tf diffwave
ve: channels=64, T=20, 1M steps
(비공식) Diffwave의 텐서 플로 구현 (Zhifeng Kong et al., 2020)
Python 3.7.3 Conda 환경, 요구 사항 .txt에서 테스트
lj-speech 데이터 세트를 다운로드하려면 스크립트에서 실행하십시오.
데이터 세트는 '~/tensorflow_datasets'로 tfrecord 형식으로 다운로드됩니다. 다운로드 디렉토리를 변경하려면 LJSpeech 이니셜 라이저의 data_dir 매개 변수를 지정하십시오.
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) 모델을 훈련 시키려면 Train.py를 실행하십시오.
Checkpoint는 TrainConfig.ckpt , Tensorboard TrainConfig.log 에 작성됩니다.
python train.py
tensorboard --logdir ./log/ Raw Audio에서 모델을 훈련 시키려면 오디오 디렉토리를 지정하고 --from-raw 을 켜십시오.
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw 이전 체크 포인트에서 훈련을 시작하려면 --load-step 사용할 수 있습니다.
python . t rain.py --load-step 416 --config ./ckpt/q1.json실험의 경우 expr.ipynb를 참조하십시오.
추론 테스트 세트를 위해 unference.py를 실행하십시오.
python . i nference.py사전 조정 체크 포인트는 릴리스에 상관됩니다.
사전 치료 된 모델을 사용하려면 파일을 다운로드하고 압축을 풀습니다. 적절한 커밋 태그와 팔로워에 대한 git 리포지토리 체크 아웃은 샘플 스크립트입니다.
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()RES.CHANNELS = 64, T = 20, 1m 단계를 기차하십시오.
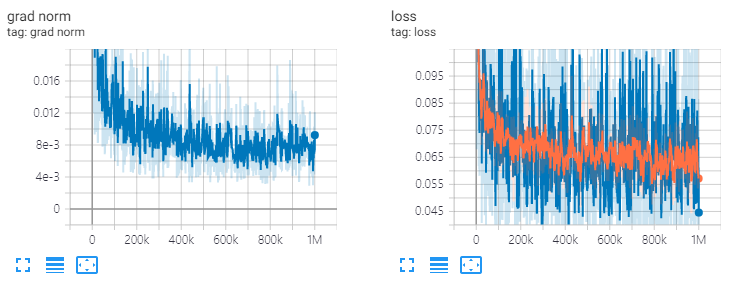
참조 https://revsic.github.io/tf-diffwave.


