faster rcnn.pytorch
1.0.0
[05/29/2020]该回购是大约两年前启动的,它是支持多GPU培训的第一个开源对象检测代码。它一直在整合许多人的巨大努力。但是,过去几年中,我们看到许多高质量的存储库出现了,例如:
在这一点上,我认为此存储库在管道和编码方式方面是不合时宜的,并且不会积极地保持。尽管您仍然可以将此仓库用作游乐场,但我强烈建议您转到上述存储库,以深入研究对象检测的西部世界!
该项目是更快的R-CNN的Pytorch实现,旨在加快更快的R-CNN对象检测模型的训练。最近,有许多好的实现:
rbgirshick/py-faster-rcnn,基于pycaffe + numpy开发
longcw/praster_rcnn_pytorch,基于pytorch + numpy开发
Endernewton/TF-Faster-RCNN,基于TensorFlow + Numpy开发
ruotianluo/pytorch-faster-rcnn,基于pytorch + tensorflow + numpy开发
在实施过程中,我们转介上述实现,especailly longcw/faster_rcnn_pytorch。但是,与上述实现相比,我们的实施具有几个独特的新功能:
它是纯Pytorch代码。我们将所有Numpy实现都转换为Pytorch!
它支持多图像批处理培训。我们修改了所有层,包括数据加载器,RPN,ROI-Pooling等,以支持每个Minibatch中的多个图像。
它支持多次GPU培训。我们使用多个GPU包装器(此处的nn.dataparallear)使使用一个或多个GPU的灵活性,作为上述两个功能的优点。
它支持三种合并方法。我们整合了三种合并方法:ROI POON,ROI ALIGN和ROI作物。更重要的是,我们修改了所有这些,以支持多图像批处理培训。
它是记忆效率的。我们将图像纵横比将具有相似纵横比的图像限制为MiniBatch。因此,我们可以在单个Titan X(12 GB)上使用批处理= 4(4张图像)训练Resnet101和VGG16。当使用8 GPU训练时,每个GPU的最大批次化为3(RES101),总计24。
它更快。基于上述修改,培训速度要快得多。我们在下表中报告了NVIDIA TITAN XP的训练速度。
特征金字塔网络(FPN)
面具R-CNN(正在进行Roytseng-tw已经实施)
图R-CNN(扩展到场景图生成)
我们使用两个不同的网络体系结构:VGG16和RESNET101在三个数据集上彻底基准测试代码:Pascal VOC,可可和视觉基因组。以下是结果:
1)。 Pascal VOC 2007(火车/测试:07TrainVal/07 -Test,比例= 600,ROI Align)
| 模型 | #GPU | 批量大小 | LR | lr_decay | max_epoch | 时间/时代 | mem/gpu | 地图 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1E-3 | 5 | 6 | 0.76小时 | 3265MB | 70.1 |
| VGG-16 | 1 | 4 | 4E-3 | 8 | 9 | 0.50小时 | 9083MB | 69.6 |
| VGG-16 | 8 | 16 | 1E-2 | 8 | 10 | 0.19小时 | 5291MB | 69.4 |
| VGG-16 | 8 | 24 | 1E-2 | 10 | 11 | 0.16小时 | 11303MB | 69.2 |
| RES-101 | 1 | 1 | 1E-3 | 5 | 7 | 0.88小时 | 3200 MB | 75.2 |
| RES-101 | 1 | 4 | 4E-3 | 8 | 10 | 0.60小时 | 9700 MB | 74.9 |
| RES-101 | 8 | 16 | 1E-2 | 8 | 10 | 0.23小时 | 8400 MB | 75.2 |
| RES-101 | 8 | 24 | 1E-2 | 10 | 12 | 0.17小时 | 10327MB | 75.1 |
2)。可可(火车/测试:Coco_train+Coco_val-Minival/Minival,Scale = 800,Max_size = 1200,ROI Align)
| 模型 | #GPU | 批量大小 | LR | lr_decay | max_epoch | 时间/时代 | mem/gpu | 地图 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1E-2 | 4 | 6 | 4.9小时 | 7192 MB | 29.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 6 | 6.0小时 | 10956 MB | 36.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 10 | 6.0小时 | 10956 MB | 37.0 |
笔记。由于上述模型使用比例= 800,因此您需要在test命令末尾添加“ -ls”。
3)。可可(火车/测试:Coco_train+Coco_val-Minival/Minival,Scale = 600,Max_size = 1000,ROI Align)
| 模型 | #GPU | 批量大小 | LR | lr_decay | max_epoch | 时间/时代 | mem/gpu | 地图 |
|---|---|---|---|---|---|---|---|---|
| RES-101 | 8 | 24 | 1E-2 | 4 | 6 | 5.4小时 | 10659 MB | 33.9 |
| RES-101 | 8 | 24 | 1E-2 | 4 | 10 | 5.4小时 | 10659 MB | 34.5 |
4)。视觉基因组(火车/测试:vg_train/vg_test,比例= 600,max_size = 1000,ROI Align,类别= 2500)
| 模型 | #GPU | 批量大小 | LR | lr_decay | max_epoch | 时间/时代 | mem/gpu | 地图 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1E-3 | 5 | 20 | 3.7小时 | 12707 MB | 4.4 |
感谢Remi在视觉基因组上提供了验证的检测模型!
