tf diffwave
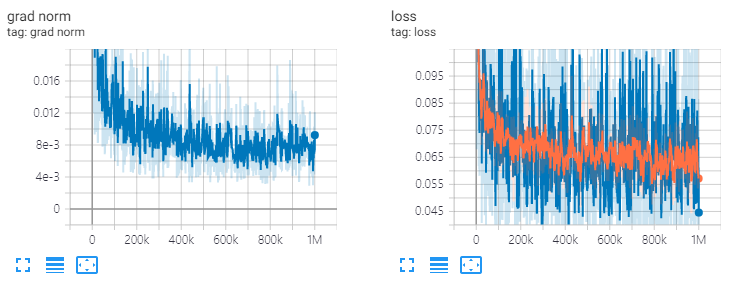
ve: channels=64, T=20, 1M steps
(Non officiel) Implémentation de tenorflow de diffs (Zhifeng Kong et al., 2020)
Testé dans Python 3.7.3 Conda Environnement, exigences.txt
Pour télécharger le jeu de données LJ-Speech, exécutez sous Script.
L'ensemble de données sera téléchargé dans «~ / Tensorflow_datasets» au format tfrecord. Si vous souhaitez modifier le répertoire de téléchargement, spécifiez le paramètre data_dir de l'initialisateur LJSpeech .
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) Pour entraîner le modèle, exécutez Train.py.
Le point de contrôle sera écrit sur TrainConfig.ckpt , Tensorboard Résumé sur TrainConfig.log .
python train.py
tensorboard --logdir ./log/ Si vous souhaitez former le modèle à partir de RAW Audio, spécifiez le répertoire audio et activez l'indicateur --from-raw .
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw Pour commencer à s'entraîner à partir du point de contrôle précédent, --load-step est disponible.
python . t rain.py --load-step 416 --config ./ckpt/q1.jsonPour les expériences, référence expr.ipynb.
Pour le jeu de test d'inférence, exécutez Inference.py.
python . i nference.pyLes points de contrôle pré-entraînés sont relancés sur les versions.
Pour utiliser le modèle pré-entraîné, téléchargez des fichiers et décompressez-le. Découvrez le référentiel GIT vers des balises de validation appropriées et les suivants sont un exemple de script.
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()Res.Channels = 64, t = 20, Train 1M étapes.
Référence https://revsic.github.io/tf-diffwave.


