tf diffwave
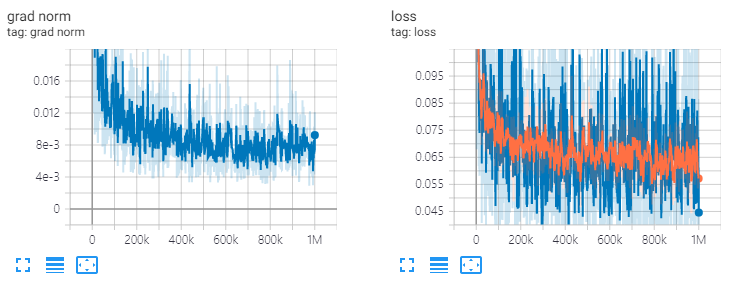
ve: channels=64, T=20, 1M steps
(Inoffizielle) Tensorflow -Implementierung von Diffwave (Zhifeng Kong et al., 2020)
Getestet in Python 3.7.3 Conda Environment, Anforderungen.txt
Um das LJ-Speech-Datensatz herunterzuladen, laufen Sie unter Skript aus.
Der Datensatz wird in '~/TensorFlow_Datasets' im TFRECORD -Format heruntergeladen. Wenn Sie das Download -Verzeichnis ändern möchten, geben Sie den Parameter data_dir von LJSpeech Initializer an.
from dataset import LJSpeech
from dataset . config import Config
config = Config ()
# lj = LJSpeech(config, data_dir=path, download=True)
lj = LJSpeech ( config , download = True ) Um das Modell zu trainieren, rennen Sie Train.py.
Der Checkpoint wird auf TrainConfig.ckpt , Tensorboard -Zusammenfassung auf TrainConfig.log geschrieben.
python train.py
tensorboard --logdir ./log/ Wenn Sie das Modell aus RAW Audio trainieren möchten, geben Sie das Audioverzeichnis an und schalten Sie das Flag ein --from-raw .
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw Um mit dem vorherigen Kontrollpunkt aus zu trainieren, ist --load-step verfügbar.
python . t rain.py --load-step 416 --config ./ckpt/q1.jsonFür Experimente referenz expr.ipynb.
Zum Inferenztestsatz rennen, inferenz.py.
python . i nference.pyVorbereitete Checkpoints werden an Veröffentlichungen bezogen.
Laden Sie Dateien herunter und entpacken Sie es, um vorgezogene Modell zu verwenden. Checkout Git -Repository zu ordnungsgemäßen Commit -Tags und Folgen sind ein Beispielskript.
with open ( 'l1.json' ) as f :
config = Config . load ( json . load ( f ))
diffwave = DiffWave ( config . model )
diffwave . restore ( './l1/l1_1000000.ckpt-1' ). expect_partial ()Res.Channels = 64, t = 20, Zug 1m Stufen.
Referenz https://revsic.github.io/tf-diffwave.