首先,克隆代码
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
然后,创建一个文件夹:
cd faster-rcnn.pytorch && mkdir data
pascal_voc 07+12 :请按照py-faster-rcnn中的说明准备VOC数据集。实际上,您可以参考任何其他人。下载数据后,在文件夹数据/中创建软链接。
可可:还请遵循PY-FASTER-RCNN中的说明来准备数据。
视觉基因组:请按照自下而上的注意说明准备视觉基因组数据集。您需要首先下载图像和对象注释文件,然后执行必要条件,以根据此存储库中提供的脚本获得词汇和清洁注释。
我们在VGG和Resnet101的实验中使用了两个验证的模型。您可以从:
VGG16:Dropbox,VT服务器
Resnet101:Dropbox,VT服务器
下载它们并将它们放入数据/预处理_model/。
笔记。我们比较了Pytorch和Caffe的预算模型,令人惊讶的是,发现咖啡馆预读的模型的性能略高于预计的Pytorch。我们建议使用上述链接中的Caffe预估计模型来重现我们的结果。
如果您想使用Pytorch预训练的模型,请记住将图像从BGR转移到RGB,并使用与预读的模型中使用的相同数据变压器(减去平均值和正常化)。
正如Ruotianluo/pytorch-faster-rcnn指出的那样,请选择make.sh文件中的正确-arch ,以编译CUDA代码:
| GPU模型 | 建筑学 |
|---|---|
| Titanx(Maxwell/Pascal) | SM_52 |
| GTX 960m | SM_50 |
| GTX 1080(TI) | SM_61 |
| GRID K520(AWS G2.2XLARGE) | SM_30 |
| 特斯拉K80(AWS P2.xlarge) | SM_37 |
有关设置体系结构的更多详细信息,请参见此处或此处
使用PIP安装所有Python依赖性:
pip install -r requirements.txt
使用以下简单命令来编译CUDA依赖性:
cd lib
sh make.sh
它将编译您需要的所有模块,包括NMS,ROI_POOING,ROI_ALIGN和ROI_CROP。默认版本使用Python 2.7编译,如果您使用的是其他Python版本,请自己编译。
正如本期所指出的那样,如果您在编译过程中遇到某些错误,则可能会错过将CUDA路径导出到您的环境中。
在培训之前,请设置正确的目录,以保存和加载训练有素的模型。更改trainval_net.py和test_net.py中的参数“ save_dir”和“ load_dir”以适应您的环境。
要使用pascal_voc上的VGG16训练更快的R-CNN型号,只需运行:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
其中“ bs”是默认1的批处理大小。或者,要在pascal_voc上使用resnet101训练,简单运行:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
上面,可以根据您的GPU内存大小自适应设置batch_size和worker_number。在带有12G内存的Titan XP上,它最多可达4 。
如果您有多个(例如8)Titan XP GPU,请全部使用!尝试:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
如果您想对可可或视觉基因组进行训练,将数据集更改为“可可”或“ VG”。
如果您想评估Pascal_Voc测试集中预训练的VGG16模型的检测性能,只需运行
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
指定特定的模型会话,Checkepoch和检查点,例如,会话= 1,Epoch = 6,检查点= 416。
如果您想使用预训练的型号在自己的图像上运行检测
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
然后,您将在文件夹$ root/images中找到检测结果。
请注意默认示例仅支持Pascal_Voc类别。您需要更改行以调整自己的模型。
以下是一些检测结果:
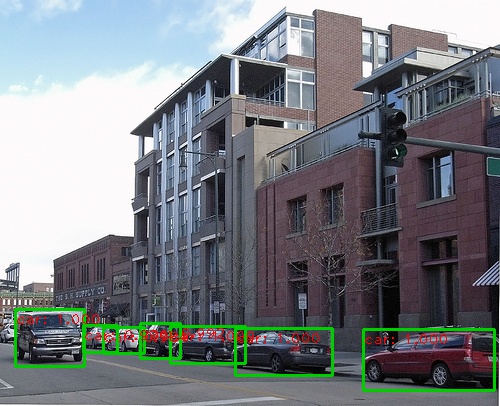

您可以通过运行在实时演示中使用网络摄像头
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
通过单击图像窗口,然后按“ Q”键来停止演示。
该项目同样由Jianwei Yang和Jiasen Lu以及许多其他项目(感谢它们!)。
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


