tf diffwave
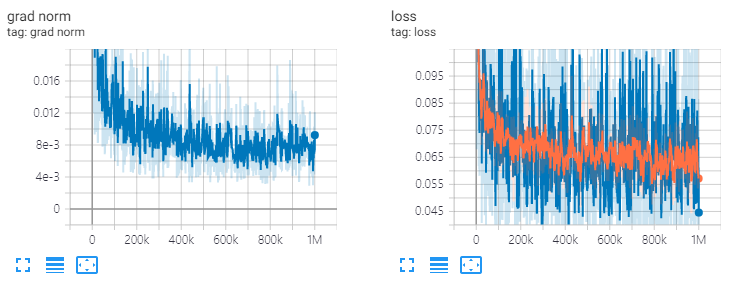
ve: channels=64, T=20, 1M steps
(ไม่เป็นทางการ) การใช้ Tensorflow ของ Diffwave (Zhifeng Kong et al., 2020)
ทดสอบใน Python 3.7.3 สภาพแวดล้อม conda, required.txt
หากต้องการดาวน์โหลดชุดข้อมูล LJ-Speech ให้เรียกใช้ภายใต้สคริปต์
ชุดข้อมูลจะถูกดาวน์โหลดใน '~/tensorflow_datasets' ในรูปแบบ tfrecord หากคุณต้องการเปลี่ยนไดเรกทอรีดาวน์โหลดให้ระบุพารามิเตอร์ data_dir ของ LJSpeech initializer
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) ในการฝึกอบรมนางแบบ Run Train.py
จุดตรวจสอบจะถูกเขียนบน TrainConfig.ckpt , Tensorboard สรุปเกี่ยวกับ TrainConfig.log
python train.py
tensorboard --logdir ./log/ หากคุณต้องการฝึกอบรมโมเดลจาก RAW Audio ให้ระบุไดเรกทอรีเสียงและเปิดการตั้งค่าสถานะ --from-raw
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw ในการเริ่มฝึกอบรมจากจุดตรวจสอบก่อนหน้านี้ --load-step
python . t rain.py --load-step 416 --config ./ckpt/q1.jsonสำหรับการทดลองอ้างอิง expr.ipynb
ในการทดสอบการอนุมานให้เรียกใช้การอนุมาน.py
python . i nference.pyจุดตรวจสอบที่ได้รับการฝึกฝนจะถูกเชื่อมต่อกันในรุ่น
หากต้องการใช้โมเดล pretrained ดาวน์โหลดไฟล์และคลายซิป Checkout Git ที่เก็บไปยังแท็กการกระทำที่เหมาะสมและการติดตามเป็นสคริปต์ตัวอย่าง
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()Res.Channels = 64, T = 20, รถไฟ 1M ขั้นตอน
อ้างอิง https://revsic.github.io/tf-diffwave


