tf diffwave
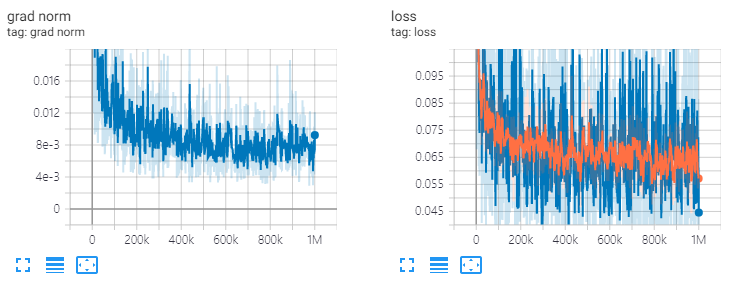
ve: channels=64, T=20, 1M steps
(Неофициальная) Тенорфлоу реализация Diffwave (Zhifeng Kong et al., 2020)
Протестировано в Python 3.7.3 Conda Environment, TEDIP.TXT
Чтобы загрузить набор данных LJ-Speech, запустите под скриптом.
Набор данных будет загружен в '~/tensorflow_datasets' в формате tfrecord. Если вы хотите изменить каталог загрузки, укажите параметр data_dir инициализатора LJSpeech .
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) Чтобы тренировать модель, запустите Train.py.
Контрольная точка будет записана на TrainConfig.ckpt , резюме Tensorboard на TrainConfig.log .
python train.py
tensorboard --logdir ./log/ Если вы хотите тренировать модель из Raw Audio, укажите аудио-каталог и включите флаг --from-raw .
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw Чтобы начать тренироваться с предыдущей контрольно-пропускной пункты, доступен --load-step .
python . t rain.py --load-step 416 --config ./ckpt/q1.jsonДля экспериментов, эталонный expr.ipynb.
Для вывода набор тестов, запустите anupect.py.
python . i nference.pyПредварительные контрольно -пропускные пункты рецидивируются на выпусках.
Чтобы использовать предварительную модель, загрузите файлы и разкачивайте ее. Оформление репозитория GIT для правильных тегов коммита и последователей является примером сценария.
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()res.channels = 64, t = 20, поезд 1M шагов.
Ссылка https://revsic.github.io/tf-diffwave.


