faster rcnn.pytorch
1.0.0
[29/05/2020] Este repositório foi iniciado há cerca de dois anos, desenvolvido como o primeiro código de detecção de objetos de código aberto que suporta treinamento multi-GPU. Ele tem integrado tremendos esforços de muitas pessoas. No entanto, vimos muitos repositórios de alta qualidade surgiram nos últimos anos, como:
Nesse ponto, acho que esse repositório está fora de data em termos de pipeline e estilo de codificação e não manterá ativamente. Embora você ainda possa usar esse repositório como um playground, eu recomendo que você se mude para os repositórios acima para mergulhar no mundo oeste da detecção de objetos!
Este projeto é uma implementação Pytorch mais rápida de R-CNN mais rápido, com o objetivo de acelerar o treinamento de modelos de detecção de objetos R-CNN mais rápidos. Recentemente, existem várias boas implementações:
rbgirshick/py-fre-rcnn, desenvolvido com base em pycaffe + numpy
Longcw/Faster_rcnn_pytorch, desenvolvido com base em Pytorch + Numpy
Endernewton/TF-FASTER-RCNN, desenvolvido com base no TensorFlow + Numpy
Ruotianluo/Pytorch-Faster-Rcnn, desenvolvido com base em pytorch + tensorflow + numpy
Durante nossa implementação, encaminhamos as implementações acima, especialmente o LONGCW/FASTER_RCNN_PYTORCH. No entanto, nossa implementação possui vários recursos exclusivos e novos em comparação com as implementações acima:
É um código pytorch puro . Convertemos todas as implementações Numpy em Pytorch!
Ele suporta treinamento em lote de várias imagens . Revisamos todas as camadas, incluindo Dataloader, RPN, ROI-Pooling etc., para suportar várias imagens em cada minibatch.
Ele suporta o treinamento de GPUs múltiplos . Utilizamos um invólucro GPU múltiplo (nn.dataparalla aqui) para tornar flexível usar uma ou mais GPUs, como um mérito dos dois recursos acima.
Ele suporta três métodos de pool . Integramos três métodos de pool: ROI Pooing, ROI Align e ROI Crop. Mais importante, modificamos todos eles para oferecer suporte ao treinamento em lote de várias imagens.
É eficiente em memória . Limitamos a proporção da imagem e as imagens em grupo com proporções semelhantes em um minibatch. Como tal, podemos treinar Resnet101 e VGG16 com BatchSize = 4 (4 imagens) em um único Titan X (12 GB). Ao treinar com 8 GPU, o tamanho máximo de lotes para cada GPU é 3 (res101), totalizando 24.
É mais rápido . Com base nas modificações acima, o treinamento é muito mais rápido. Relatamos a velocidade de treinamento no NVIDIA Titan XP nas tabelas abaixo.
Rede de Pirâmide Recurso (FPN)
Máscara r-cnn ( em andamento já implementado por roytseng-tw)
Gráfico R-CNN (extensão para geração de gráficos de cena)
Realizamos minuciosamente nosso código em três conjuntos de dados: Pascal Voc, Coco e Visual Genome, usando duas arquiteturas de rede diferentes: VGG16 e Resnet101. Abaixo estão os resultados:
1). Pascal voc 2007 (trem/teste: 07TrainVal/07Test, Scale = 600, ROI Align)
| modelo | #GPUS | Tamanho do lote | lr | LR_DECAY | max_epoch | tempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1e-3 | 5 | 6 | 0,76 hr | 3265MB | 70.1 |
| VGG-16 | 1 | 4 | 4E-3 | 8 | 9 | 0,50 hr | 9083MB | 69.6 |
| VGG-16 | 8 | 16 | 1e-2 | 8 | 10 | 0,19 hr | 5291MB | 69.4 |
| VGG-16 | 8 | 24 | 1e-2 | 10 | 11 | 0,16 hr | 11303MB | 69.2 |
| Res-101 | 1 | 1 | 1e-3 | 5 | 7 | 0,88 hr | 3200 MB | 75.2 |
| Res-101 | 1 | 4 | 4E-3 | 8 | 10 | 0,60 hr | 9700 MB | 74.9 |
| Res-101 | 8 | 16 | 1e-2 | 8 | 10 | 0,23 hr | 8400 MB | 75.2 |
| Res-101 | 8 | 24 | 1e-2 | 10 | 12 | 0,17 hr | 10327MB | 75.1 |
2). Coco (trem/teste: coco_train+coco_val-minival/minival, escala = 800, max_size = 1200, ROI alinhado)
| modelo | #GPUS | Tamanho do lote | lr | LR_DECAY | max_epoch | tempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1e-2 | 4 | 6 | 4,9 hr | 7192 MB | 29.2 |
| Res-101 | 8 | 16 | 1e-2 | 4 | 6 | 6,0 hr | 10956 MB | 36.2 |
| Res-101 | 8 | 16 | 1e-2 | 4 | 10 | 6,0 hr | 10956 MB | 37.0 |
OBSERVAÇÃO . Como os modelos acima usam escala = 800, você precisa adicionar "--LS" no final do comando de teste.
3). Coco (trem/teste: coco_train+coco_val-minival/minival, escala = 600, max_size = 1000, ROI alinhado)
| modelo | #GPUS | Tamanho do lote | lr | LR_DECAY | max_epoch | tempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| Res-101 | 8 | 24 | 1e-2 | 4 | 6 | 5,4 hr | 10659 MB | 33.9 |
| Res-101 | 8 | 24 | 1e-2 | 4 | 10 | 5,4 hr | 10659 MB | 34.5 |
4). Genoma Visual (trem/teste: vg_train/vg_test, escala = 600, max_size = 1000, ROI Align, categoria = 2500)
| modelo | #GPUS | Tamanho do lote | lr | LR_DECAY | max_epoch | tempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1e-3 | 5 | 20 | 3,7 hr | 12707 MB | 4.4 |
Agradecemos a Remi por fornecer o modelo de detecção pré -treinamento no Genoma Visual!
