tf diffwave
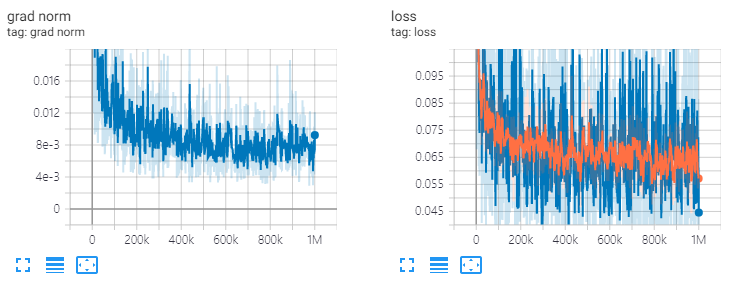
ve: channels=64, T=20, 1M steps
(非公式)DiffwaveのTensorflow実装(Zhifeng Kong et al。、2020)
Python 3.7.3 Conda Environment、Recomations.txtでテストされています
LJスピーチデータセットをダウンロードするには、スクリプトの下で実行します。
データセットは、tfrecord形式で「〜/tensorflow_datasets」でダウンロードされます。ダウンロードディレクトリを変更する場合は、 LJSpeech initializerのdata_dirパラメーターを指定します。
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) モデルをトレーニングするには、train.pyを実行します。
チェックポイントは、 TrainConfig.ckpt 、 TrainConfig.logのテンソルボードの概要に記述されます。
python train.py
tensorboard --logdir ./log/ RAWオーディオからモデルをトレーニングする場合は、オーディオディレクトリを指定し、フラグをオンにします--from-raw 。
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw以前のチェックポイントからトレーニングを開始するには、 --load-stepが利用可能です。
python . t rain.py --load-step 416 --config ./ckpt/q1.json実験の場合、参照expr.ipynb。
推論テストセットに、inderence.pyを実行します。
python . i nference.py事前に保護されたチェックポイントは、リリースに関連しています。
前処理されたモデルを使用するには、ファイルをダウンロードして解凍します。適切なコミットタグとフォローへのgitリポジトリをチェックアウトします。サンプルスクリプトです。
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()Res.Channels = 64、t = 20、列車1mステップ。
参照https://revsic.github.io/tf-diffwave。


