FastSpeech2 Pytorch Korean Multi Speaker
1.0.0
Este projeto é implementado no TTS multi-falante coreano, combinando vocoder Hifi-Gan com o FastSpeech2.
Este projeto tem como objetivo desenvolver o TTS do projeto 'Visible Personalizado AI' . É substituído pelas vozes das pessoas ao seu redor querem, em vez das vozes de 'Siri', 'Bixby' e 'Ari'. (Ex. Cônjuge, filho, filha, pais, etc.)
Para lidar com a produção imediata de alto-falantes de IA, em vez de excelente desempenho de Tacotron2 e Glow Wave, o modelo de vocoder MostSpeech2 e não autorregressivo e o modelo de vocoder com sede em GaN adotou a velocidade de qualidade e produção.
Com base no código -fonte do FastSpeech2 que corresponde ao conjunto de dados coreano KSS implementado no DLLab.
O conteúdo adicionado no código usado é o seguinte.
Implementação de incorporação de alto-falante (coreano multi-falante FastSpeech2)
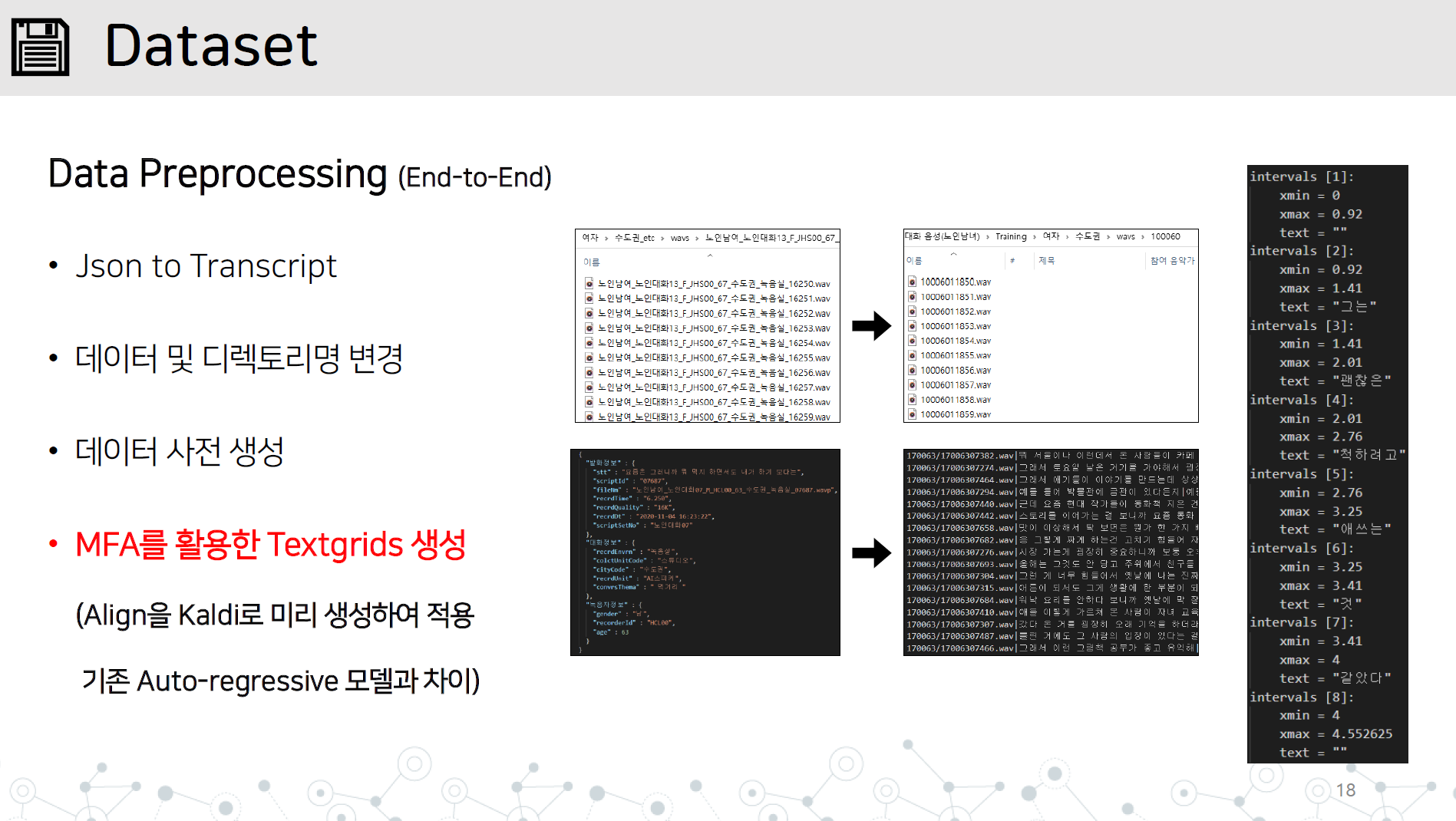
Data_Preprocessing.py-End-to-end Data Pré-tratamento de implementação contendo todos os itens abaixo
Resposta à síntese instável de frases longas

Importar código -fonte G2PK e aplicar apenas números e inglês
Salve o diretório WAV e o arquivo JSON ou Transcript no diretório de nomes de dados/dados, conforme mostrado.