Primeiro de tudo, clone o código
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
Em seguida, crie uma pasta:
cd faster-rcnn.pytorch && mkdir data
Pascal_voc 07+12 : Siga as instruções no PY-FASTER-RCNN para preparar os conjuntos de dados VOC. Na verdade, você pode se referir a qualquer outro. Depois de baixar os dados, crie o SoftLinks nos dados da pasta/.
Coco : Siga também as instruções no PY-FASTER-RCNN para preparar os dados.
Genoma Visual : siga as instruções em atendimento de baixo para cima para preparar o conjunto de dados do Genoma Visual. Você precisa baixar os arquivos de anotação de imagens e objetos primeiro e depois executar a propriedade para obter o vocabulário e as anotações limpas com base nos scripts fornecidos neste repositório.
Utilizamos dois modelos pré -gravados em nossos experimentos, VGG e Resnet101. Você pode baixar esses dois modelos de:
VGG16: Dropbox, VT Server
Resnet101: Dropbox, VT Server
Faça o download e coloque -os nos dados/pré -tereado_model/.
OBSERVAÇÃO . Comparamos os modelos pré -treinados de Pytorch e Caffe, e surpreendentemente descobrimos que os modelos pré -traidos com caffe têm um desempenho um pouco melhor do que o pytorch pré -treinado. Sugerimos usar modelos de cafe pré -terenciados do link acima para reproduzir nossos resultados.
Se você deseja usar modelos pré-treinados do Pytorch, lembre-se de transpor imagens de BGR para RGB e também use o mesmo transformador de dados (média e normalizar), conforme usado no modelo pré-traçado.
Como apontado por Ruotianluo/Pytorch-Fester-RCNN, escolha o arquivo certo -arch in make.sh , para compilar o código CUDA:
| Modelo de GPU | Arquitetura |
|---|---|
| Titanx (Maxwell/Pascal) | SM_52 |
| GTX 960M | SM_50 |
| GTX 1080 (TI) | SM_61 |
| Grid K520 (AWS G2.2XLARGE) | SM_30 |
| Tesla K80 (AWS P2.XLARGE) | SM_37 |
Mais detalhes sobre a definição da arquitetura podem ser encontrados aqui ou aqui
Instale todas as dependências do Python usando o PIP:
pip install -r requirements.txt
Compilar as dependências do CUDA usando os seguintes comandos simples:
cd lib
sh make.sh
Ele compilará todos os módulos que você precisa, incluindo NMS, ROI_POOING, ROI_ALIGN e ROI_CROP. A versão padrão é compilada com o Python 2.7, compilar sozinho se estiver usando uma versão Python diferente.
Como apontado nesta questão, se você encontrar algum erro durante a compilação, poderá perder a exportação dos caminhos do CUDA para o seu ambiente.
Antes de treinar, defina o diretório certo para salvar e carregar os modelos treinados. Altere os argumentos "Save_Dir" e "load_dir" em trenval_net.py e test_net.py para se adaptar ao seu ambiente.
Para treinar um modelo R-CNN mais rápido com VGG16 em Pascal_voc, basta executar:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
onde 'bs' é o tamanho do lote com o padrão 1. Alternativamente, para treinar com resnet101 em Pascal_voc, execução simples:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
Acima, Batch_size e Worker_Number podem ser definidos de forma adaptativa de acordo com o tamanho da memória da GPU. No Titan XP com memória 12G, pode ser de até 4 .
Se você tem vários (digamos 8) GPUs Titan XP, basta usar todos eles! Tentar:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
Altere o conjunto de dados para "Coco" ou 'VG' se você quiser treinar no Coco ou no Genome Visual.
Se você deseja avaliar o desempenho de detecção de um modelo VGG16 pré-treinado no conjunto de testes Pascal_voc, basta executar
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
Especifique a sessão de modelo específica, checkepoch e ponto de verificação, por exemplo, sessão = 1, epoch = 6, ponto de verificação = 416.
Se você deseja executar a detecção em suas próprias imagens com um modelo pré-treinado, faça o download do modelo pré-treinado listado nas tabelas acima ou treine seus próprios modelos no início, adicione imagens à pasta $ raiz/imagens e depois execute
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
Em seguida, você encontrará os resultados da detecção na pasta $ raiz/imagens.
Observe a Demo.py padrão apenas suporta categorias Pascal_voc. Você precisa alterar a linha para adaptar seu próprio modelo.
Abaixo estão alguns resultados de detecção:
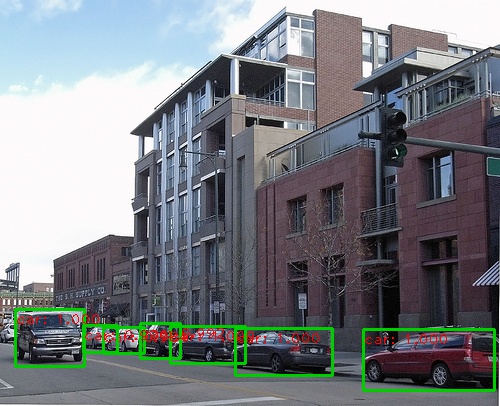

Você pode usar uma webcam em uma demonstração em tempo real executando
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
A demonstração é interrompida clicando na janela da imagem e pressionando a tecla 'Q'.
Este projeto é igualmente contribuído por Jianwei Yang e Jiasen Lu e muitos outros (graças a eles!).
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


