tf diffwave
ve: channels=64, T=20, 1M steps
(非官方)diffwave的张力实现(Zhifeng Kong等,2020)
在Python 3.7.3 Conda环境中测试,需求.txt
要下载LJ-Speech数据集,请在脚本下运行。
数据集将以tfrecord格式以'〜/tensorflow_datasets下载。如果要更改下载目录,请指定LJSpeech初始化器的data_dir参数。
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) 要训练型号,请运行train.py。
CheckPoint将写在TrainConfig.ckpt上,张量板摘要上的TrainConfig.log 。
python train.py
tensorboard --logdir ./log/如果您想从RAW AUDIO训练模型,请指定音频目录并打开标志--from-raw 。
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw为了开始从以前的检查点进行训练,可以使用--load-step 。
python . t rain.py --load-step 416 --config ./ckpt/q1.json对于实验,参考expr.ipynb。
转换测试集,运行推荐。
python . i nference.py预处理的检查站将在版本上重新介绍。
要使用预估计的模型,请下载文件并解压缩。结帐git存储库适当的提交标签和以下是示例脚本。
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()Res.Channels = 64,T = 20,火车1M步。
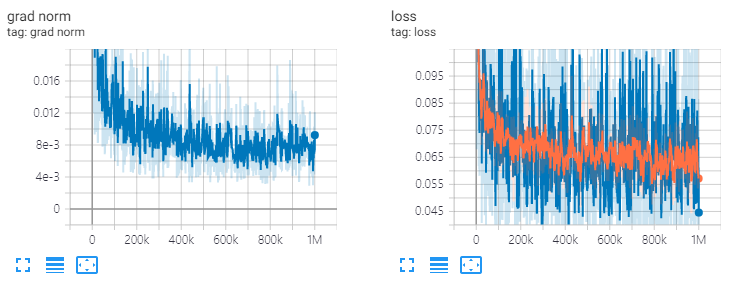
参考https://revsic.github.io/tf-diffwave。