Aprenda Montral forçou Alinger em Kaldi a aprender TextGrid , aprendendo dados de áudio.
# lab 생성, mfa 학습, lab 분리
python data_preprocessing.py
Salve o gerador aprendido pelo HIFI-GAN para avaliação durante o aprendizado no diretório Vocoder/Preteden_models.
Configure o caminho do tamanho do lote do HPARAM.PY, o gerador HIFI-GAN e comece a aprender.
python train.py
Se você estiver estudando, pode aprender adicionando RESTORE_STEP.
python train.py --restore_step [step]
Se você executar pré-trem para multi-falantes, o armazenamento de armazenamento_info.json gerou automaticamente durante o aprendizado pré-trep
Coloque o Speaker_info.json no topo do diretório
Execute Python da mesma maneira que realizar um estudo em trem
python train.py --restore_step [pre-train의 step]
python synthesize.py --step [step수]
Este pipeline é um pipeline de fluxo para o aprendizado e a criação do TTS que corresponde ao serviço.
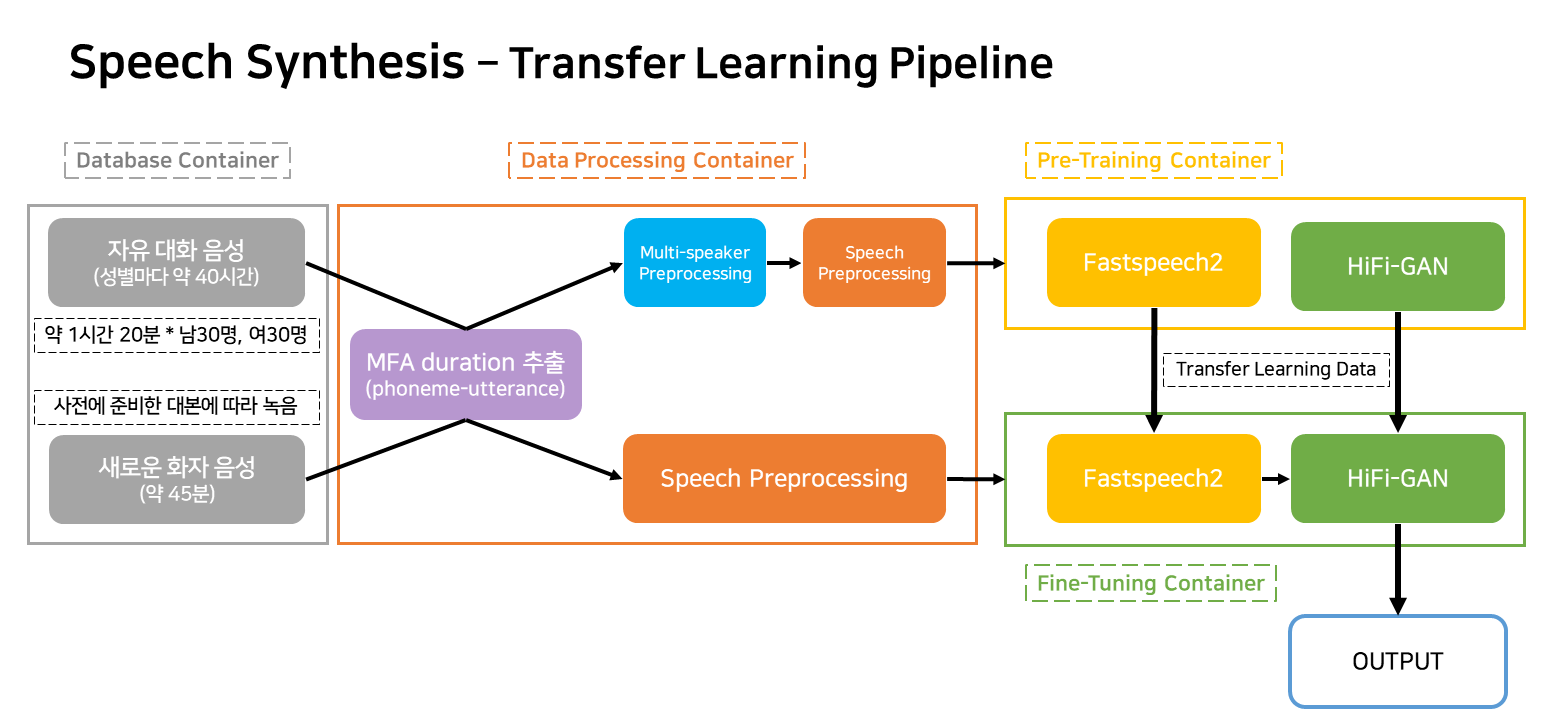
Os contêineres são amplamente classificados como quatro.
Na situação real do serviço, apenas três contêineres funcionarão.


