tf diffwave
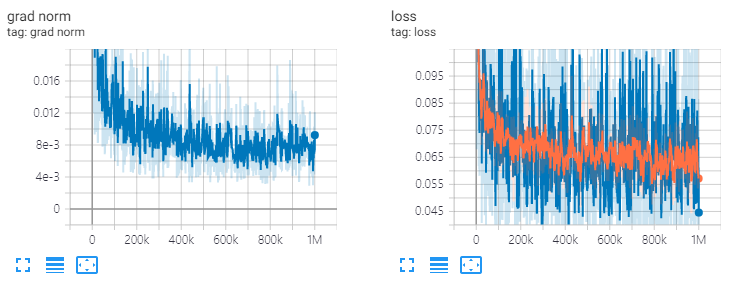
ve: channels=64, T=20, 1M steps
(Tidak resmi) Implementasi TensorFlow dari DiffWave (Zhifeng Kong et al., 2020)
Diuji di Python 3.7.3 Lingkungan Conda, Persyaratan.txt
Untuk mengunduh dataset LJ-Speech, jalankan di bawah skrip.
Dataset akan diunduh di '~/tensorflow_datasets' dalam format tfrecord. Jika Anda ingin mengubah direktori unduhan, tentukan parameter data_dir dari LJSpeech initializer.
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) Untuk melatih model, jalankan train.py.
Pos pemeriksaan akan ditulis di TrainConfig.ckpt , ringkasan Tensorboard di TrainConfig.log .
python train.py
tensorboard --logdir ./log/ Jika Anda ingin melatih model dari Audio Raw, tentukan Audio Directory dan nyalakan bendera --from-raw .
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw Untuk mulai berlatih dari pos pemeriksaan sebelumnya, --load-step tersedia.
python . t rain.py --load-step 416 --config ./ckpt/q1.jsonUntuk percobaan, referensi Expr.ipynb.
Untuk set tes inferensi, jalankan inference.py.
python . i nference.pyPos pemeriksaan pretrain dirilis pada rilis.
Untuk menggunakan model pretrained, unduh file dan unzip. CHECKOUT GIT Repository ke tag dan pengikut komit yang tepat adalah skrip sampel.
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()res.channels = 64, t = 20, latih 1 m langkah.
Referensi https://revsic.github.io/tf-diffwave.


