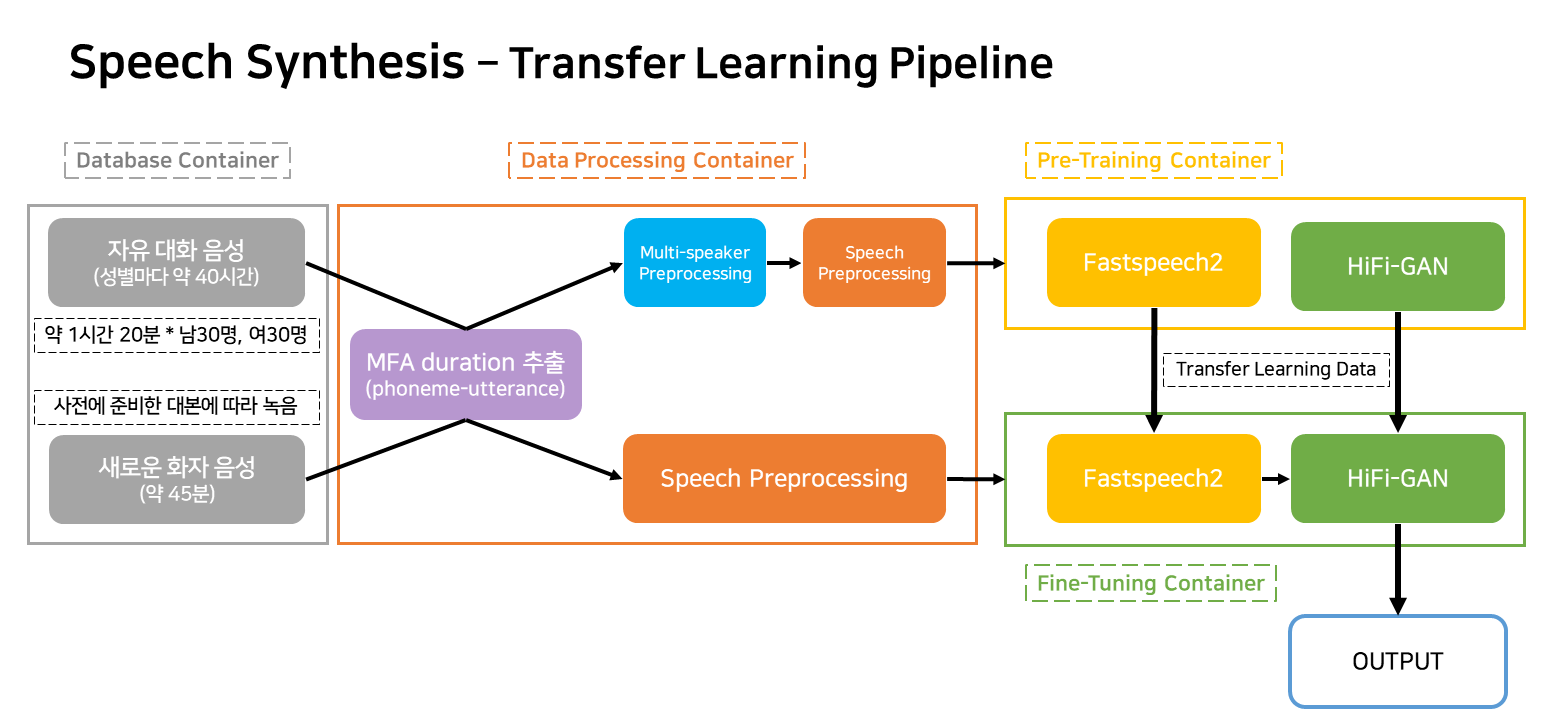
Die Behälter sind größtenteils als vier eingestuft.
In der tatsächlichen Servicesituation funktionieren nur drei Container.


