tf diffwave
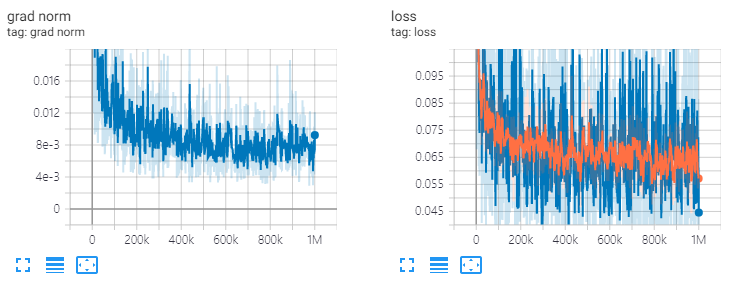
ve: channels=64, T=20, 1M steps
(Não oficial) Implementação do TensorFlow de Diffwave (Zhifeng Kong et al., 2020)
Testado em Python 3.7.3 Ambiente do CONDA, requisitos.txt
Para baixar o conjunto de dados de LJ-Speech, execute no script.
O conjunto de dados será baixado em '~/tensorflow_datasets' no formato tfrecord. Se você deseja alterar o diretório de download, especifique o parâmetro data_dir do Initializador LJSpeech .
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) Para treinar o modelo, execute o trem.py.
O ponto de verificação será escrito em TrainConfig.ckpt , resumo do Tensorboard no TrainConfig.log .
python train.py
tensorboard --logdir ./log/ Se você deseja treinar o modelo a partir do áudio bruto, especifique o diretório de áudio e ligue a bandeira --from-raw .
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw Para começar a treinar do ponto de verificação anterior, --load-step está disponível.
python . t rain.py --load-step 416 --config ./ckpt/q1.jsonPara experimentos, referência expr.ipynb.
Para o conjunto de testes de inferência, execute inference.py.
python . i nference.pyOs pontos de verificação pré -rastreados são relatados nos lançamentos.
Para usar o modelo pré -terenciado, faça o download de arquivos e descompacte -o. Repositório Git de checkout para tags e seguidores adequados são scripts de amostra.
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()Res.Cannels = 64, t = 20, trem 1M de etapas.
Referência https://revsic.github.io/tf-diffwave.


